文字摘要
机器学习(ML)越来越多地被用于环境研究中,以处理大型数据集并解析系统变量之间的复杂关系。然而,由于缺乏熟悉度和方法论严谨性,不充分的ML研究可能导致虚假结论。在本研究中,本文作者综合了文献分析与本文作者自己的经验,并编制了一个类似教程的常见陷阱清单及最佳实践指南,适用于环境领域的机器学习研究。本文作者识别出超过30个关键项,并基于148篇高引用的研究文章提供了证据支持的数据分析,展示了术语的误解、适当的样本量和特征量、数据增强和特征选择、随机性评估、数据泄漏管理、数据分割、方法选择与比较、模型优化与评价以及模型可解释性和因果关系等方面的问题。通过分析监督学习和参考建模范例中的良好示例,本文作者希望帮助研究人员采用更严格的数据预处理和模型开发标准,以便在环境研究和应用中实现更准确、更稳健、更实用的模型使用。
图片摘要
数据泄露或信息泄露是指在训练阶段模型从不可用或未见过的数据中获取信息,这会导致结果偏差。数据泄露可以在整个建模过程中发生,包括数据收集、数据预处理、模型实施和模型优化过程:
- 数据泄露首先可能在数据收集时发生,当一个变量(特征)携带关于响应变量的“作弊”信息时(图3(a))。
- 特征工程(如特征选择)通常是基于输入特征之间的关系或特征与响应变量之间的关系来进行的,重要特征应仅根据(预)训练数据来确定(图3(b))。
- 在特征缩放(即标准化或归一化)上的错误应用,这会将未见数据集(验证或测试)的信息(如分布或最小/最大值)带入(预)训练模型(图3(c))。
