
凡是搞计量经济的,都关注这个号了
邮箱:econometrics666@126.com
所有计量经济圈方法论丛的code程序
, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.

关于HLM,参看:1.HLM多层线性模型是什么? 嵌套数据处理之王,2.HLM软件操作指南, 多层线性分析必备
,3.随机系数模型及程序实现和解读Lecture,4.随机系数Logit模型及Stata实现,5.混合效应模型MEM,6.混合线性模型MEM,层级数据处理利器,7.R软件中的计量经济学程序包纵览
今天,主要介绍多水平模型:线性混合模型、混合logit模型、随机效应模型,并通过数据和code展示他们的实现过程。混合线性模型是20世纪80年代初针对统计资料的非独立性而发展起来的。由于该模型的理论起源较多,根据所从事的领域、模型用途,又可称为多水平模型(Multilevel,MLM)、随机系数模型(Random Coefficients,RCM)、等级线性模型(Hierarchical Linear,HLM)等。甚至和广义估计方程也有很大的交叉。这种模型充分考虑到数据聚集性的问题,可以在数据存在聚集性的时候对影响因素进行正确的估计和假设检验。不仅如此,它还可以对变异的影响因素加以分析,即哪些因素导致了数据间聚集性的出现,哪些又会导致个体间变异增大。由于该模型成功地解决了长期困扰统计学界的数据聚集性问题,20年来已经得到了飞速的发展。在传统的线性模型(y=xb+e)中,除X与Y之间的线性关系外,对反应变量Y还有三个假定:①正态性,即Y来自正态分布总体;②独立性,Y的不同观察值之间的相关系数为零;③方差齐性,各Y值的方差相等。但在实际研究中,经常会遇到一些资料,它们并不能完全满足上述三个条件。例如,当Y为分类反应变量时,如性别分为男、女,婚姻状态为已婚、未婚,学生成绩是及格、不及格等,不能满足条件①。当Y具有群体特性时,如在抽样调查中,被调查者会来自不同的城市、不同的学校,这就形成一个层次结构,高层为城市、中层为学校、低层为学生。显然,同一城市或同一学校的学生各方面的特征应当更加相似。也就是基本的观察单位聚集在更高层次的不同单位中,如同一城市的学生数据具有相关性,不能满足条件②。当自变量X具有随机误差时,这种误差会传递给Y,使得Y不能满足条件③。如果对不满足正态性、独立性、方差齐性三个适用条件的资料采用传统的分析方法,对所有样本一视同仁,建立回归方程,就会带来如下问题:(3)容易导致估计值过高,使常用的检验失效,从而增加统计检验I型错误发生的概率。如果我们对不同的群体分别建立各自的回归模型,当群体数较少,群体内样本容量较大,传统的分析方法可能是有效的。或者,我们的兴趣仅在于对这些群体分别做一些统计推断时,也适合用这种方法。但是如果我们把这些群体看成是从总体中抽样来的一个样本(例如多阶段抽样和重复测度数据),并想分析不同群体之间的总体差异,那么简单地使用传统的统计方法是不够的。同样,如果一些群体包含的样本容量较少,对这些群体做出的推断也不可靠。因此,我们需要把这些群体看成是从总体抽样来的样本,并使用样本总体的信息来进行推断。方差分析(analysis of variance (ANOVA) )主要有三种模型:即固定效应模型(fixed effects model),随机效应模型(random effects model),混合效应模型(mixed effects model)。所谓的固定、随机、混合,主要是针对分组变量而言的。固定效应模型,表示你打算比较的就是你现在选中的这几组。例如,我想比较3种药物的疗效,我的目的就是为了比较这三种药的差别,不想往外推广。这三种药不是从很多种药中抽样出来的,不想推广到其他的药物,结论仅限于这三种药。“固定”的含义正在于此,这三种药是固定的,不是随机选择的。
随机效应模型,表示你打算比较的不仅是你的设计中的这几组,而是想通过对这几组的比较,推广到他们所能代表的总体中去。例如,你想知道是否名牌大学的就业率高于普通大学,你选择了北大、清华、北京工商大学、北京科技大学4所学校进行比较,你的目的不是为了比较这4所学校之间的就业率差异,而是为了说明他们所代表的名牌和普通大学之间的差异。你的结论不会仅限于这4所大学,而是要推广到名牌和普通这样的一个更广泛的范围。“随机”的含义就在于此,这4所学校是从名牌和普通大学中随机挑选出来的。混合效应模型就比较好理解了,就是既有固定的因素,也有随机的因素。一般来说,只有固定效应模型,才有必要进行两两比较,随机效应模型没有必要进行两两比较,因为研究的目的不是为了比较随机选中的这些组别。