
第一部分 设计概述
1.1 设计目的
新冠病毒的肆虐让整个 2020 年笼罩在恐慌之中,戴口罩成了人们外出必备 的“新日常”。新冠病毒主要通过飞沫传播和接触传播,正确选择佩戴口罩,可有效阻隔病毒传播。但在人流量庞大的商圈、车站等场所,仍有许多人拒绝佩戴口罩。若能在这些场所进行当前人群口罩检测,则能有效避免冠状病毒的传播。
本作品是一种能实时检测识别人脸口罩佩戴情况并进行语音播报的系统,准确度高达 95.2%,系统处理速度可达 25fps 左右。除此之外,本作品具备较高的可拓展性,稍加更改就可在更多的领域得到应用。
1.2 应用领域
基于深度学习的人脸捕获及口罩检测系统可以适用于人流量大的场所,实现 了人脸检测与跟踪以及人脸口罩识别的功能,并将识别结果进行播报,可以辅助疫情防控工作的开展。
除此之外,本系统的人脸检测系统有着广泛的应用范围。
在智能家居领域,可以通过我们的系统实现人类闯入报警装置,在摄像头捕捉到的区域检测到人脸后触发报警;
在新冠疫情期间,我们的系统可以安装在商圈、旅游景点,实时检测人流密度,为实时限流措施提供参考。
1.3 主要技术特点
对密集人群进行口罩检测,首先要在画面中进行人脸检测。在非深度学习阶段的目标检测算法都是针对特定目标提出的,比如 CVPR 2001 的 Viola-Jones (VJ)[1]是针对人脸检测问题,CVPR 2005 的 HOG+SVM[2]是针 对行人检测问题,TPAMI 2010 的 DPM[3]虽然可以检测各类目标,但要用于多目标检测,需要每个类别分别训练模板。而强大的深度学习只要一个 CNN 就可以 搞定多类别检测任务。虽然这些都是多类别方法,但它们也都可以用来解决单类别问题。
本作品是基于深度学习的人脸捕获及口罩检测系统,通过片外的图像传感器采集图像到片上缓冲区,而后把图像送到 FPGA 上的神经网络加速器进行处理, 识别结果输出到显示器,在显示器中框出人脸并显示目标是否佩戴口罩,我们还使用语音模块对画面中的总人数和未戴口罩人数作出播报。
1.4 关键性能指标
本作品可以实时检测识别人脸口罩佩戴情况,我们从帧率和精度两个方面进行了分析。识别精度可达到 95.2%,而系统延迟仅仅 40ms 左右,可达到 25fps 的帧率。
1.5 主要创新点
神经网络部分创新点
1、使用了一个轻量级 backbone,去除了 BN 层,在精度达到优秀的前提下极大提升了速度;
2、去掉了 FPN 结构,仅降低微小的精度却大大提升了速度(20%);
3、在网络的 head 部分对边框回归和类别预测做了不对称设计,进一步提升性能。
系统框架创新点
1、为了加快系统设计,采用了 Xilinx 专用于卷积神经网络的深度学习处理单元(DPU)。在设计系统过程中,可根据系统的具体情况配置 DPU 的参数,将该 IP 集成到所选器件 PL 中,通过 PS 端软件控制,实现多种卷积神经网络的加速。
2、利用 PYNQ 框架,可以在开发板上动态地加载比特流实现系统所需硬件电路,灵活方便。
3、利用 Vitis AI 编译模型,将浮点模型转换为定点模型,降低了计算复杂度,并且需要的内存带宽更少,提高了模型速度。
第二部分 系统组成及功能说明
2.1 整体介绍