- 表明来自同一项研究的所有数据通常使用相同的实验条件,因此典型的随机数据拆分会导致数据泄漏(图 3(d))。这是因为大多数实验研究使用 OFAT 方法(一次只改变一个变量),因此来自一项研究的数据集在非变化变量上可以有许多相同的值。因此,模型可能过度依赖特定变量或值,而不是构建环境过程的输入输出关系和机制。
- 时间相关特征可以携带有助于增强预测的重要信息,使用移动窗口方法将相同的数据(例如,在同一天或同一小时)分配给相邻的连续样本。在这种情况下,典型的随机拆分可能会导致可见数据集和未可见数据集之间潜在的数据共享(图 3(e))。一种合适的方法是将一部分数据(表示为块拆分)设置为(预)训练,将另一部分设置为测试或验证。
- 与特征缩放类似,用基于整个数据的代表值(例如平均值或中位数)替换缺失数据会泄露有关未见数据的底层信息(图 3(f))。
- 图 3(g)说明了一种使用邻居值填补缺失空白的常见方法,因此填充的数据自然会携带有关邻居样本的信息。在这种情况下,典型的随机拆分可能会违反 DLM 将它们分配到训练和测试数据集中。
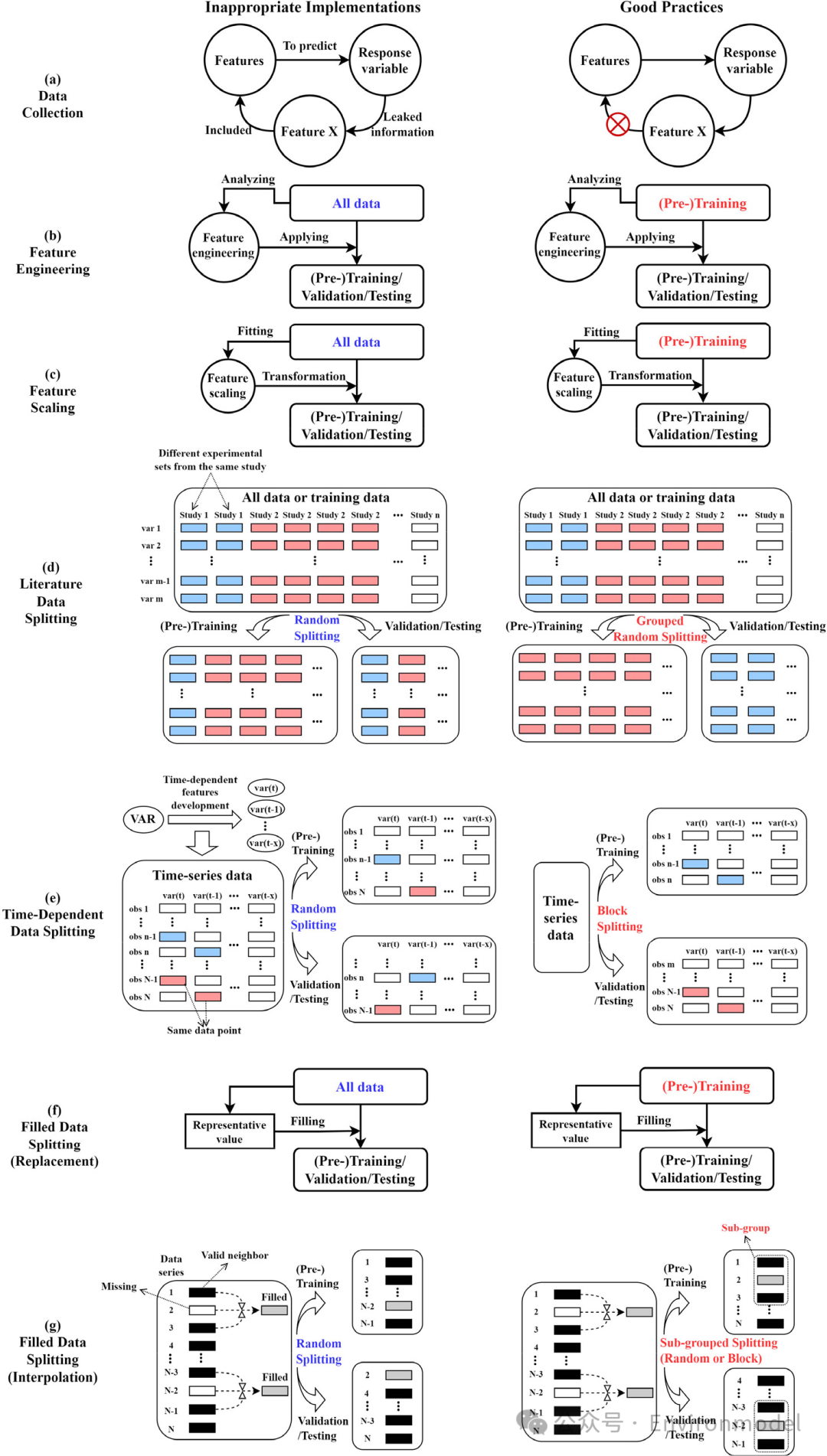
图 3. 不涉及交叉验证时监督学习模型开发中常见且容易被忽视的数据泄露问题,以及解决此类问题的相应良好实践。不恰当的实现和良好实践之间的主要区别(文本)分别标记为蓝色和红色。大多数问题都是由于错误地利用所有数据来生成必要的信息而导致的。
