 1 引言
1 引言
在数字化时代,数据作为核心资源蕴含重要价值,网络爬虫成为企业洞察市场趋势、学术研究探索未知领域的重要技术手段。然而爬虫实践中常面临技术挑战,例如某电商企业通过爬虫获取竞品数据时,因高频请求触发目标平台 IP 封锁机制导致采集中断。
IP 代理在网络爬虫中发挥关键作用:通过分布式请求分散访问压力,可规避单 IP 高频访问限制并突破地域内容获取限制;同时能隐藏真实 IP 地址降低法律风险,模拟多用户行为特征优化反爬虫策略,有效平衡数据获取需求与网络访问规则。这种技术工具通过突破技术限制、提升采集效率、保障数据安全等多维价值,成为网络爬虫体系中的重要组成部分。
本文将介绍代理IP在网络爬虫中的重要性,并结合实际应用。
2 代理IP的优势
强大的架构性能:采用高性能分布式集群架构,具备无限并发能力,不限制并发请求,能完美满足多终端使用需求,为各类业务稳定运行提供坚实保障。
丰富的功能配置:支持多种代理认证模式,同时兼容 HTTP、HTTPS 以及 socks5 协议。还提供 API 接口调用与可视化监控统计功能,为用户业务开展提供极大便利。
优质的资源保障:拥有千万级优质住宅代理 IP 池,实时更新来自 200 多个国家的真实家庭住宅 IP。这些 IP 具有高效率、低延迟的特点,且能提供超高私密性,有力保障数据安全。
个性化的定制服务:兼顾个人和企业用户的专属需求,支持根据业务场景定制独享 IP。 这个团队提供 24 小时服务与技术支持,全方位满足用户多样化业务需求。
3 获取代理IP账号
这里我们可以选择进入官网网站,获取账号
在测试前,我们记得实名认证一下,这样我们就可以享受500M测试的额度了,接下来我们简单演示一下使用账密认证的形式获取代理~
在获取代理前,我们首先要创建一下子账号,这里的用户名和密码都要采用字母+数字

接下来我们就可以获取代理信息了,前往获取代理,然后选择账密认证。这里选择所需的地区、子用户、粘性会话、代理协议以及我们需要的其他参数,我这里默认
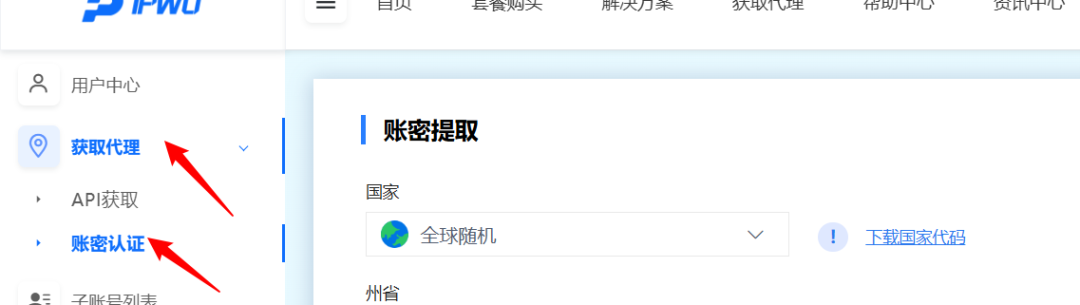
生成代理信息,完成前面的设置后,我们将获得代理信息。请复制提供的详细信息并在您的代理软件中配置使用。

套餐选择一般有两个选项动态住宅代理和静态住宅代理,当然我相信很多人是不了解这两个的,这里我简单的介绍一下
动态住宅代理的 IP 地址处于不断变化之中,这使得它在模拟多样化用户行为、规避网站访问限制等方面表现出色,像网络爬虫、广告验证等场景常能看到它的身影。其成本往往根据使用量或时长而定,相对较为灵活,价格一般不算高,还能为用户提供较好的匿名性保护,不过在速度和稳定性上可能会有一些波动。
静态住宅代理有着固定不变的 IP 地址,在速度和稳定性方面更具优势,适用于对网络质量要求高的网站测试、电商监控等场景。由于其资源的特殊性,价格通常偏高,而且因为 IP 固定,相对容易被追踪,匿名性稍弱。
此外官方还设置了许多使用教程,感兴趣的小伙伴可自行查阅!
