
最近,AI 的进步有目共睹,现在这些进步已经开始传递到机器人领域。强大的 AI 技术也能帮助机器人更好地理解其所处的物理世界并采取更合理的行动。
近日,UC 伯克利 BAIR 实验室的 Sergey Levine 研究团队提出了一个强化学习框架 HIL-SERL,可直接在现实世界中训练通用的基于视觉的机器人操作策略。HIL-SERL 的表现堪称前所未有的卓越,仅需 1-2.5 小时的训练就能在所有任务上实现 100% 的成功率。要知道,基线方法的平均成功率还不到50%。就算有外部干扰,机器人也能取得很好的表现。

论文一作 Jianlan Luo 的推文,他目前正在 UC 伯克利 BAIR 实验室从事博士后研究

团队导师 Sergey Levine 也发了推文宣传这项研究,他是一位非常著名的 AI 和机器人研究科学家,曾是 2021 年发表相关论文最多的研究者,参阅机器之心报道《2021 年 ML 和 NLP 学术统计:谷歌断层第一,强化学习大牛 Sergey Levine 位居榜首》
空口无凭,眼见为实,那就先让机器人来煎个蛋吧。

在主板上安装一块固态硬盘?机器人也能与人类搭配,轻松完成。

插入 USB,问题也不大,看起来比人执行这个操作还流畅,毕竟很多人插 USB 都要对准两三次才能成功。

这么好的效果,不禁让人怀疑,这不会是远程操控吧?Nonono!这些任务都是机器人独立完成的,这次人类的角色也不是站在身后发号施令,而是在它旁边捣乱。
对于没有独立思考能力的机器人来说,任务执行起来那是相当死板。一旦目标物体换了一个位置,它们就会迷失方向。但对于采取 HIL-SERL 框架的机器人,就算你强行夺走它手中这根 USB 线,它依然能自动定位,重新完成任务。

机器人如何变得如此厉害?下面我们就来看看 UC 伯克利的这项研究。

论文标题:Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning
论文地址:https://hil-serl.github.io/static/hil-serl-paper.pdf
项目地址:https://hil-serl.github.io/
简而言之,他们设计了一个有人类参与的强化学习框架。在此之前,基于强化学习的技术已经为机器人领域带来了一些技术突破,使机器人已经能够熟练地处理一些简单任务。但是,真实世界环境非常动态多变,而且非常复杂,如果能开发出某种基于视觉的通用方法,必定有助于机器人掌握更加复杂的技能。
这正是该团队做出贡献的地方,他们开发的基于视觉的强化学习系统可以让机器人掌握大量不同的机器人技能。
他们将该系统命名为 Human-in-the-Loop Sample-Efficient Robotic Reinforcement Learning,即有人类参与的样本高效型机器人强化学习,简称 HIL-SERL。
为了解决优化稳定性问题,他们采用了预训练的视觉主干网络来实现策略学习。
为了处理样本复杂性问题,他们利用了基于 RLPD 的样本高效型离策略强化学习算法,该算法还结合了人工演示和校正。
此外,为了确保策略训练期间的安全性,他们还纳入了一个精心设计的低级控制器。
在训练时,该系统会向人类操作员询问潜在的校正,然后以离策略的方式使用这些校正来更新策略。他们发现,这种有人类参与的校正程序可让策略从错误中学习并提高性能,尤其是对于这项研究中考虑的一些难以从头开始学习的任务。
如图 1 所示,该系统可解决的任务纷繁多样,包括动态翻转平底锅中的物体、从积木塔中抽出一块积木、在两个机器臂之间递交物体以及使用一个或两个机械臂组装复杂的设备,例如计算机主板、宜家置物架、汽车仪表板或正时皮带。

