 夕小瑶科技说 原创
夕小瑶科技说 原创
作者 | 谢年年、python
ChatGPT通过交互式API就能像专家一样回答各种问题。但当遇到一些专业领域的问题时,它们可能会“短路”,给出不太准确的答案,因为这些问题它们之前没学过!
既然缺少知识,那么要解决这个问题就要想办法将知识整合到LLMs中。常用的知识注入方法属于“白盒”,需要对LLMs的模型架构和参数了如指掌。
但ChatGPT、GPT-4通过API提供访问权限,只能通过提交文本输入来获取模型的响应,而模型的具体细节无法获取,因此“白盒”知识注入方法不再适用。
香港理工大学团队介绍了一种名为KnowGPT的黑盒知识注入框架,仅通过API将知识图谱高效地集成到LLMs。KnowGPT利用强化学习从知识图谱中提取相关知识,并使用多臂赌博机为每个问题构建最合适的提示。
该框架在三个基准数据集上表现得非常出色,甚至比ChatGPT要好23.7%,比GPT-4还要强2.9%!
更厉害的是,它在OpenbookQA官方排行榜上达到了91.6%的准确率,跟人类的表现差不多!
论文标题:
KnowGPT: Black-Box Knowledge Injection for Large Language Models
论文链接:
https://arxiv.org/pdf/2312.06185.pdf
问题定义
给定一个问题上下文,一个LLM ,和一个知识图谱,包含三元组(头实体,关系,尾实体),表示为,目标是学习一个提示函数,生成一个提示
,将的上下文和中的事实知识结合起来,使得LLM的预测能够输出的正确答案。
KnowGPT框架
整体框架如下图所示,根据问题背景和答案选项,从现实世界的知识图谱中检索出一个问题特定的子图。首先,路径提取模块寻找最具信息量和简洁推理背景来适应上下文。然后,优化提示转换模块,考虑给定问题的知识和格式的最佳组合。
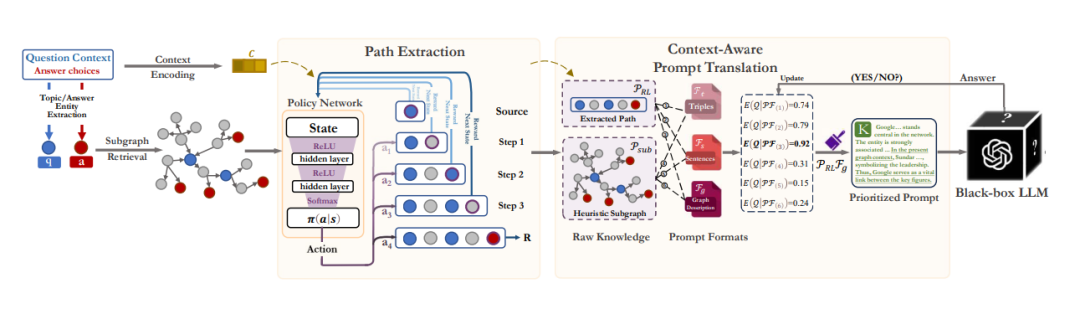
1. 基于强化学习的路径提取
相关的推理背景位于一个特定于问题的子图中,其中包含所有的源实体、目标实体,以及它们的邻居。为了找到一个高质量、高相关性但简洁的子图,作者提出利用强化学习以试错的方式对推理路径进行采样。每个推理路径的采样都能建模为一个马尔科夫决策过程,包括状态、动作、转移和奖励。