接下来让我们进入爬取实战环节。
4 爬取实战案例—(某电商网站爬取)
4.1 网站分析
这是一个海外电商平台,今天我想要获取下面图中一些信息,这里选取的关键词是:IPhone 16
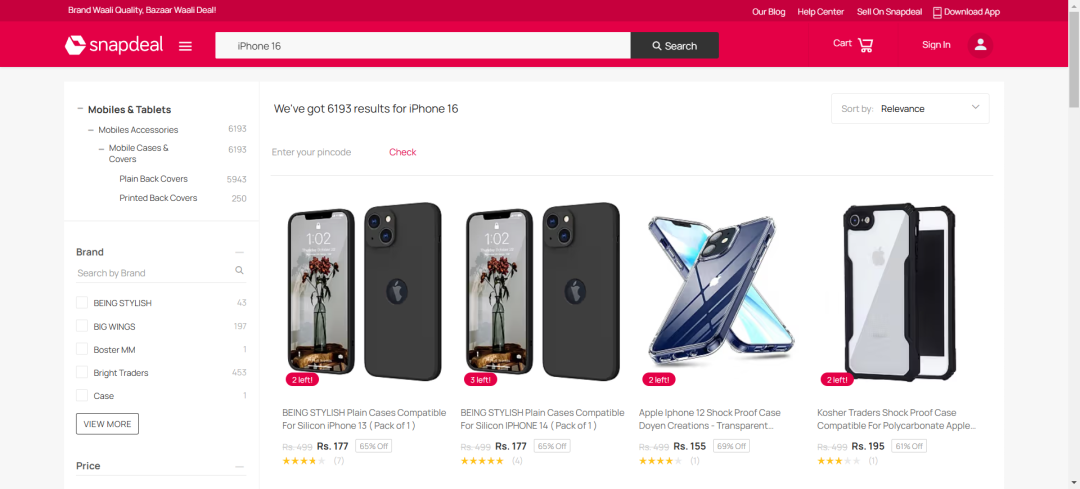
接下来我们想要获取商品的:title、price、link,如何获取呢,我们可以选择点击键盘上的F12,之后我们就可以按照下面的示例,进行选中对应的块了
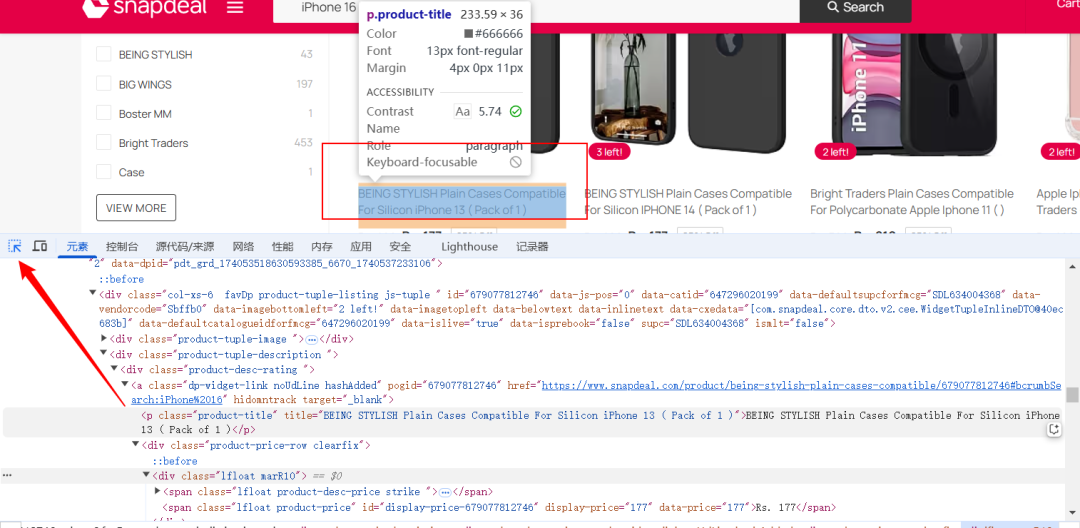
这里我们选择通过soup.find_all(‘div’, class_=‘product-tuple-listing’)来查找所有的商品块
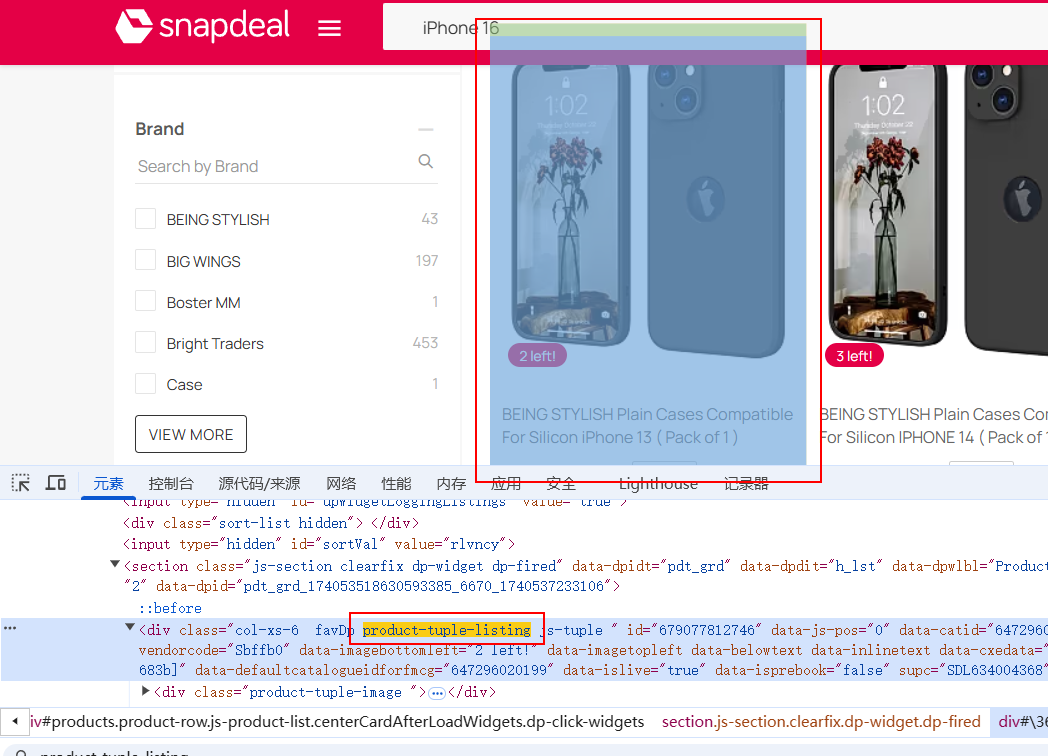
每个商品块包含了:
上面是简单的网站结构分析,下面我们进行实战
4.2 编写代码
1、首先我们需要导入库,这里我们导入requests和bs4,这两种库
import requestsfrom bs4 import BeautifulSoup
2、其次设置请求头,如下
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',}
3、模拟浏览器请求。很多网站会根据请求头来判断请求是否来自浏览器,以防止自动化脚本等的访问。这里你也可以选择多设置几个

4、之后我们确定目标 URL,这里是可以变动的,但是如果变动过大的话,后面对应的结构也得变动
5、获取页面的内容,requests.get(url, headers=headers):发送 GET 请求到 Snapdeal 网站,获取网页内容。
response.text:获取返回的 HTML 内容。BeautifulSoup(response.text, ‘html.parser’):使用 BeautifulSoup 解析 HTML 内容。'html.parser' 是解析器,BeautifulSoup 会将 HTML 内容转换成一个可以通过 Python 代码进行操作的对象。
response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser')
6、定义提取商品信息的函数,这里使用find_all函数
def extract_product_info(): products = [] product_elements = soup.find_all('div', class_='product-tuple-listing')
这里设置products = []:初始化一个空列表,用来存储商品信息。
soup.find_all('div', class_='product-tuple-listing'):通过 BeautifulSoup 找到所有符合条件的 div 元素,这些 div 元素是每个商品的容器。根据页面的结构,每个商品信息都被包含在一个 div 标签中,其类名为 product-tuple-listing。
7、接下来就是for循环遍历了
import requestsfrom bs4 import BeautifulSoup
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',}