固定效应和随机效应的选择是大家做面板数据常常要遇到的问题,一个常见的方法是做huasman检验,即先估计一个随机效应,然后做检验,如果拒绝零假设,则可以使用固定效应,反之如果接受零假设,则使用随机效应。但这种方法往往得到事与愿违的结果。另一个想法是在建立模型前根据数据性质确定使用那种模型,比如数据是从总体中抽样得到的,则可以使用随机效应,比如从N个家庭中抽出了M个样本,则由于存在随机抽样,则建议使用随机效应,反之如果数据是总体数据,比如31个省市的Gdp,则不存在随机抽样问题,可以使用固定效应。同时,从估计自由度角度看,由于固定效应模型要估计每个截面的参数,因此随机效应比固定效应有较大的自由度.固定效应模型(fixed effects model)的应用前提是假定全部研究结果的方向与效应大小基本相同,即各独立研究的结果趋于一致,一致性检验差异无显著性。因此固定效应模型适用于各独立研究间无差异,或差异较小的研究。固定效应模型是指实验结果只想比较每一自变项之特定类目或类别间的差异及其与其他自变项之特定类目或类别间交互作用效果,而不想依此推论到同一自变项未包含在内的其他类目或类别的实验设计。例如:研究者想知道教师的认知类型在不同教学方法情境中,对儿童学习数学的效果有何不同,其中教师和学生的认知类型,均指场地依赖型和场地独立型,而不同的教学方法,则指启发式、讲演式、编序式。当实验结束时,研究者仅就两种类型间的交互作用效果及类型间的差异进行说明,而未推论到其他认知类型,或第四种教学方法。象此种实验研究模式,即称为固定效果模式。与本词相对者是随机效应模型(random effect model)、混合效应模型(mixed effect model)。随机效应模型 random effects models随机效应模型(random effects models)是经典的线性模型的一种推广,就是把原来(固定)的回归系数看作是随机变量,一般都是假设是来自正态分布。如果模型里一部分系数是随机的,另外一些是固定的,一般就叫做混合模型(mixed models)。虽然定义很简单,对线性混合模型的研究与应用也已经比较成熟了,但是如果从不同的侧面来看,可以把很多的统计思想方法综合联系起来。概括地来说,这个模型是频率派和贝叶斯模型的结合,是经典的参数统计到高维数据分析的先驱,是拟合具有一定相关结构的观测的典型工具。随机效应最直观的用处就是把固定效应推广到随机效应。注意,这时随机效应是一个群体概念,代表了一个分布的信息 or 特征,而对固定效应而言,我们所做的推断仅限于那几个固定的(未知的)参数。例如,如果要研究一些水稻的品种是否与产量有影响,如果用于分析的品种是从一个很大的品种集合里随机选取的,那么这时用随机效应模型分析就可以推断所有品种构成的整体的一些信息。这里,就体现了经典的频率派的思想-任何样本都来源于一个无限的群体(population)。同时,引入随机效应就可以使个体观测之间就有一定的相关性,所以就可以用来拟合非独立观测的数据。经典的就有重复观测的数据,多时间点的记录等等,很多时候就叫做纵向数据(longitudinal data),已经成为很大的一个统计分支。混合效应模型(Mixed Effect Model)可以轻松处理多种研究设计和数据类型,因而越来越多地被研究者采用进行分析。它能够处理的模型类型包括:固定效应方差分析模型、完全随机区组设计(Randornized Complete Blocks Design)、裂区设计(Split-Plot Design)、纯随机效应模型(Purely Random Effects Model)、随机系数模型(Random Coefficient Model)、多水平分析(Multilevel Analysis)、非条件线性生长模型(Unconditional Linear Growth Model)、具有皮尔逊协变量的线性生长模型(Linear Growth Model with a Person-Level Covariate)、重复测量分析、具有依时协变量的重复测量分析(Repeat Measures Analysis with Time-Dependent Covariates)。一句话,混合效应模型非常强大。混合效应模型之所以那么“万能”,是因为它把模型的效应分解为固定效应和随机效应,而随机效应可以解释很多复杂的研究设计和数据结构。比如,在多水平研究设计中,随机效应就可以把多水平之间的嵌套关系进行拟合;我们常见的重复测量数据,每个研究对象具有多次的测量值,其实也属于两水平的嵌套关系,所以随机效应也可以进行拟合。