状态: 状态表示知识图谱中当前的位置,即知识图谱中的一个实体。具体而言,它表示从实体到的空间变化。状态向量定义为, 其中,和分别表示当前实体和目标实体的嵌入向量。为了获得从背景知识图谱中提取的实体的初始节点嵌入,将知识图谱中的三元组转换为句子,并将其输入预训练语言模型中以获取节点嵌入。
行动:行动空间包含当前实体的所有邻近实体。通过采取行动,模型将从当前实体移动到选择的邻近实体。
转移模型: 转移模型是用来衡量在给定当前状态和采取的动作的情况下,移动到新状态的概率。在知识图谱中,转移模型的形式为 ,如果通过动作将转向;否则,
。
然后作者设计了三项奖励来促进生成高质量的路径。
路径可达性
路径最终要在有限的步数内达到目标。因此为了确定形成路径的质量,作者根据可达性定义了奖励,如果在K个行动内达到目标,将获得奖励+1。否则,将获得奖励−1。
上下文相关性
路径与上下文越相关,越应该被奖励,作者为了评估两者的语义相关性,应用一个矩阵
,将路径嵌入映射到与上下文嵌入相同的语义空间中,奖励被表述为:
其中,文本嵌入都是从开源的轻量级语言模型例如Bert-Base中得到的。是上下文的嵌入,路径的嵌入是从起始点走到第i步所经过的所有实体和关系的嵌入的平均值,即。这个逐步奖励机制在达到目标之前就提供了奖励。
路径简洁性
基于黑盒LLMs对输入长度的限制和调用成本考虑,引导的提示需在最短的路径长度内找到尽可能多有价值的信息。因此作者引入了路径简洁性的评估,以减少冗余实体(例如同义词)带来的代价。定义如为:
最后,使用权衡参数来平衡每个奖励的重要性:
2. 基于多臂赌博机构建提示
多臂赌博机MAB有许多“臂”,每次选择一个“臂”进行尝试,都会得到一个结果或奖励。一方面,希望“利用”那些之前表现良好的“臂”,可以在短时间内获得最大的奖励。另一方面,也想“探索”那些之前没有尝试过的“臂”,可能发现更好的策略或选择,从而在未来获得更大的奖励。
基于该原理,提示构建就是要想办法选择最有前途的提示。
假设有几种路径提取策略 和几种候选提示格式。每个路径提取策略是一种在给定问题环境下选择子图的方法,每个提示模板
代表一种将子图中的三元组转化为LLM预测的提示机制。
提示构建问题是要确定给定问题的最佳和的组合。作者将选择的整体过程定义为一个奖励最大化问题
,其中 的计算如下:
