【导读】贾佳亚团队提出VLM模型Mini-Gemini,堪比GPT-4+DALL-E 3王炸组合,一上线就刷爆了多模态任务榜单!读得懂梗图,做得了学术,用代码就能复现数学函数图。
刷爆多模态任务榜单,超强视觉语言模型Mini-Gemini来了!效果堪称是开源社区版的GPT-4+DALL-E 3王炸组合。不仅如此,这款由港中文终身教授贾佳亚团队提出的多模态模型,一经发布便登上了PaperWithCode热榜。Demo地址: http://103.170.5.190:7860/
论文地址:https://arxiv.org/pdf/2403.18814.pdf具体来说,Mini-Gemini提供了2B小杯到34B的超大杯的不同选择。凭借超强的图文理解力,Mini-Gemini在多个指标上,直接媲美Gemini Pro,GPT-4V。目前,研究团队将Mini-Gemini的代码、模型、数据全部开源。更有意思的是,超会玩梗的Mini-Gemini线上Demo已经发布,人人皆可上手试玩。Mini-Gemini Demo放出后受到广大网友关注,一番「尝鲜」后,有人认为:Mini-Gemini跟商业模型差不了多少!
当前,绝大多数多模态模型仅支持低分辨率图像输入和文字输出。而在实际场景中,许多任务都需要对高清图像进行解析,并用图像的形式进行展现。举个例子,Mini-Gemini能够看懂面包九宫格图片教程,并进行手把手教学。拍一张苹果店Mac电脑信息图,Mini-Gemini能够将两种尺寸的Mac不同参数进行对比。有网友看过后表示,「妈妈再也不用担心我的生活了」。更重要的是,Mini-Gemini在保留超强的图像理解和推理能力的同时,还解锁了图像的生成能力,就如同ChatGPT和生成模型的结合。推理再生成,更精准了
当用户给出两个毛线团并问出能用它们做什么时,Gemini可以识别出图片内容并给出相应的建议。

当我们把相似的输入给到Mini-Gemini,它会怎么回答呢?可以发现,Mini-Gemini也可以识别出图片中的元素,并且合理地建议,同时生成了一只对应的毛线小熊。通过一些抽象的多模态指令来让模型给出推理,并生成合适的图片,这个操作就很像是ChatGPT和DALLE3的联动了!接下来让Mini-Gemini做自己最擅长的推理和图片理解,看看它表现。输入冰川中的仙人掌,它会解释其中的矛盾并生成一张热带雨林中北极熊的图片:图片呈现了仙人掌的典型栖息地与冰的存在之间的视觉矛盾,因为在沙漠环境中自然不会出现冰。
Mini-Gemini正是理解了这种矛盾点,才生成了一张北极熊出现在热带雨林的图片。这种并置创造了一个引人注目且超现实的视觉效果,挑战观众的期待,并可能引发人们对气候变化、环境适应或不同生态系统融合的思考。同时,正如ChatGPT+DALLE3的梦幻结合一样,Mini-Gemini的「推理生成」功能还可以在多轮对话中通过简单指令生成连环小故事。Mini-Gemini会根据前文的文字生成结果和用户输入进行推理,在保持一致性的情况下对图片进行修改,使其更符合用户的要求。当然,Mini-Gemini对于多模态模型的传统技能图片理解也不在话下。比方让模型理解输入曲线图的数学意义(高斯分布),并让它使用代码复现这张图。通过运行生成的代码,模型可以高质量地还原曲线图,节省了复现的时间。超会玩梗
又或者让Mini-Gemini理解梗图,通过其强大的OCR和推理能力,也可以准确指出笑点。一张将麦当劳P成GYM表情包,外加对话图,搞笑点在哪?Mini-Gemini可以准确理解图中讽刺含义,并给出了正确的解释。还有这张「当某媒体说AI将接管世界,实际上我的神经网络连猫未能识别」的梗图。Mini-Gemini也是可以理解,是在说AI犯错的例子,并且与公众接受到的预期并不一样。高清复杂的多图表理解和归纳也是小菜一碟,Mini-Gemini直接秒变打工人效率提升的超级外挂。英文图表太复杂,读起来太费脑子?它直观地用中文整理出了内容——「比较不同笼养系统中母鸡所承受的平均疼痛天数」。如上演示中,Mini-Gemini是怎样做到这种惊艳的效果呢?