*完整版code放在计量社群里的,可以自行下载运行。
1.线性混合效应回归
混合效应回归有很多名称,包括分层线性模型、随机系数模型和随机参数模型。在混合效应回归中,一些参数是允许随样本变化的“随机效应”,其他是“固定效应”,但不是我们面板数据中那种固定效应。
例如,考虑模型
截距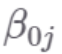 有一个j下标,并且允许在 j 级别上随样本变化,其中 j 可能表示个人或组,具体取决于研究背景。
有一个j下标,并且允许在 j 级别上随样本变化,其中 j 可能表示个人或组,具体取决于研究背景。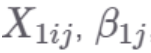 上的斜率同样允许在样本上变化。上面这些都是随机效应。
上的斜率同样允许在样本上变化。上面这些都是随机效应。
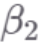 不允许在样本上变化,因此是固定的。随机参数有自己的“二级”方程,可能包括也可能不包括二级协变量。使用混合效应模型所需的假设通常与大多数线性模型相同。然而,混合效应模型假设不同级别的误差项是不相关的。在第二个层级上,统计功效取决于不同 j 值的数量。如果仅允许系数在几个组中变化,则混合效应模型可能会表现不佳。没有必要停在两个层级上——第二层级的系数也可以在更高层级上发生变化。
不允许在样本上变化,因此是固定的。随机参数有自己的“二级”方程,可能包括也可能不包括二级协变量。使用混合效应模型所需的假设通常与大多数线性模型相同。然而,混合效应模型假设不同级别的误差项是不相关的。在第二个层级上,统计功效取决于不同 j 值的数量。如果仅允许系数在几个组中变化,则混合效应模型可能会表现不佳。没有必要停在两个层级上——第二层级的系数也可以在更高层级上发生变化。
在 R 中拟合混合效应模型的一种常见方法是使用 lme4 包中的 lmer 函数。要完全拟合贝叶斯模型,可能需要考虑使用带有 rstan 包的 STAN。
Stata 有一系列基于混合程序的函数,可以估计混合效应模型。我们将估计小时工资和工作年限之间的关系,对婚姻状况进行控制,未考虑混合效应mixed wage tenure married || occupation:mixed wage tenure married || occupation: tenure, nocons我们允许允许截距随职业而变化,任期的斜率随职业而变化mixed wage tenure married || occupation: tenuremixed wage tenure married || occupation: tenure || age: tenure混合 logit 模型(有时称为随机参数 logit 模型)估计分布参数,允许存在个体层面的异质性。混合 logit 模型还有很多其他方面的灵活性,因为它涉及相关的随机参数,并且可以与面板数据一起使用。混合 logit 模型估计分布,然后,通过模拟从该分布生成参数。混合 logit 模型的估计不能简单地解释为边际效应,因为它们是最大似然估计。此外,个体水平的变化意味着估计的影响是相对于个体的。混合 logit 模型的估计非常困难,并且有很多细节和不同的方法。所以你不能真的假设一个包会产生与另一个包相同的结果。R
为了估计 R 中的混合 logit 模型,我们将首先使用 dfidx 包转换数据,然后使用 mlogit 包进行估计。Stata
从 Stata 17 开始,有一个 base-Stata xtmlogit 命令,它可能比 mixlogit 更可取。但是很多人没有Stata 17,所以这个例子使用了mixlogit,需要安装`ssc install mixlogit。mixlogit 需要以下形式的数据(尽管不一定带有变量名):其中choice 是因变量并且是二元的,表示选择了哪个选项。X 是(其中一个)预测变量,group 是不同选择场合的识别变量,Id是个体决策者标识符的向量(如果这是同一决策者做出多个决策的面板数据)。import delimited Electricity.csv, clearg decision_id = _nreshape long pf cl loc wk tod seas, i(choice id decision_id) j(option)g chosen = choice == option让我们修复除pf 之外的所有预测变量的参数,允许其变化