为了捕捉问题与不同知识和提示格式组合间的上下文感知相关性, 作者使用期望函数E(·)来确定多臂赌博机的选择机制。它能自适应地衡量不同问题对某个组合的潜在期望。
表示的嵌入。向量是与相关联的一组非负参数,是一个平衡因子,根据高斯分布引入噪声。
通过最大化期望函数,LLM学会了平衡开发和探索,以优先选择最有前途的提示来回答特定的问题背景。
最终,使用两种路径提取策略和三种提示模板来实现以上的多臂赌博策略。
路径提取策略包括:
-
:由于强化学习不够稳健,引入作为MAB选择的备选策略。这是一种启发式的子图提取策略,在源实体和目标实体周围提取2跳子图。
模板选择策略:
- 三元组, 例如(Sergey_Brin, founder_of,Google),(Sundar_Pichai, ceo_of, Google), (Google, is_a, Hightech Company)。
- 句子描述 ,将知识转化为口语化句子,例如,“谢尔盖·布林是高科技公司谷歌的创始人之一,现由桑达尔·皮查伊掌舵,担任该公司的首席执行官。”
- 图表描述 ,将知识视为结构化图表来激活LLM。通过使用黑盒LLM预处理提取的知识,突出中心实体生成描述, 例如,“谷歌,一家高科技公司,在网络中处于核心位置。该实体与科技行业中的重要人物密切相关。创始人之一Sergey Brin,他创建了谷歌,强调了其历史起源。在当前的图表环境中,Sundar Pichai是谷歌现任CEO。因此,谷歌在这些重要人物之间起着至关重要的纽带作用。”
多臂老虎机通过来自语言模型的反馈进行训练,以优先选择在不同实际问题背景下最合适的两种提取方法和三种预定义提示格式的组合。即
实验设置与结果
评估数据集选用CommonsenseQA(多项选择题问答数据集),OpenBookQA(多项选择题),MedQA-USMLE(医学多项选择题)。
对于常识推理,知识图谱选用ConceptNet,这是一个庞大的常识知识图谱,包括超过800万个通过34个简洁关系相互连接的实体。针对医学领域特定任务,采用生物医学知识图谱USMLE,它综合了统一医学语言系统(UMLS)的疾病数据库部分和DrugBank。该知识库包括9958个节点和44561条边。
整体实验结果
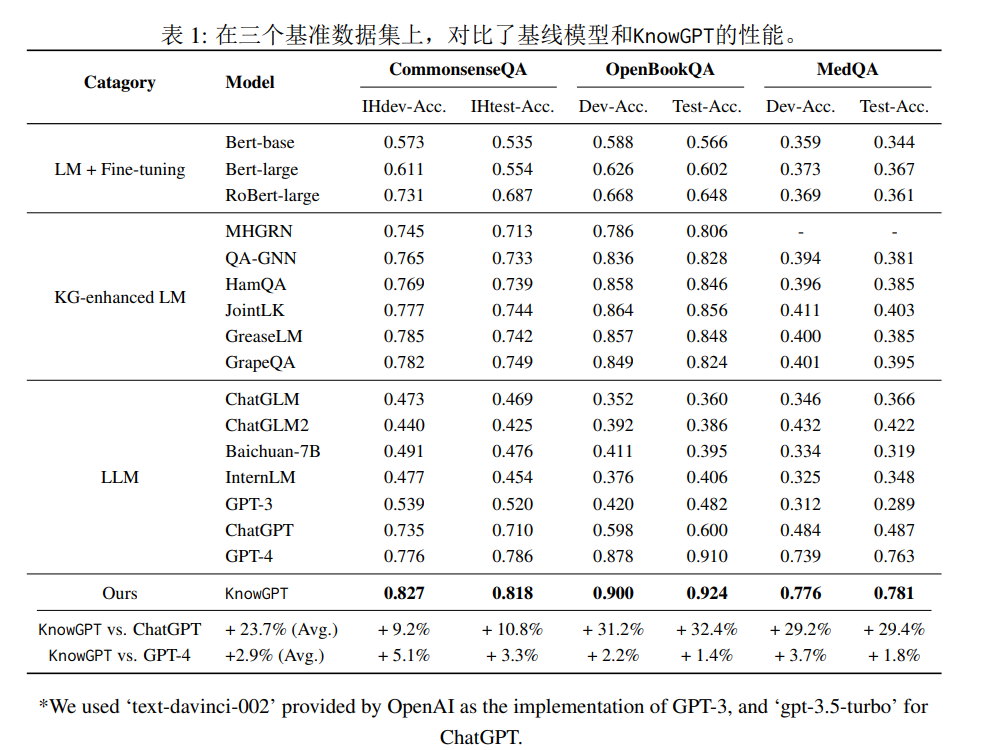
- KnowGPT在所有数据集和模型结构上表现优于所有类别的方法。
