导读
扩散模型最近彻底改变了图像生成领域,能够提供高质量、多样化且逼真的视觉内容。它们不仅支持文本到图像的生成,还能完成从基于布局的合成到图像编辑和风格迁移等广泛的任务。当然,这些大型模型需要大量的训练数据、较长的训练时间和丰富的计算资源。因此,当代的文本到图像(T2I)模型由于受限于其训练数据,在生成用户特定概念或更新内容时面临困难。
简介
扩散模型能够实现高质量且多样化的视觉内容合成。然而,它们在生成罕见或未见概念时面临困难。为应对这一挑战,我们探索了将检索增强生成(RAG)应用于图像生成模型的方法。我们提出了 ImageRAG,这是一种基于给定文本提示动态检索相关图像,并将其作为上下文来引导生成过程的方法。先前使用检索图像来改进生成的方法,专门为基于检索的生成训练模型。相比之下,ImageRAG 利用了现有图像条件模型的能力,无需进行特定于 RAG 的训练。我们的方法具有高度适应性,可应用于不同类型的模型,在使用不同基础模型生成罕见和细粒度概念方面显示出显著改进。
方法与模型
我们的目标是提高文本到图像(T2I)模型的鲁棒性,尤其是在处理罕见或未见过的概念时,这些概念是模型难以生成的。为此,我们研究了一种检索增强生成方法,通过该方法我们动态选择能够为模型提供缺失视觉线索的图像。重要的是,我们关注的是那些未针对检索增强生成(RAG)进行训练的模型,并表明现有的图像条件工具可以在事后用于支持 RAG。如图 3 所示,给定一个文本提示和一个 T2I 生成模型,我们首先根据给定的提示生成一张图像。然后,我们将该图像输入到一个视觉语言模型(VLM)中,并询问它该图像是否与提示匹配。如果不匹配,我们的目标是检索代表图像中缺失概念的图像,并将它们作为额外的上下文提供给模型,以引导模型更好地与提示对齐。在接下来的章节中,我们通过回答关键问题来描述我们的方法:(1)我们如何知道要检索哪些图像?(2)我们如何检索所需的图像?(3)我们如何使用检索到的图像来生成未知概念?通过回答这些问题,我们实现了生成模型自身难以生成的新概念的目标。
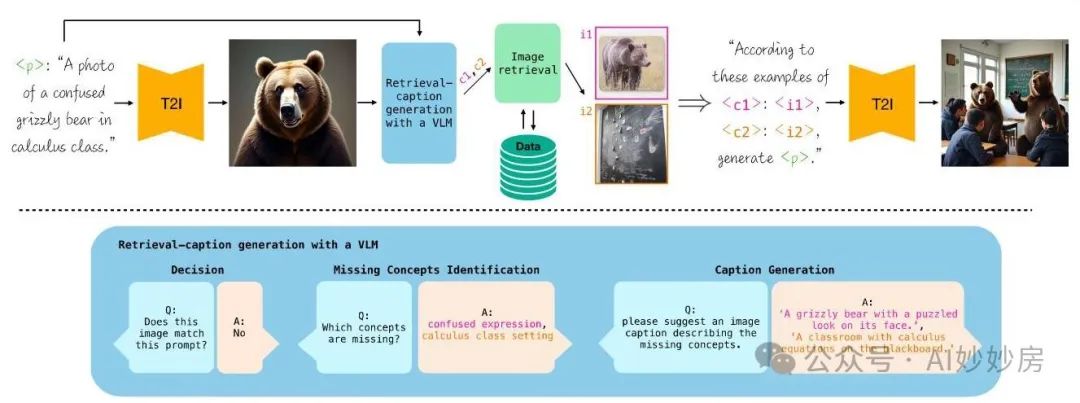
图 3:顶部:我们方法的高层概述。给定一个文本提示 ,我们使用文本到图像(T2I)模型生成一张初始图像。然后,我们生成检索描述 ,针对每个描述 从外部数据库中检索图像,并将它们作为模型的参考以实现更好的生成。底部:检索描述生成模块。我们使用视觉语言模型来判断初始图像是否与给定提示匹配。如果不匹配,我们要求它列出缺失的概念,并为每个缺失的概念创建一个可用于检索合适示例的描述。
1. 要检索哪些图像?