论文地址:https://arxiv.org/pdf/2403.18814.pdfGithub地址:https://github.com/dvlab-research/MiniGemini模型地址:https://huggingface.co/collections/YanweiLi/mini-gemini-6603c50b9b43d044171d0854数据地址:https://huggingface.co/collections/YanweiLi/mini-gemini-data-660463ea895a01d8f367624e大道至简,Mini-Gemini的整体思路并不复杂。其中的Gemini(双子座)表达的是使用视觉双分支的信息挖掘(Miraing-Info in Gemini)解决高清图像理解问题。而其中的核心在于三点:
(1)用于高清图像的双编码器机制;
(2)更高质量的数据;
详细来说,Mini-Gemini将传统所使用的ViT当做低分辨率的Query,而使用卷积网络(ConvNet)将高分辨率的图像编码成Key和Value。使用Transformer中常用的Attention机制,来挖掘每个低分辨率Query所对应的高分辨率区域。从而在保持最终视觉Token数目不变的情况下去提升对高清图像的响应,保证了在大语言模型(LLM)中对于高清图像的高效编码。值得一提的是,由于高分辨率分支卷积网络的使用,可以根据需要对图像所需的分辨率自适应调整,能够遇强则强。对于图像的生成部分,Mini-Gemini借助了SDXL,使用LLM推理后所生成的文本链接两个模型,类似于DALLE3的流程。而对于数据这个「万金油」,Mini-Gemini进一步收集并优化了训练数据的质量,并加入了跟生成模型结合的文本数据进行训练。在仅使用2-3M数据的情况下,实现了对图像理解、推理、和生成的统一流程。Mini-Gemini在各种Zero-shot的榜单上毫不逊色于各种大厂用大量数据训练出来的模型,可谓是「平、靓、正」 !媲美Gemini Pro和GPT-4V
可以看出,Mini-Gemini提供了多种普通和高清版本的模型,并且覆盖了2B的小杯到34B的超大杯。各个版本都取得了相似参数量下领先的效果,在许多指标上甚至超越Gemini Pro和GPT-4V。值得一提的是,Mini-Gemini的图像理解和生成能力已经出了Demo,可以在线跟自定义图像对话的那种。
操作也极其简单,直接跟输入图像或文字进行对话即可,欢迎来撩!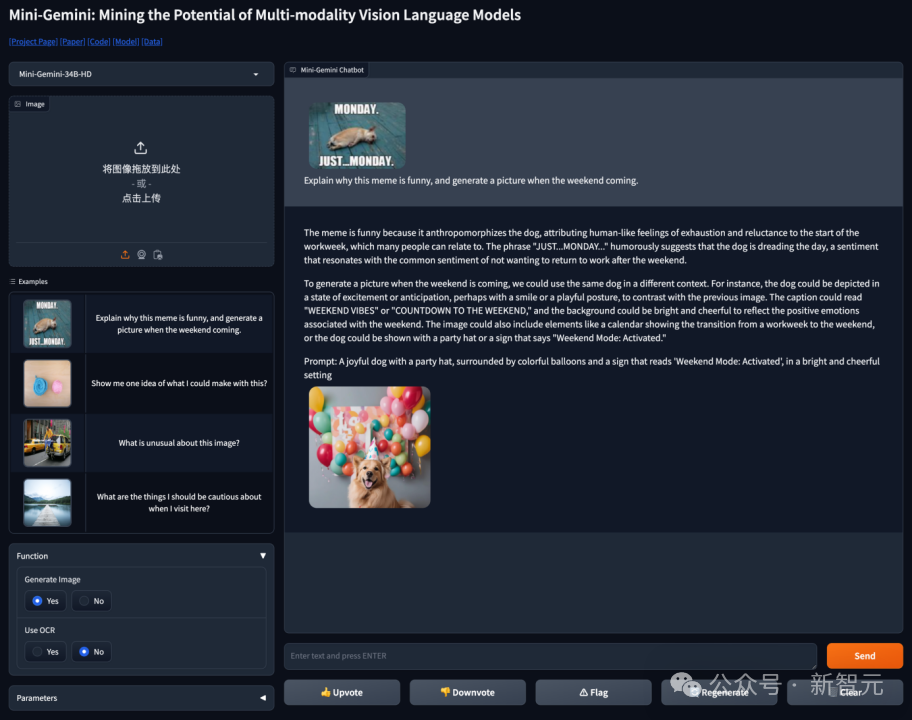
Demo地址:http://103.170.5.190:7860/https://arxiv.org/pdf/2403.18814.pdfhttps://github.com/dvlab-research/MiniGeminihttps://huggingface.co/collections/YanweiLi/mini-gemini-6603c50b9b43d044171d0854https://huggingface.co/collections/YanweiLi/mini-gemini-data-660463ea895a01d8f367624ehttp://103.170.5.190:7860/