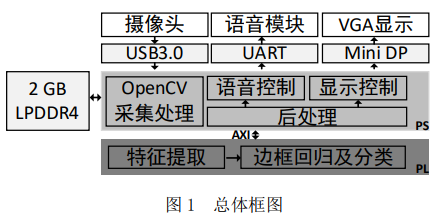
基于深度学习的人脸检测系统由 PS 端、PL 端与外设及其接口组成。其中, 外设包括、摄像头(通过 USB3.0 连接)、语音模块(通过 UART 连接)和 VGA 显示(通过 Mini DP 转 VGA 连接),开发板内部还提供了 2GB 的 LPDDR4;PS 端包括 openCV 采集处理模块、后处理模块、语音控制模块及显示控制模块;PL 端包括特征提取模块和边框回归及分类模块。在 PS 端的模块中,openCV 采集处理模块的主要功能是控制摄像头采集图像,并对 LPDDR4 中的图像进行预处理;后处理模块的主要功能是使用非极大值抑制(Non-Maximum Suppression, NMS)算法对候选区域进行筛选,得到合适的区域信息并统计画面中检测到的人脸总数;语音控制和显示控制驱动语音模块和摄像头构成结果展示部分,语音控制模块根据后处理模块的结果播报当前画面中的人脸数目,而显示控制模块根据 VGA 时序显示拍摄画面并框出人脸位置。PL 端中的特征提取模块对预处理后的图像进行计算,得到大小不同的区域,边框回归及分类模块处理这些区域,给出边框信息与分类结果。

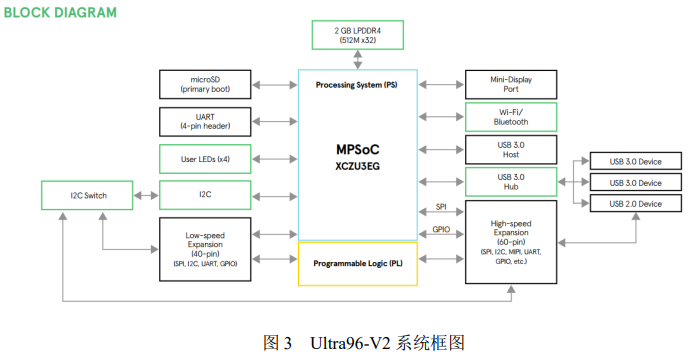
本系统的开发平台为 Ultra96-V2 开发板,是基于 FPGA 的 Xilinx Zynq UltraScale +MPSoC 开发板,并基于 Linaro 96Boards Consumer Edition(CE)规范构建。
Ultra96-V2 开发板系统框图如下图所示:
2.2 各模块介绍
OpenCV 采集处理

本系统采用的是超微 1601U 摄像头上图所示,输出图像大小为 1280×720, 最高帧率可达 30fps。该摄像头通过 USB3.0 接口与开发板连接,输出图像的数据格式支持 MJPEG 和 YUV 格式。它还支持自动曝光控制 AEC 和自动白平衡 AEB,可以调节亮度、对比度、色饱和度、色调等基础参数。
通过系统 PS 端的 OpenCV 来完成摄像头相关参数的配置以及图像帧的获取, 之后对获取的图像进行resize等预处理再送到PL部分的深度学习处理单元(DPU)进行处理。
后处理
对于一帧图像,该模块接收到来自神经网络检测模块的 3780 个候选框信息 (包括边框坐标、识别标签、置信度)。后处理模块首先对这些候选框进行筛选, 留下置信度大于 0.6 的候选框。这一步可以减少无效候选框的处理时间。接着, 我们使用非极大值抑制算法对通过筛选的候选框进行处理,去除重复的候选框, 得到最优结果。最后将结果输出给结果展示部分。
非极大值抑制,顾名思义就是抑制不是极大值的元素,可以理解为局部最大 搜索。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后, 每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到 NMS 来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
