来源:EETOP编译整理
当谈到人工智能/机器学习(AI/ML)时,开发人员通常会求助于基于 GPU 的加速器,而不是通用处理器 (CPU)。这些开发人员必须在专用硬件上进行大量投资,而当下一代算法出现时,这些硬件的价值往往会下降。
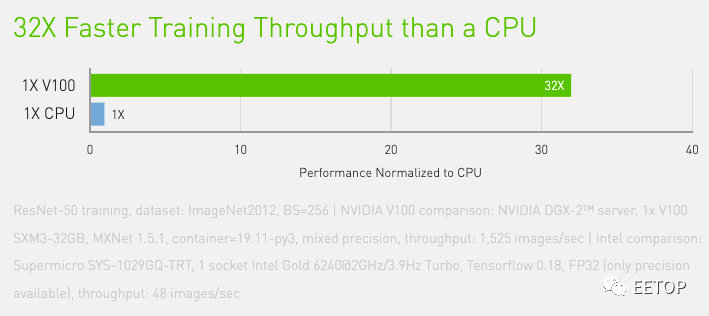
NVIDIA 宣称 V100 的训练吞吐量是普通 CPU 的 32 倍
致力于降低人工智能深度学习成本的初创公司ThirdAI表示,有一种更好的方法。ThirdAI最近筹集了600万美元,用于进一步研究自己的深度学习方法。脱离莱斯大学后,该公司推出了 SLIDE(次线性深度学习引擎),这是一种部署在通用 CPU 上的算法,旨在对抗 GPU 的主导地位。 据称,SLIDE算法在CPU上获得的训练结果比在英伟达V100等硬件加速器上更快。性能更高的CPU对下一代GPU意味着什么? 这家初创公司的最大诉求是什么?
ThirdAI的背景
凭借其独特的“SLIDE”算法,ThirdAI 计划改变现有的 AI 深度学习范式。
ThirdAI由副教授AnshumaliShrivastava共同创办,它的成功源于莱斯大学的研究。

ThirdAI 联合创始人 Anshumali Shrivastava
最初的大学研究已经显示出与GPU硬件相当的结果,但却受到了高速缓存的阻碍。不过随后英特尔介入了进来。Shrivastava解释说。
" 英特尔告诉我们,他们可以与我们合作,使其训练得更快,现在看来他们是对的。在他们的帮助下,我们的结果提高了约50%。"
SLIDE,即亚线性深度学习引擎,是一种 "智能 "算法,有可能取代大规模深度学习应用的硬件加速器。最终,ThirdAI的目标是利用算法和软件创新从处理器中榨取出更多性能。SLIDE的主要性能指标
据称,SLIDE比现有最好的Tensorflow GPU硬件快3.5倍,比Tensorflow CPU的性能提高10倍。尽管研究人员使用的CPU型号还不太清楚目前可知使用的一个"44核 "CPU。
分析下拉英特尔至强22核处理器E5-2699V4与莱斯大学研究人员使用的处理器最为接近的。这个CPU是一个22核44线程的处理器。不管确切的CPU是什么,SLIDE声称是人工智能训练的一个突破性算法。那么,它是如何工作的呢?
次线性深度学习引擎的内部工作原理
在最基本的层面上,SLIDE 使用采样哈希表,特别是修改后的局部敏感哈希(LSH),来快速查询神经元 ID 以进行激活,而不是逐个矩阵计算整个网络矩阵。它将这种技术与另一种称为自适应 dropouts 的技术相结合,后者用于提高神经网络中的分类性能。
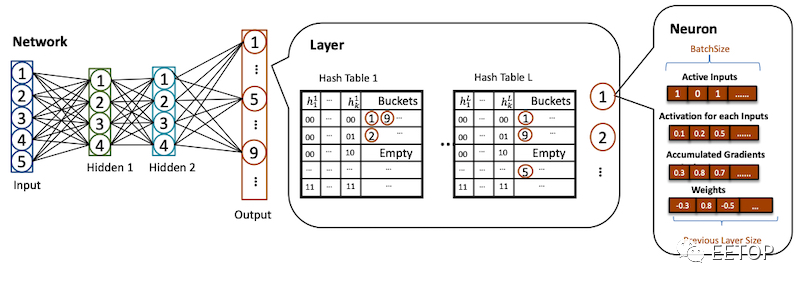 使用散列进行特定神经元采样
使用散列进行特定神经元采样
由于它可以查询特定的神经元,据说 SLIDE 克服了 AI 深度学习中的一个主要限制:样本大小(batch size)。 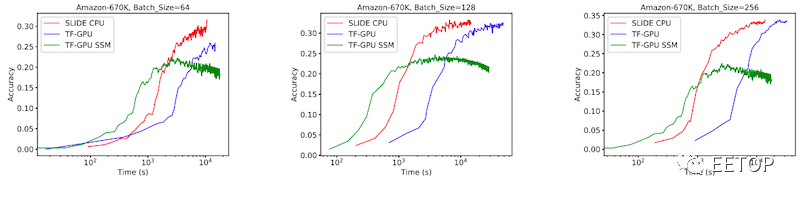
无论batch size如何,SLIDE 都保持着时间上的优势
通过使用多核 CPU 处理和优化——以及局部敏感散列 (LSH) 和adaptive dropouts——SLIDE 实现了O(1) 或恒定时间复杂度,无论batch size如何。
深度学习CPU 会翻身么?
硬件加速器价格昂贵,高端平台的成本超过 100,000 美元(而 E5-2699V4 为 4,115 美元)。对成本高昂的高性能图形处理器的需求让英伟达(NVIDIA)等制造商变得更加强大。
然而,随着 AI 训练数据集的不断增长,每次收敛所需的矩阵乘法也在不断增长。当 AI 模型发生变化时,为运行当前 AI 模型而对专用硬件的投资可能会很快失效。
最后,由于成本在工程中占主导地位,在通用处理器上运行工业规模的深度学习的能力可能是一个“杀手锏”。如果 SLIDE 继续被证明是可行的,那么像英特尔这样的公司可能会长期获得回报。
原文:
https://www.allaboutcircuits.com/news/software-startup-thirdai-reimagines-cpus-not-gpus-as-host-for-advanced-ai/
关注创芯人才网,搜索职位