url = 'https://www.snapdeal.com/search?keyword=iPhone%2016&santizedKeyword=Sony&catId=0&categoryId=0&suggested=false&vertical=p&noOfResults=20&searchState=&clickSrc=go_header&lastKeyword=&prodCatId=&changeBackToAll=false&foundInAll=false&categoryIdSearched=&cityPageUrl=&categoryUrl=&url=&utmContent=&dealDetail=&sort=rlvncy'
response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')
def extract_product_info(): products = []
product_elements = soup.find_all('div', class_='product-tuple-listing')
for product in product_elements: title = product.find('p', class_='product-title').text.strip() if product.find('p', class_='product-title') else None price = product.find('span', class_='lfloat product-price').text.strip() if product.find('span', class_='lfloat product-price') else None link = product.find('a', href=True)['href'] if product.find('a', href=True) else None
if title and
price and link: product_info = { 'title': title, 'price': price, 'link': f'https://www.snapdeal.com{link}', } products.append(product_info)
return products
products = extract_product_info()for product in products: print(f"Title: {product['title']}") print(f"Price: {product['price']}") print(f"Link: {product['link']}") print("-" * 40)
上面就是整个代码的核心步骤,下面我给出完整的代码
import requestsfrom bs4 import BeautifulSoup
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',}
url = 'https://www.snapdeal.com/search?keyword=iPhone%2016&santizedKeyword=Sony&catId=0&categoryId=0&suggested=false&vertical=p&noOfResults=20&searchState=&clickSrc=go_header&lastKeyword=&prodCatId=&changeBackToAll=false&foundInAll=false&categoryIdSearched=&cityPageUrl=&categoryUrl=&url=&utmContent=&dealDetail=&sort=rlvncy'
response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')