结果展示部分——语音控制
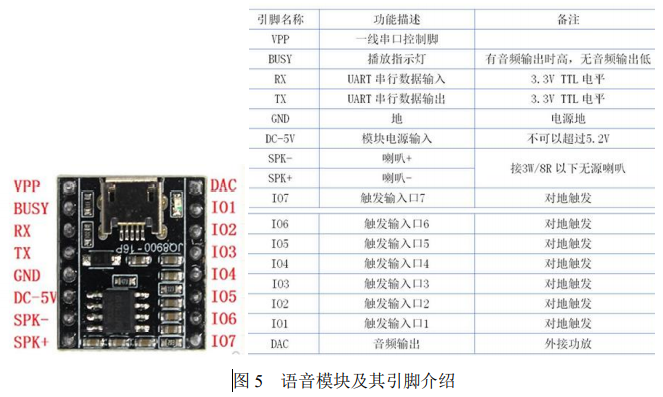
本系统中语音模块的功能是在系统检测完毕且后处理模块统计画面人数后, 将检测结果通过语音的方式播报给外界。语音模块 JQ8900-16P 选用了 SoC 方案, 集成了一个 16 位的 MCU,能够灵活更换 SPI-flash 内的语音内容,有一线串口控制模式和 RX232 串口控制模式可选。
由于开发板上有多个 USB 接口,我们采用 USB 转串口的方式来控制语音模块。具体控制方式为把检测到的人数转化为语音模块的控制指令,通过串口发送到该模块,语音模块对指令进行解码之后播报存放在该模块内的相应音频。
结果展示部分——显示控制
经过神经网络处理之后的图像由开发板上的 Mini DP 接口外接 Mini DP 转 VGA 转接头,连接到 VGA 显示器进行显示。
识别模块
本系统中卷积神经网络模块的功能是对摄像头采集图像中的人脸进行检测并判断目标人脸上是否佩戴口罩,是系统的核心模块。本小节将从数据集的制作、 特征提取模块、软件模型设计和硬件模型设计等四个方面介绍该模块。
(1)数据集的制作
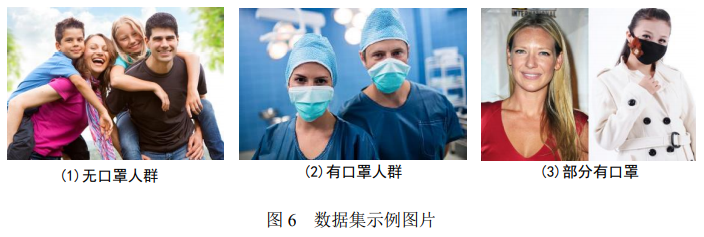
数据集主要来自于 WIDER Face 和 MAFA 数据集,加入了上百张戴口罩的 图片(来源于网络)。具体地,我们从 WIDER Face 中筛选出 7000 张,从 MAFA 中筛选出 2000 张,自己根据已有的戴口罩的数据集生成了 2000 张左右,最终分为训练集 13000 张,测试集 300 张。值得一提的是,在我们自己生成的数据集图片中,有许多是将有口罩的图片与无口罩的图片的组合,如图 6 最右所示,因为在经典数据集中很难找到这样的情况。
2)神经网络模型的搭建和训练
本系统采用的目标检测算法为 anchor-base 的 one-stage 算法,整个网络参考 了 RetinaNet[4]进行设计,可分为 backbone、neck、head 三大部分。其中,backbone 参考 BlazeFace[5]的设计去掉了 BN 层,这样能在不影响准确率的前提下提高速度。在 RetinaNet 的 neck 部分中,FPN[6]有很好的特征提取功能,引入 FPN 能解决较为复杂的问题。但由于 FPN 需要额外的卷积计算,它也在一定程度上降低了速度。由于本次应用只有两个类别,有口罩和无口罩,识别困难度比较低,我们参考了 SSD[7]的结构,去掉 FPN 部分,仅用一个卷积层调整通道。对于 head 部分, 由于只有两个类别,我们减少了 class 分支的卷积层,不再与 boxes 分支对称。减少卷积层并没有引起精度下降,但进一步提升了速度。
我们 anchor 设置如下:
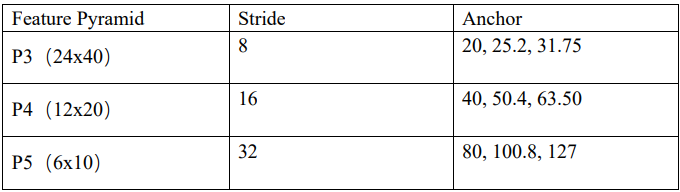
总共有(24×40+12×20+6×10)×3=3780 个 anchor,最小尺寸为 20,最大尺 寸为 127。
整体网络框架如下所示:
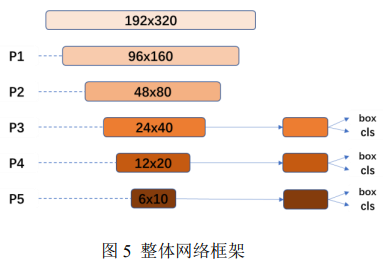
