1. 基于 AI 的答案引擎
2. 葫芦 AI:在国内使用 4 个知名大模型
3. 本地知识库问答
4. 媒体平台爬虫
01
基于 AI 的答案引擎
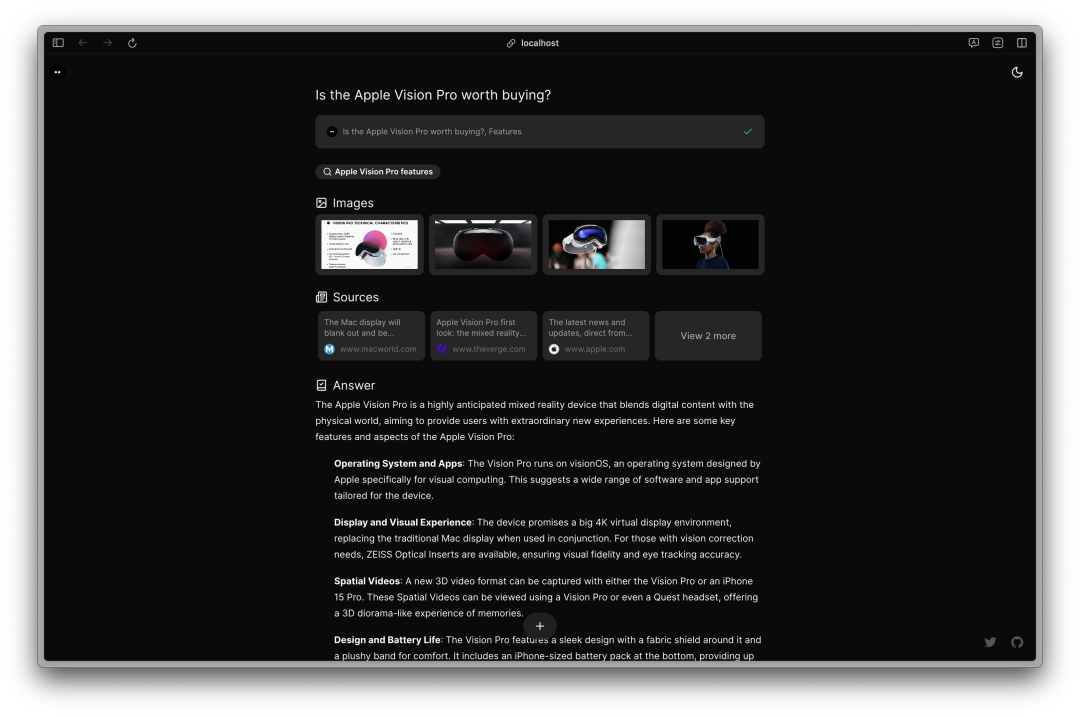
Morphic 是一个由 AI 驱动的答案引擎,利用了大模型技术为用户提供了一个动态、互动的问答体验。通过结合强大的 AI 模型和直观的用户界面,提供一个全新的信息检索和交互方式。用户可以通过自然语言与系统交互,获取定制化的答案和解决方案。- 应用框架: Next.js、文本流/生成性 UI: Vercel AI SDK
- 生成模型: OpenAI、搜索 API: Tavily AI
- 组件库: shadcn/ui、无头组件原语: Radix UI、样式: Tailwind CSS
开源地址:https://github.com/miurla/morphic
02
这个不是开源项目哈,是一个不错的免费试用推荐。
主流的 AI 模型,目前都是收费制。如果想试用下面这 4 个模型会花不少钱,并且使用的过程也比较坎坷。
GPT-4:20美元/月
文心一言:49.9元人民币/月
Midjourney V6.0:10美元/月
DALL-E:每张图片0.02美元
国内新出的“葫芦 AI”(HuLu AI)在同一个界面提供上面四个模型的访问,相当于“四合一”的国内镜像。
03
本地知识库问答
QAnything 是由网易有道团队开发的一个本地知识库问答系统,旨在支持广泛的文件格式和数据库,允许离线安装和使用。该项目的核心特点包括数据安全、跨语言问答支持、支持大规模数据问答、高性能的生产级系统以及用户友好的一键安装和部署。支持在整个过程中拔掉网络线进行安装和使用,无论文档的语言如何,都可以自由切换中英文问答。采用两阶段检索排名,解决大规模数据检索的性能下降问题;数据越多,性能越好。可选择多个知识库进行问答。QAnything 采用两阶段检索方法,以应对大量知识库数据的场景。在数据量增加时,单阶段嵌入检索会存在检索性能下降的问题。通过第二阶段的重排,可以稳定提高准确率,实现数据越多性能越好的效果。QAnything 使用的检索组件 BCEmbedding,擅长中英文语言差异的桥接,在语义表示评估和RAG评估中表现出色。开源地址:https://github.com/netease-youdao/QAnything
04
媒体平台爬虫
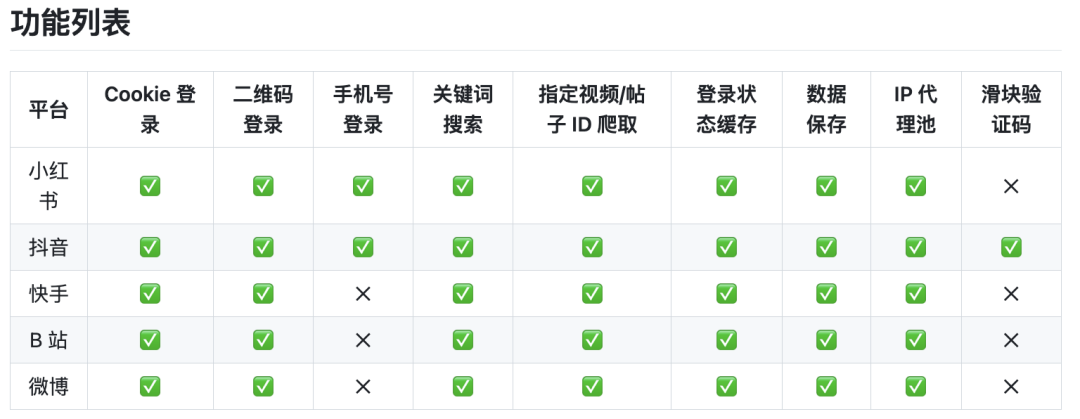
MediaCrawler 由开发者 NanmiCoder 创建和维护。该项目是一个开源的媒体内容爬虫工具集,专注于从多个流行的社交媒体和内容平台上抓取数据,特别是针对小红书笔记、抖音视频、快手视频、B站视频和微博帖子的评论信息。多平台支持:包括但不限于小红书、抖音、快手、B站和微博。评论抓取:该项目主要关注于抓取用户的评论信息,这对于市场研究、舆论监控和数据分析等方面非常有用。开源地址:https://github.com/NanmiCoder/MediaCrawler
---END---