我们可以传递给模型的图像数量是有限的,因此我们需要决定将哪些图像作为参考来引导基础模型的生成。由于 T2I 模型已经能够成功生成许多概念,一种有效的策略是仅将它们难以生成的概念作为参考传递,而不是提示中的所有概念。为了找到具有挑战性的概念,我们使用一个 VLM 并应用一种逐步的方法,如图 3 的下部所示。首先,我们使用 T2I 模型生成一张初始图像。然后,我们将初始提示和图像提供给 VLM,并询问它们是否匹配。如果不匹配,我们要求 VLM 识别缺失的概念,并关注内容和风格,因为这些可以通过视觉线索轻松传达。如表 3 所示,实证实验表明,从详细的图像描述中进行图像检索比从简短、通用的概念描述中进行检索能获得更好的结果。因此,在识别出缺失的概念后,我们要求 VLM 为描述每个概念的图像提供详细的图像描述。
1.1. 错误处理
视觉语言模型(VLM)有时可能无法识别图像中缺失的概念,并会回复“无法响应”。在这些罕见情况下,我们允许最多重复查询 3 次,同时每次重复时提高查询的温度。提高温度可以鼓励模型采样不太可能出现的词汇,从而产生更多样化的回复。在大多数情况下,使用我们建议的逐步方法比直接根据给定提示检索图像能取得更好的效果(见第 5.3 节)。然而,如果视觉语言模型在多次尝试后仍无法识别缺失的概念,我们会退而直接根据提示检索图像,因为这通常意味着视觉语言模型不理解提示的含义。
1.2. 如何检索所需的图像?
给定 个图像描述,我们的目标是从一个数据集中检索与这些描述最相似的图像。为了检索与给定图像描述匹配的图像,我们使用文本 - 图像相似度指标将该描述与数据集中的所有图像进行比较,并检索前 个最相似的图像。文本到图像检索是一个活跃的研究领域,目前没有一种单一的方法是完美的。当数据集中没有与查询完全匹配的内容时,或者当任务是依赖细微细节的细粒度检索时,检索尤其困难。因此,常见的检索工作流程是首先使用预计算的嵌入向量检索图像候选,然后使用另一种通常更昂贵但更准确的方法对检索到的候选进行重新排序(Vendrow 等人,2024 年)。按照这个工作流程,我们对不同嵌入向量的余弦相似度以及参考候选的多种重新排序方法进行了实验。虽然与简单地使用 CLIP(Radford 等人,2021 年)嵌入向量之间的余弦相似度相比,重新排序有时能产生更好的结果,但在我们的大多数实验中差异并不显著。因此,为了简单起见,我们使用 CLIP 嵌入向量之间的余弦相似度作为我们的相似度指标(有关我们使用不同相似度指标进行实验的更多详细信息,请参阅表 4、第 5.3 节)。
1.3 如何使用检索到的图像?
综上所述,在检索到相关图像后,剩下要做的就是将它们用作上下文,以便对模型有益。我们对两种类型的模型进行了实验;一种是除了文本之外还被训练为接收图像作为输入且具有上下文学习(ICL)能力的模型(例如,OmniGen(Xiao 等人,2024)),另一种是在训练后用图像编码器增强的文本到图像(T2I)模型(例如,带有 IP 适配器(Ye 等人,2023)的 SDXL(Podell 等人,2024))。由于第一种模型类型具有上下文学习能力,我们可以通过调整原始提示,将检索到的图像作为示例提供给它进行学习。虽然第二种模型类型缺乏真正的上下文学习能力,但它提供了基于图像的控制功能,我们可以利用我们的方法在其上应用检索增强生成(RAG)。因此,对于这两种模型类型,我们都增强输入提示,使其包含检索到的图像作为示例的引用。形式上,给定一个提示 概念,以及每个概念对应的 张兼容图像,我们使用以下模板创建一个新提示:“根据这些 的示例,生成 ”,其中 (对于 )是图像 的兼容图像说明。
这个提示允许模型从图像中学习缺失的概念,引导它们生成所需的结果。
个性化生成:对于支持多个输入图像的模型,我们也可以将我们的方法应用于个性化生成,以生成包含个人概念的罕见概念组合。在这种情况下,我们使用一张图像作为个人内容,使用 张其他参考图像来表示缺失的概念。例如,给定一张特定猫咪的图像,我们可以生成它的各种不同图像,从印有这只猫咪的马克杯到它的乐高模型,或者是一些非典型的场景,比如这只猫咪在编写代码或在教室里给一群狗狗上课(图 4)。

图 4:个性化生成示例。ImageRAG 可以与个性化方法并行工作,并增强它们的能力。例如,尽管 OmniGen 可以根据一张图像生成某个主体的图像,但它在生成某些概念时会遇到困难。使用我们的方法检索到的参考图像,它可以生成所需的结果。
2. 实现细节