整体网络可分为两部分——特征提取模块与边框回归及分类模块。
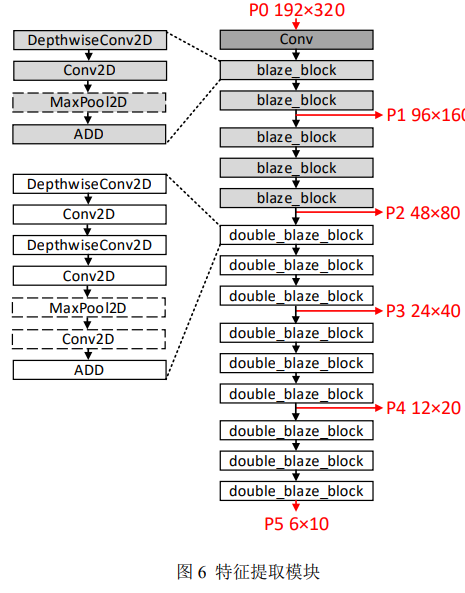
对于特征提取模块的处理如图 6 所示。令输入图像为 P0,其尺寸为 192×320;P1 由 P0 经过一个卷积层和两个 blaze_block 得到,P1 经过三个 blaze_block 得到 P2 ;P3 由 P2 经 过 三 个 double_blaze_block 得来, P4 由 P3 经过三个 double_blaze_block 得来,P5 由 P4 经过三个 double_blaze_block 得来。P3、P4 和 P5 是本模块的输出,即识别模块的输入。其中 blaze_block 由 DepthwiseConv2D + Conv2D + MaxPool2D + Add 组成,double_blaze_block 由 DepthwiseConv2D + Conv2D + DepthwiseConv2D + Conv2D + MaxPool2D + Conv2D + Add 组成。各层 参数详见本文附录中软件模型的源代码。
边框回归及分类模块对 P3、P4、P5 进行分析。RetinaNet 类别分支和边框分 支分别采用了四个卷积层,本设计采用了 RetinaNet 的 head 设计思想,但是进行 了改进:我们减少了卷积层的数量,边框分支采用三个卷积层,类别分支采用两个卷积层。因为只有两个类别,所以我们的类别分支和边框分支采用了不对称设计,将类别分支的卷积层进一步减少。减少类别分支的卷积层对准确率几乎没有影响,但提升了速度。
(3)硬件部分
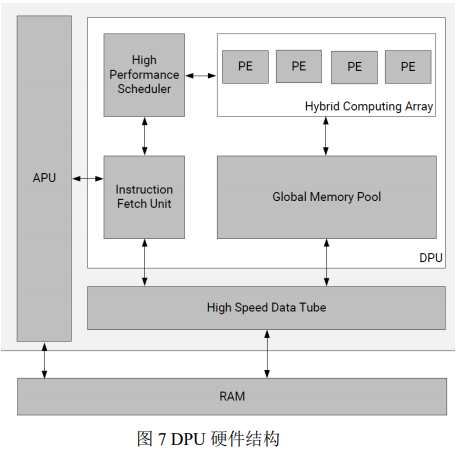
该部分利用支持 PYNQ 框架的开发板镜像。首先通过在开发板上加载带 Xilinx 的 DPU IP 的比特流文件,把 DPU 烧写到开发板的 PL 端;再通过安装在开发板镜像上的 DPU 驱动,调用相应的 API 把经过 Vitis AI 编译过的模型部署到 DPU 中;最后启动 DPU 读取预处理之后的图像进行检测和分类,DPU 运算完之后取出运算结果,对运算结果进行解析之后得到人脸框的坐标以及是否佩戴口罩的分类结果。
第三部分 完成情况及性能参数
3.1 完成情况

本系统目前可以实现:
人脸检测框上方给出目标是否戴口罩 mask/nomask 以及置信度;

3.2 人脸检测性能指标

本系统基于人脸捕捉及口罩识别的应用对 RetinaNet 进行优化,并利用硬件加速,大大提升了处理速度。目前该系统可对 192×320 大小的三通道彩色视频进行实时处理,帧率可达 25fps,精度可达 95.2%。
第四部分 总结
可扩展之处
目前系统图像采集时间占总体时间的比例比较大,后期可探索更多软硬件优化的方法对图像采集部分进行优化,提升系统帧率。除此之外,目前我们的应用是进行口罩(人脸)的检测,未来可在此基础上进行拓展加入识别模型,识别模型可以精确识别出是哪一个人,这样可将应用范围进一步拓展,比如说门禁的人脸识别、签到、智能监控等等。
文章来源于FPGA技术江湖,作者The last one