这些任务复杂而精细,有着动态且高维的动作空间。之前一些研究者甚至认为无法通过强化学习来学习其中一些技能,但 BAIR 这个团队的研究证否了这个说法。
研究和实验表明,他们的系统能在相当短的时间(1-2.5 小时)内在所有这些任务上都实现几近完美的成功率。
使用同样数量的人类数据(演示和校正的数量)时,他们训练的策略远胜过模仿学习方法 —— 成功率平均超过 101%,周期时间平均快 1.8 倍。
这是个具有重大意义的结果,因为其表明强化学习确实可以直接在现实世界中,使用实际可行的训练时间学会大量不同的基于视觉的复杂操作策略。而之前的强化学习方法无法做到这一点。此外,强化学习还能达到超越人类的水平,远远胜过模仿学习和人工设计的控制器。
下面展示了一个超越人类水平的有趣示例:用一根鞭子将一块积木抽打出去,同时保证积木塔整体稳定。很显然,这个任务对大多数人来说都非常困难,但这台机器人通过强化学习掌握了这一技能。

系统概况
HIL-SERL 系统由三个主要组件组成:actor 过程、learner 过程和位于 learner 过程中的重放缓存。它们都能以分布式的方式运行,如图 2 所示。

actor 过程与环境交互的方式是在机器人上执行当前策略,并将数据发送回重放缓存。
环境采用了模块化设计,允许灵活配置各种设备,包括支持多个摄像头、集成 SpaceMouse 等用于远程操作的输入设备。
为了评估任务是否成功,也需要一个奖励函数,而该奖励函数是使用人类演示离线训练的。
在 actor 过程中,人类可使用 SpaceMouse 从强化学习策略接管机器人的控制权,从而干预机器人的行动。
该团队采用了两种重放缓存,一种是为了存储离线的人类演示(演示缓存),另一种则是为了存储在策略数据(RL 缓存)。
learner 过程会从演示缓存和 RL 缓存平等地采样数据,使用 RLPD 优化策略,并定期将更新后的策略发送到 actor 进程。
详细的系统设计选择这里不再赘述,请访问原论文。
有人类参与的强化学习
此前,强化学习理论 (Jin et al., 2018; 2020; Azar et al., 2012; Kearns and Singh, 1998) 已经证明了智能体能学会的难度和它要处理的信息量密切相关。具体来说,状态 / 动作空间的大小、任务的难度,这些变量不断累加,会导致智能体在找到最优策略时所需的样本成倍增加。最终在超过某个阈值时,所需要的样本量过多,智能体实在学不动了,摆烂了,在现实世界中训练 RL 策略也变得不切实际。
为了解决用强化学习训练真实机器人策略的难题,该团队研究后发现,人类反馈很好用 —— 可以引导学习过程,实现更高效的策略探索。具体来说,就是在训练期间监督机器人,并在有必要时进行干预,纠正其动作。如上图 2 所示。
在该系统的设计中,干预数据会被同时存储在演示缓存和 RL 缓存中,但仅有 RL 缓存带有策略转移(即干预前后的状态和动作)。事实证明,这种方法可以提升策略的训练效率。
这种干预在以下情况下至关重要:
在训练过程的开始阶段,人类会更频繁地干预以提供正确动作,随着策略的改进,频率会逐渐降低。根据该团队的经验,相比于让机器人自行探索,当人类操作员给出具体的纠正措施时,策略改进速度会更快。