CV 中的 DLM 遵循上述相同的程序,尽管它们更容易被忽略。主要区别源于 CV 的本质,即将训练数据分成k 个部分,因此基本原则是将 CV 设置为最外部框架,任何数据预处理都需要在该框架内完成(图 4)。例如,没有 CV 的特征工程中的 DLM 的良好实践(图 3(b))不能通过直接分析训练数据(图 4(a))应用于 CV 场景。相反,特征工程应在 CV 循环内的每个分割处迭代执行(例如,在管道中包含特征选择)。然而,在示例文章中没有发现这种做法,可能是因为 CV 中的 DLM 不太为人所知。类似地,特征缩放(图 4(b))和 MDM 中的代表值替换(图 4(e)和(f))也需要在每次分割时执行,以避免从验证部分到预训练部分的潜在信息泄露。
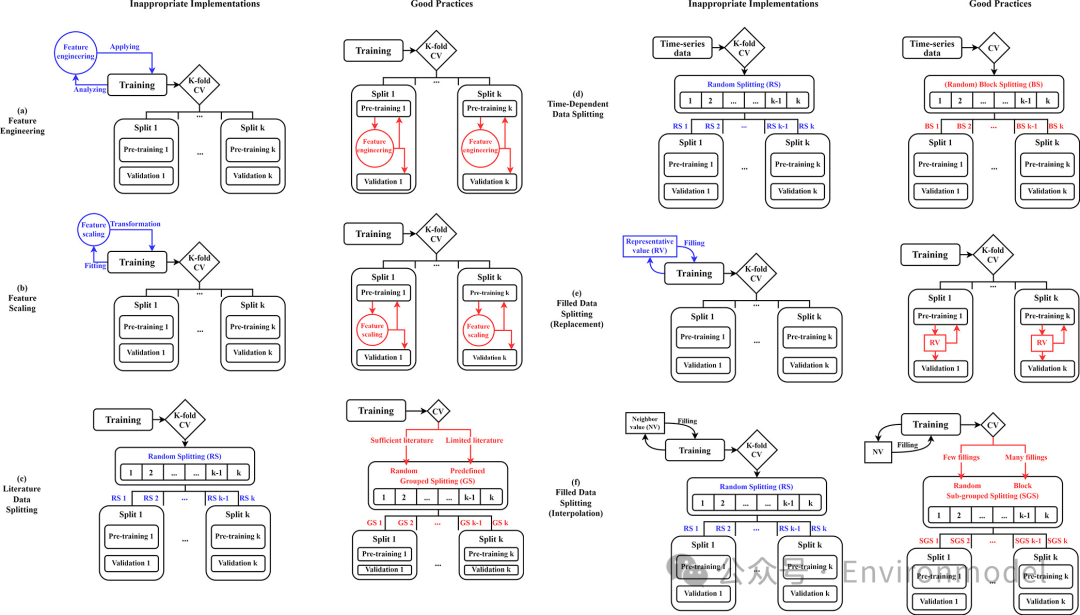
图 4. 监督学习模型开发中涉及交叉验证时常见且容易被忽视的数据泄露问题,以及解决此类问题的相应良好做法。不适当实现和良好做法之间的主要区别(文本)分别标记为蓝色和红色。许多问题都是由于错误地未在 CV 循环中包含数据预处理步骤而导致的。
方法选择——找到最适合的方法,不一定是最受欢迎的方法
选定的 148 篇论文产生了 166 种最优方法(可以基于多种方法构建集成模型),其中神经网络相关方法占 43.9%,其中 MLP(n = 50)的使用频率高于其他 ANN 类型,其次是 CNN(8)、LSTM(7)和极限学习机(ELM)(5)(图 5(a))。基于树的方法总共占 37.2%,其中 RF(n = 34)是最受欢迎的方法,其次是分类和回归树(CART)(8)、BRT(8)和随机梯度提升(SGB)(3)。