mixlogit chose cl loc wk tod seas, group(decision_id) id(id) rand(pf) //每个单独的选择都由 decision_id 标识,每个人都由id标识要考虑的选项:corr 允许多个参数分布相互关联,ln() 允许一些参数分布是对数正态分布我们可以使用 mixlbeta 获得单个参数估计值,这会将估计值保存到文件中mixlbeta pf, saving(pf_coefs.dta)在面板数据中,我们经常需要处理观测单位之间随时间变化而变化的不可观测的异质性。如果我们假设未观测到的异质性与自变量不相关,可以使用随机效应模型,否则,我们可以考虑固定效应。在实践中,通常将随机效应和固定效应结合起来实现混合效应模型。混合是指这些模型既包含固定效应又包含随机效应的事实。要使用随机效应模型,必须多次观察同一个人(面板数据)。如果未观察到的异质性与自变量相关,则随机效应估计量有偏且不一致。但是,即使预期未观察到的异质性与自变量相关,如果每个观察单位的观察次数非常少,固定效应模型标准误也可能较大,在这种情况下可以考虑随机效应。此外,通过在预测随机效应中使变量对自变量和随机效应之间的相关性进行建模可以解释这个问题。实现
我们从固定效果中的示例继续。在该示例中,我们估计了以下形式的固定效应模型:也就是说,在控制了时间和院校固定效应后,院校毕业生的平均收入取决于就业比例。但是,有些机构只有一个观测值,平均观测值是 5.1。我们可能会担心估计值的准确性。因此,即使认为  也可以选择使用机构截距的随机效应来估计模型。也就是说,我们选择偏差而不是方差的可能性。
也可以选择使用机构截距的随机效应来估计模型。也就是说,我们选择偏差而不是方差的可能性。R
可以使用几个包在 R 中实现随机效应模型,例如 lme4 和 nlme。lme4使用更广泛,下面的示例使用 lme4包。Stata
我们将使用内置的“xtreg”命令使用 Stata 估计一个混合效应模型。import delimited Scorecard.csv, clear
destring count_not_working count_working earnings_med, replace forceg prop_working = count_working/(count_working + count_not_working)encode inst_name, g(name_number)使用带有“re”选项的xtreg对机构截距进行随机效应回归。使用name_number 的随机效应(由re表示)和年份固定效应(使用 i.year添加)进行回归。xtreg earnings_med prop_working i.year, re我们注意到,与固定效应模型相比,我们的估计更精确。但是,X 和误差项之间的相关性表明随机效应模型存在偏差,不过,我们确实看到估计的beta 值大幅增加。*完整版code放在计量社群里的,可以自行下载运行。
1.免费4门课程, 因果推断1和2, IV, 份额移动IV,2.哈佛“数据科学导论”课程对所有人免费开放!包括机器学习和回归分析等各种方法!3.加拿大经济学会主席的"机器学习"课程可以学习了! 共计20份Slides直指ML前沿!4.耶鲁开设“应用实证方法”P.hd课程, 强逻辑, 好文献, 重实操, 真前沿, 送slides和笔记!5.
诺奖得主Angrist的因果推断课程文献读物单子再次更新了, 还提供了其他三门课程,6.全面且前沿的因果推断课程, 提供视频, 课件, 书籍和经典文献,7.美国博士用4年整理了写论文的各章实用资料, 包括课程, 软件, 研究, 投稿和工作等,8.MIT经济系50门开放课程对中国学者开放, 包括计量经济学等各类经济学课程!9.MIT斯隆商学院研究生课程对国内免费开放, 在家就能学习世界一流商学院的课程!10.从入门到进阶的Python数据分析手册, 课程内容完全免费!11.疫情期计量课程免费开放!面板数据, 因果推断, 时间序列分析与Stata应用
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
2.5年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle
计量经济圈组织了一个计量社群,有如下特征:热情互助最多、前沿趋势最多、社科资料最多、社科数据最多、科研牛人最多、海外名校最多。因此,建议积极进取和有强烈研习激情的中青年学者到社群交流探讨,始终坚信优秀是通过感染优秀而互相成就彼此的。