研究团队放出了任务训练过程的完整录像
更具体的训练过程请访问原论文。
研究团队选择了七个任务来测试 HIL-SERL。这些任务对应着一系列挑战,比如操纵动态物体(在平底锅中翻煎蛋)、精确操作(插 USB 线)、动态和精确操作相结合(在主板移动时插入组件)、操纵柔性物体(组装正时皮带)、包含多个子任务的多阶段任务(组装宜家书架)。
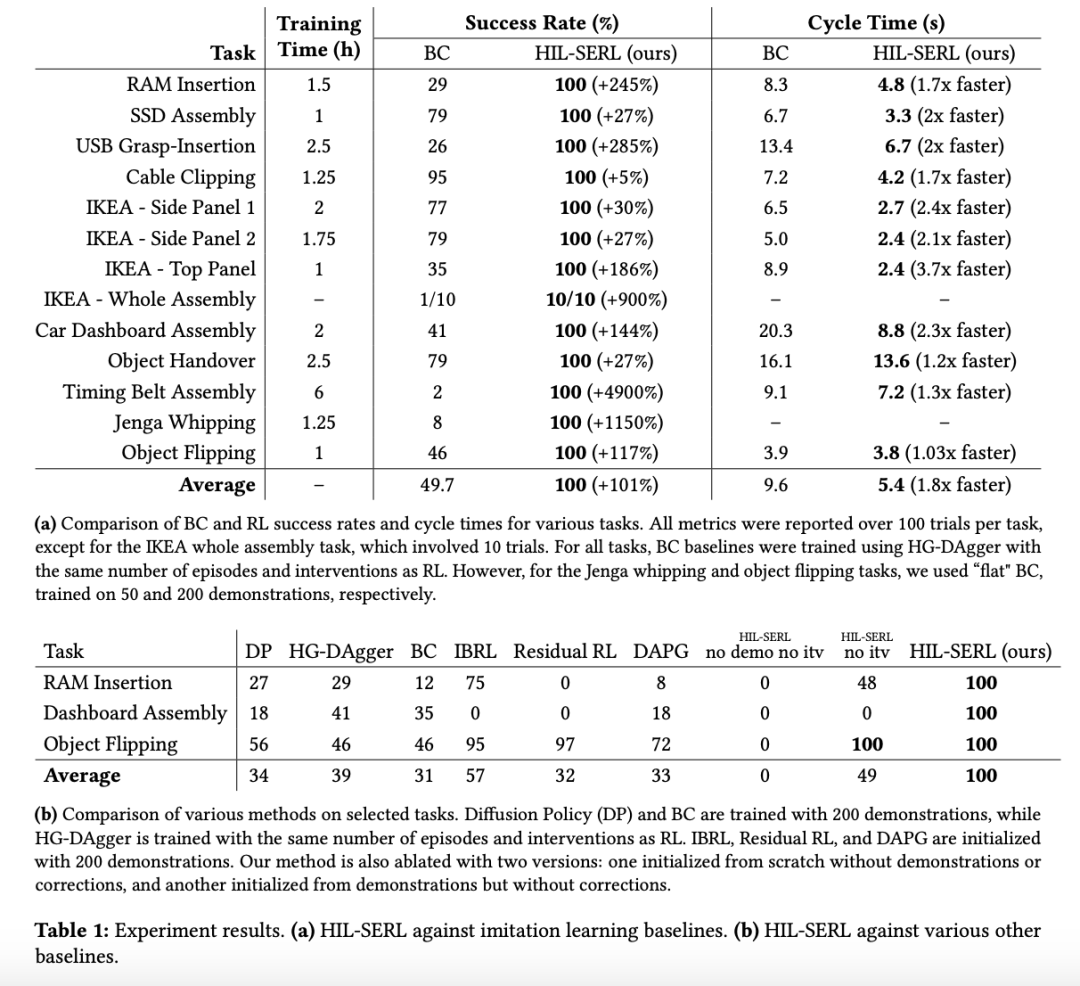
如上表所示,在几乎所有任务上,HIL-SERL 在 1 到 2.5 小时的真实世界训练里达到了 100% 的成功率。这比基线方法 HG-DAgger 的平均成功率 49.7% 有了显著提高。对于抽积木、插入 RAM 条等,这种更复杂的任务,HIL-SERL 的优势就更为明显了。
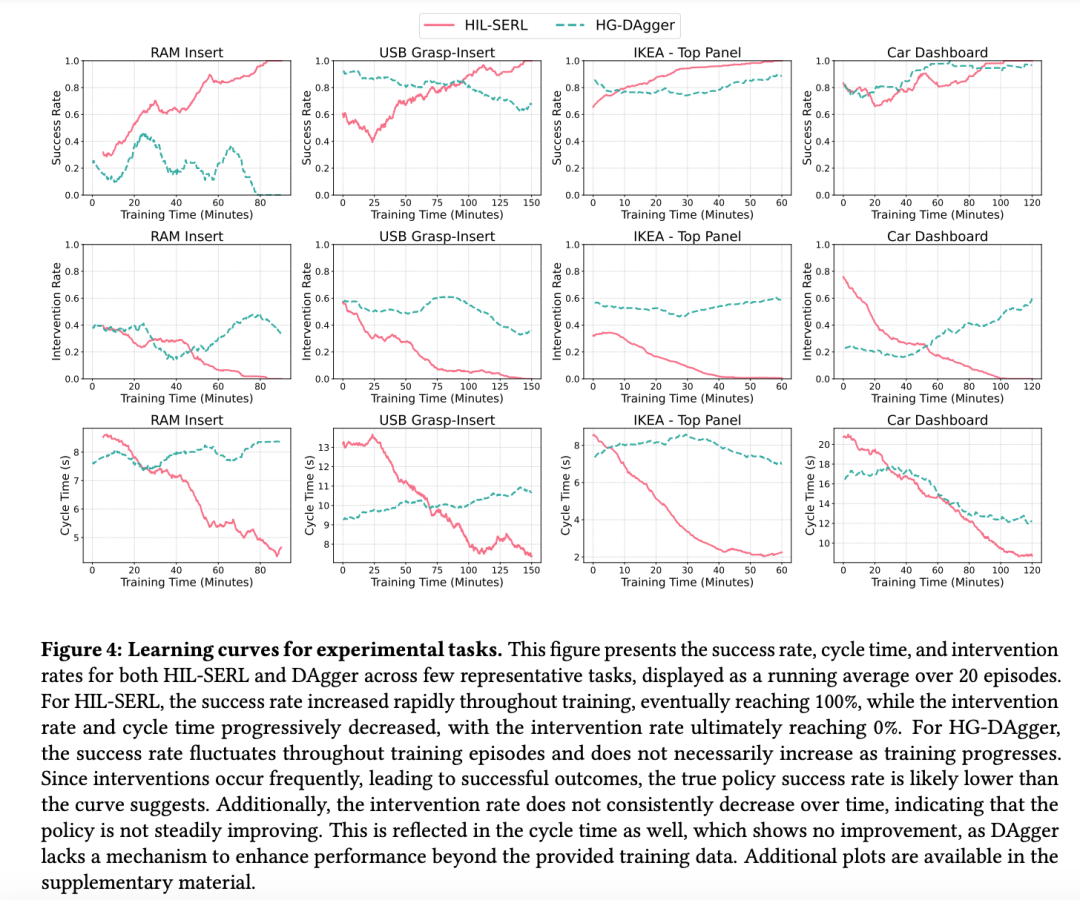
上图中显示了采用 HIL-SERL 方法的机械臂在执行任务时被人工干预的次数。为了便于统计,研究团队计算了每次干预的时步数与单次尝试中的总时步数之比(干预率),并统计了 20 次实验的动态平均值。从图表中不难看出,干预率随着训练逐渐降低。这表明 HIL-SERL 策略会不断优化,越来越不需要人类操心了。
同时,人工干预的总时长也大幅度减少。策略不成熟时,机械臂犯错,需要花较长时间纠正,随着 HIL-SERL 不断完善,较短的干预就足以减少错误。相比之下,HG-DAgger 需要更频繁的干预,亦不会因为策略逐渐完善减少犯错的次数。

上图展示了 HIL-SERL 的零样本鲁棒性。这证明新提出的策略能够让机器人灵活地适应即时变化,有效地处理外部干扰。
比如有人故意地松开了齿轮上的皮带,受 HIL-SERL 指导的两个机械臂,一个把皮带放回了原位,另一个配合着把滑轮恢复到了适当的位置。

在两个机械臂对接时,研究人员有意让其中一个机械臂「失误」,放开了手中的物体。在 HIL-SERL 的加持下,两个机械臂自主分工合作,又恢复了搬运物体的平衡。

参考链接:
https://x.com/jianlanluo/status/1850902348010557453
https://x.com/svlevine/status/1850934397090078948

扫描二维码添加小助手微信