SVM/SVR(n = 16)是另一种流行的选择。相当多的研究(37.8%)使用了一种机器学习方法而没有与其他方法进行比较(图 5(b)),但更多的研究(44.6%)与至少一种机器学习方法进行了比较(图 5(c))。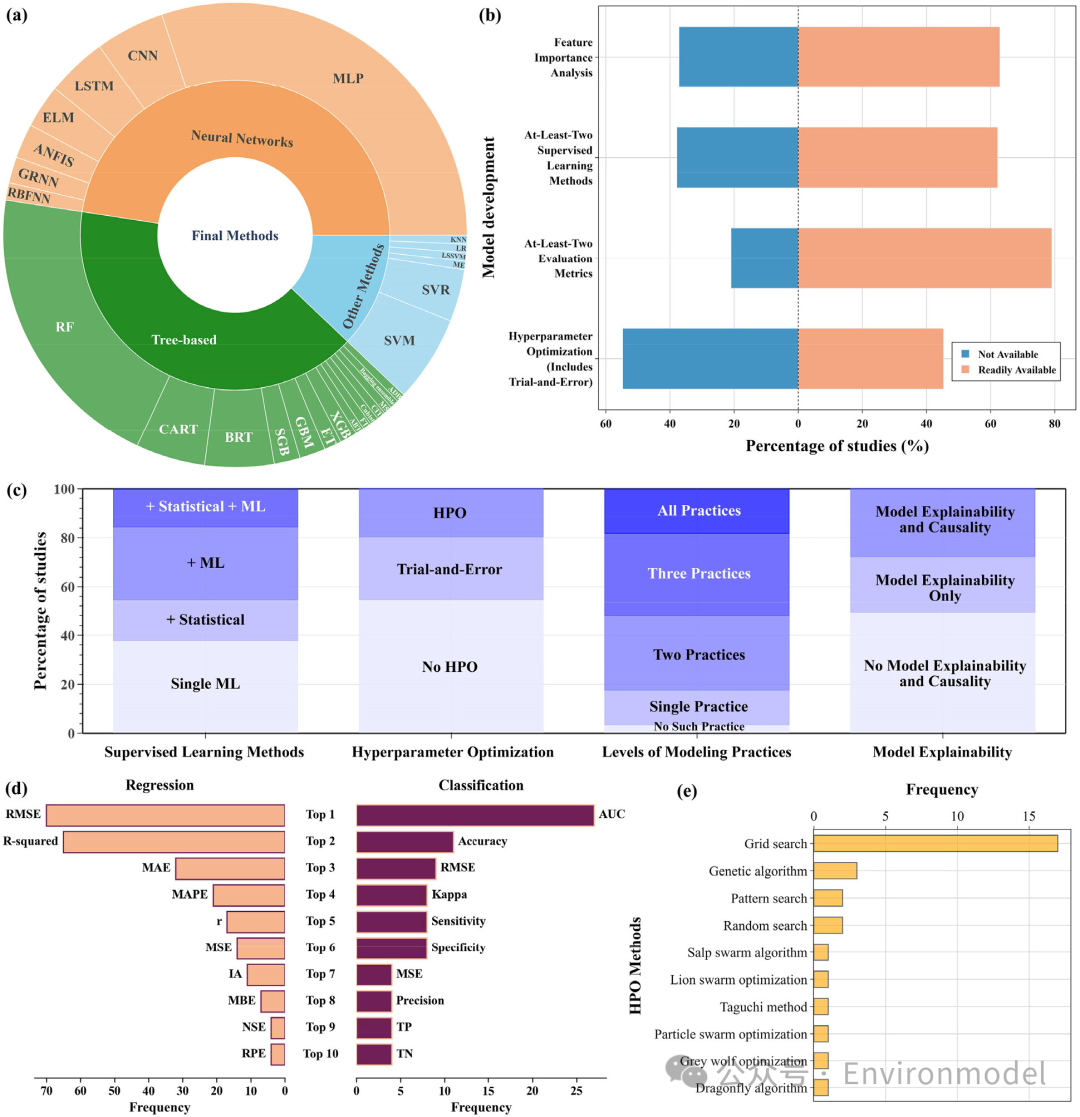
图 5. 基于 148 篇高引用率研究对模型开发、优化和解释中的主要问题进行定量评估。(a)研究中使用的最终方法的分数。(b)进行每种建模实践的研究的百分比。(c)采用 ML/统计方法、进行 HPO、具有不同级别的建模实践并执行模型可解释性和因果关系的研究的百分比。(d)用于回归和分类问题的前十大评估指标。(e)最常见的 HPO 方法。模型优化——提升信心和活力
机器学习具有内置的学习能力,这是其内在的优化过程(如随机梯度下降SGD),而外部的超参数优化(HPO)过程有时会被忽视。无论研究目的如何,HPO都是一个有益的步骤,因为它有助于构建更准确、更稳健、更可靠的模型。图 6显示了三个典型的简化 HPO 图。考虑到通常可用的资源有限,建议使用 GS 或类似的搜索算法,并且可以与 TVT 和 CVT 一起调整。元启发式方法需要更多的计算资源,因此 TVT 可能是一种更具成本效益的实践框架。GS 需要研究人员预先定义n 个超参数组合候选,该函数通过基于 TVT 设计中的候选重复n次预训练到验证步骤来工作(图 6)。本文中,作者使用TVT(预训练、验证和测试)和CVT(使用交叉验证 (CV) 进行训练和测试)来表示另外两个最常见的数据拆分框架。