def extract_product_info(): products = []
product_elements = soup.find_all('div', class_='product-tuple-listing')
for product in product_elements: title = product.find('p', class_='product-title').text.strip() if product.find('p', class_='product-title') else None price = product.find('span', class_='lfloat product-price').text.strip() if product.find('span', class_='lfloat product-price') else None link = product.find('a', href=True)['href'] if product.find('a', href=True) else None
if title and price and link: product_info = { 'title': title, 'price': price, 'link': f'https://www.snapdeal.com{link}', } products.append(product_info)
return products
products = extract_product_info()for product in products: print(f"Title: {product['title']}") print(f"Price: {product[
'price']}") print(f"Link: {product['link']}") print("-" * 40)
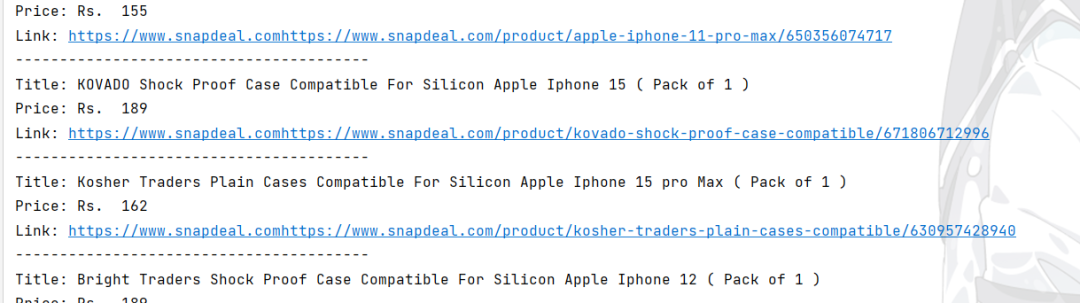
下面是运行的结果:
4.3 优化代码
接下来我们使用代理再试试,下面是官方为我们提供的关于Demo示例,从代码来看,还是十分简洁明了的
import requestsif __name__ == '__main__':proxyip = "http://username_custom_zone_US:password@us.ipwo.net:7878"url = "http://ipinfo.io"proxies = {'http': proxyip,}data = requests.get(url=url, proxies=proxies)print(data.text)
接下来我们再根据提供的代码示例,从而优化我们的代码,下面是完整的代码阐述
import requestsfrom bs4 import BeautifulSoup
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',}
proxyip = " " proxies = { 'http': proxyip,}
url = 'https://www.snapdeal.com/search?keyword=iPhone%2016&santizedKeyword=Sony&catId=0&categoryId=0&suggested=false&vertical=p&noOfResults=20&searchState=&clickSrc=go_header&lastKeyword=&prodCatId=&changeBackToAll=false&foundInAll=false&categoryIdSearched=&cityPageUrl=&categoryUrl=&url=&utmContent=&dealDetail=&sort=rlvncy'