- KnowGPT明显优于所有知识图谱增强的语言模型。这表明黑盒知识注入方法能够有效地将知识编码到语言模型中。
- KnowGPT超越了ChatGPT甚至GPT-4的性能。平均来看KnowGPT的准确度比ChatGPT高23.7%。
- 更重要的是,尽管KnowGPT基于ChatGPT,但在三大数据集上分别比当前最先进的GPT-4高出3.3%、1.4%和1.8%。这表明黑盒知识注入可以有效增强LLM的能力。
另外作者将KnowGPT测试结果提交到OpenbookQA的官方排行榜上,与最佳基准线相比,KnowGPT显著优于传统的知识图增强语言模型,并可以与人类表现相媲美。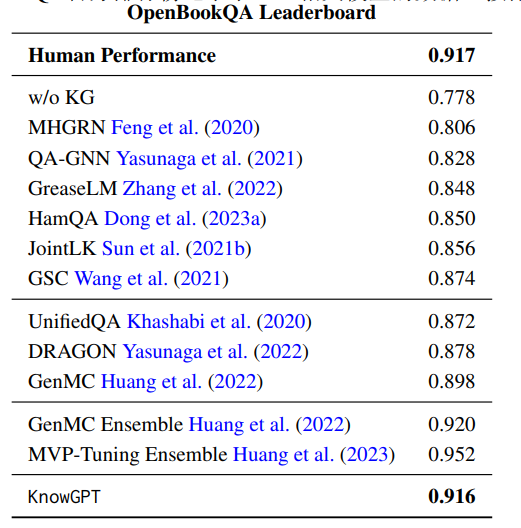
消融实验
为了研究基于多臂老虎机的提示构建策略是否有助于性能改进,作者进行了两项消融研究。
作者测量了定制的强化学习路径提取模块的重要性。将其与直接路径提取方法进行了比较。通过以“句子”为提示格式直接将提取的知识输入ChatGPT进行性能评估。作者还将“无知识图谱”作为基准,要求ChatGPT在没有提供推理背景的情况下独立回答给定的问题。结果如下表所示,表明了路径提取策略的重要作用。
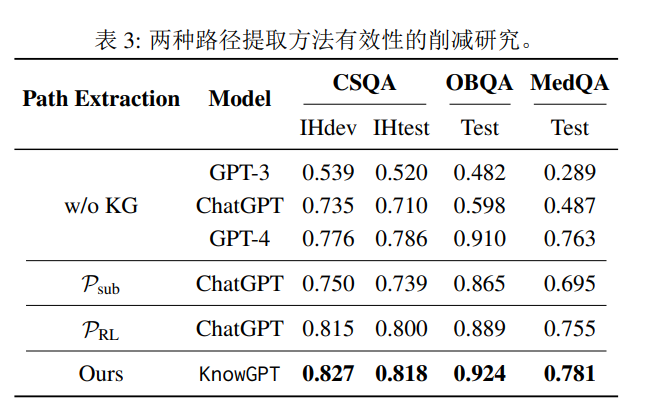
作者还比较了三种提示格式在相同提取的知识下的效果。
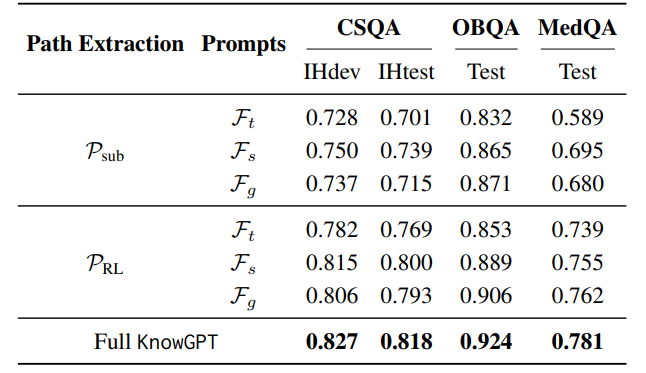
结果显示,尽管不同的格式表现相似,误差保持在2.2% - 3.3%,但也可以发现它们擅长的问题类型不同。
下图是针对同一问题基于三种不同格式生成的最终提示内容:
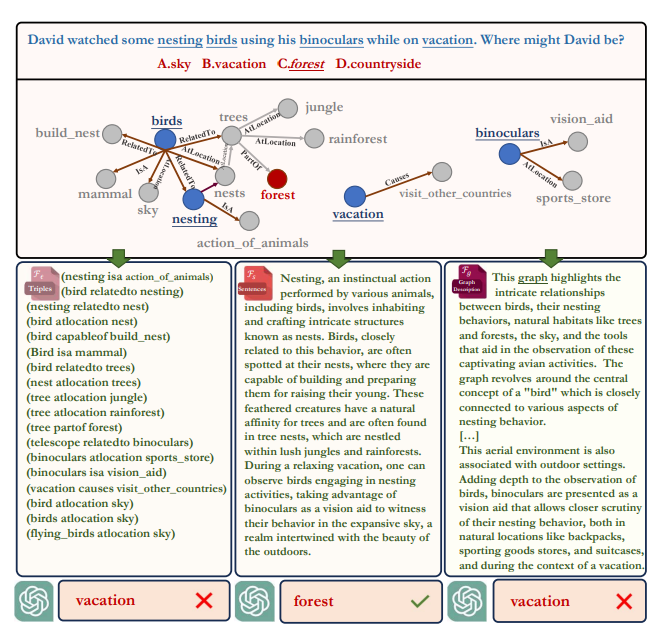
在这个例子中,给定相同的提取出的知识,ChatGPT根据提供的句子格式模板正确回答了问题。当给出三元组和图形描述时,它无法回答问题。因此KnowGPT有必要融合多种提示模板,才能保证在大多数问题上回答正确。
结论
本文正式定义了“用于复杂问题回答的LLM黑盒知识注入”问题,并提出了一种名为“KnowGPT”的新型框架,只借助模型API有效地将知识图谱(KGs)融合到LLMs中,在通用和领域特定问题回答数据集上都取得了不错的效果,为未开源的LLMs注入知识提供了一条有趣的研究路径。