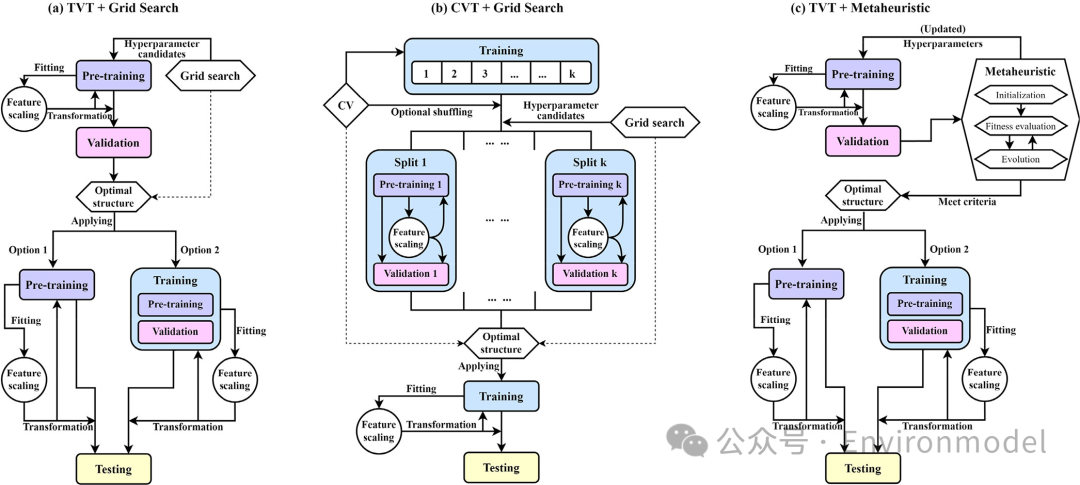
图 6. 监督机器学习模型开发的三种常见超参数优化途径。(a)使用网格搜索进行 TVT 数据分割;(b)使用网格搜索进行 CVT 数据分割;(c)使用元启发式方法进行 TVT 数据分割。流程图中简化了数据预处理,仅显示特征缩放。训练、预训练、验证和测试子集以不同颜色突出显示总结了众多的陷阱和推荐做法,本文作者准备了两个参考范式,它们描述了监督机器学习模型开发的最低要求和最佳实践(图 7)。
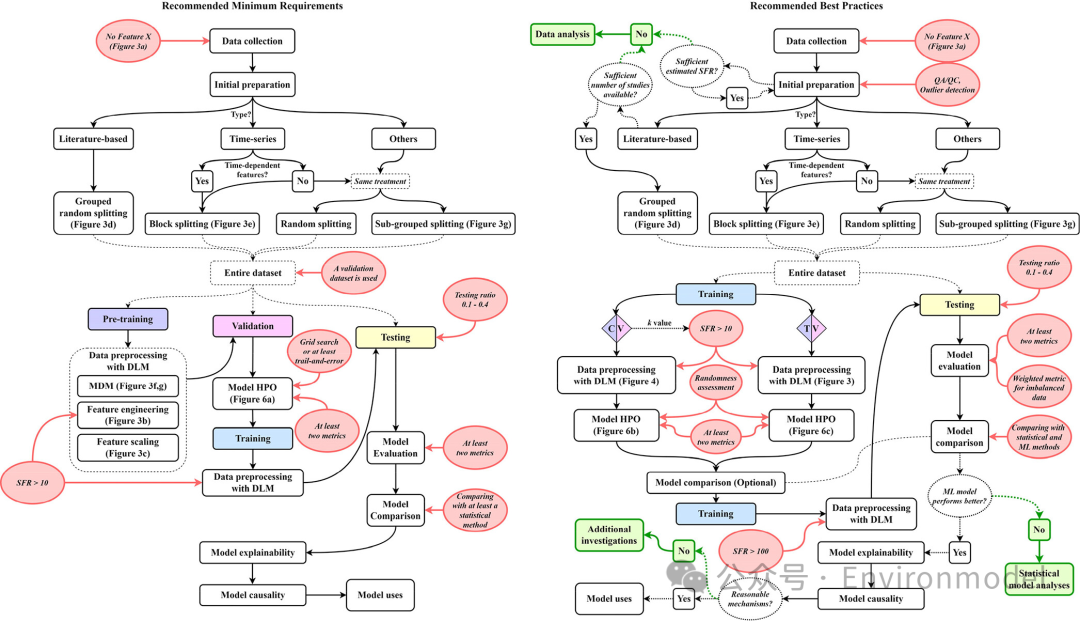
图 7. 环境研究中监督机器学习模型开发的 (a) 最低要求和 (b) 最佳实践的建议。请注意,它们仅代表典型条件,应根据具体情况应用配置。要求以红色圆圈表示,三个备选终点以绿色突出显示。训练、预训练、验证和测试子集也以颜色突出显示。Soil & Environmental Health是由朱利中院士、朱永官院士和马奇英教授担任主编、浙江大学与Elsevier合作出版的全英文开放获取国际学术期刊。自2022年12月以来,期刊出版了来自16个国家的61篇优秀文章;期刊CiteScoreTracker 2024 为5.5,目前已被DOAJ、Scopus和CAS数据库收录。
微信号 | SEH2023
Twitter|@soileh2023
年度 Top5 热点文章推荐(2023年)