response = requests.get(url, headers=headers, proxies=proxies, verify=False) soup = BeautifulSoup(response.text, 'html.parser')
def extract_product_info(): products = []
product_elements = soup.find_all('div', class_='product-tuple-listing')
for product in product_elements: title = product.find('p', class_='product-title').text.strip() if product.find('p', class_='product-title') else None price = product.find('span', class_='lfloat product-price').text.strip() if product.find('span', class_='lfloat product-price') else None link = product.find('a', href=True)['href'] if product.find('a', href=True) else None
if title and price and link: product_info = { 'title': title, 'price': price, 'link': f'https://www.snapdeal.com{link}', } products.append(product_info)
return products
products = extract_product_info()for product in products: print(f"Title: {product['title']}")
print(f"Price: {product['price']}") print(f"Link: {product['link']}") print("-" * 40)
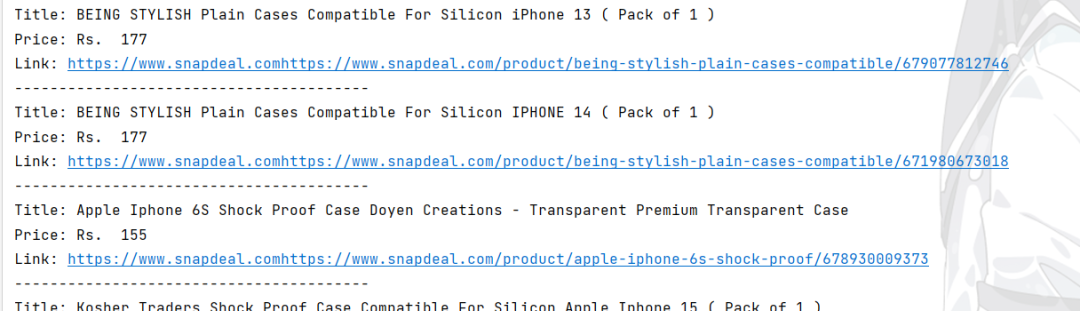
下面是运行结果:
5 总结
通过本文的介绍,我们可以清楚的了解并认识到代理在网络数据采集是十分重要的,针对snapdeal电商平台的商品数据采集,发现了IPWO的强大之处,使我们进行网络数据采集的时候,效率大大的提高~
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
整理出了一套系统的学习路线,这套资料涵盖了诸多学习内容:开发工具,基础视频教程,项目实战源码,51本电子书籍,100道练习题等。相信可以帮助大家在最短的时间内,能达到事半功倍效果,用来复习也是非常不错的。
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉Python学习视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。
资料获取方式:↓↓↓↓
1.关注下方公众号↓↓↓↓,在后台发送:“python” 即可免费领取
领取2025最新Python零基础学习资料,
 后台回复:python
后台回复:python