我们使用 LAION(Schuhmann 等人,2022)的一个包含 张图像的子集作为我们检索图像的数据集。作为检索相似度指标,我们使用 CLIP “ViT - B/32”。对于视觉语言模型(VLM),我们使用 GPT - 4o - 2024 - 08 - 06(Hurst 等人,2024),并将温度设置为 0 以提高一致性(除非 GPT 无法找到概念,请参阅第 3.1.1 节)。完整的 GPT 提示在附录 A 中提供。作为我们的文本到图像(T2I)生成基础模型,我们使用带有 ViT - H IP 适配器(Ye 等人,2023)加版本(“ip - adapter - plus_sdxl_vit - h”)的 SDXL(Podell 等人,2024),ip_adapter_scale 设置为 0.5,以及使用默认参数(引导比例为 2.5,图像引导比例为 1.6,分辨率为 1024x1024)的 OmniGen(Xiao 等人,2024)。由于 OmniGen 仅支持 3 张图像作为上下文,我们为每个提示最多使用 个概念,每个概念使用 张图像。对于 SDXL,由于我们使用的 IP 适配器仅限于 1 张图像,我们使用 1 个概念和 1 张图像。
实验与结果
在本节中,我们描述了为评估我们方法的有效性而进行的定量和定性实验。为了评估其对不同模型类型的适应性,我们尝试将 ImageRAG 应用于两种模型,即 OmniGen(Xiao 等人,2024 年)和 SDXL(Podell 等人,2024 年),每种模型代表一种不同的类型。
1. 定量比较
我们通过比较 OmniGen 和 SDXL 的结果以及将 ImageRAG 应用于它们时的结果,来评估我们的方法改善稀有和细粒度概念的文本到图像(T2I)生成的能力。作为额外的基线,我们与 FLUX(Labs,2023 年)、Pixart - (Chen 等人,2025 年)和 GraPE(Goswami 等人,2024 年)进行比较。最后一种是基于大型语言模型(LLM)的迭代图像生成方法,它使用编辑工具插入缺失的对象。我们使用基于 OmniGen 的版本。我们使用每种方法在以下数据集中生成每个类别的图像:ImageNet(Deng 等人,2009 年)、iNaturalist(Van Horn 等人,2018 年)、CUB(Wah 等人,2011 年)和 Aircraft(Maji 等人,2013 年)。对于 iNaturalist,我们使用前 1000 个类别。表 1 显示了使用 CLIP(Radford 等人,2021 年)、SigLIP(Zhai 等人,2023 年)和 DINO(Zhang 等人)相似度对所有方法的评估结果。为了公平起见,我们使用开源 CLIP 进行评估,同时使用 OpenAI CLIP 进行检索。如表 1 所示,在使用我们的方法生成稀有概念和细粒度类别时,Omni - Gen 和 SDXL 的结果都有所改善。
2. 专有数据生成
检索增强生成(RAG)在自然语言处理(NLP)中的一个常见用途是基于专有数据进行生成(Lewis 等人,2020 年),其中检索数据集是专有的。在图像生成中类似的应用是基于专有的图像库生成图像。这可能是为了实现个性化,其中图像库包含个人概念,例如某人的狗的图像,或者它可能是公司品牌或私人图像收藏,可以拓宽模型的知识。我们基于 LAION 的实验探索了用户可以访问通用大规模数据集的场景。在这里,我们进一步评估当我们可以访问一个可能更小、更专业的数据集时 ImageRAG 的性能。因此,我们使用表 1 中使用的数据集重复实验,但这次是从每个数据集中检索样本,而不是从 LAION(Schuhmann 等人,2022 年)子集中检索。结果报告在表 2 和表 5 中。我们观察到,尽管使用来自 LAION 的相对较小子集的通用数据集应用我们的方法已经改善了结果,但当使用专有数据集进行检索时,结果会进一步改善。
3. 消融研究
为了评估我们方法各部分的贡献,我们进行了一项消融研究,测试不同的组件,并将结果列于表 3 中。首先,我们想确保性能差距并非仅仅基于使用大型语言模型(LLM)解读生僻词汇。因此,我们在不提供参考图像的情况下,对经过重新表述的文本提示评估了 OmniGen 和 SDXL。为此,我们让 GPT 重新表述提示,通过必要时明确要求将生僻词汇替换为其描述,使这些提示更适合文本到图像(T2I)生成模型。完整的提示可在附录 A 中找到。结果显示,重新表述提示不足以使结果有显著改善(表 3 中的“重新表述的提示”)。接下来,我们研究使用详细图像描述进行检索的重要性,而不是仅仅列出缺失的概念或使用原始提示。我们通过在不针对每个缺失概念生成兼容图像描述的情况下直接检索概念(表 3 中的“检索概念”),以及直接检索提示(表 3 中的“检索提示”)来评估我们的方法。虽然使用这两种方式进行检索相对于初始结果都有一定改善,但检索详细描述能进一步提升结果。
接下来,我们研究检索数据集大小的影响。我们在使用 LAION(Schuhmann 等人,2022)中的 1000、10000、100000 和 350000 个示例时,在 ImageNet(Deng 等人,2009)和 Aircraft(Maji 等人,2013)上测试了我们的方法。图 5 显示,增加数据集大小通常会带来更好的结果。然而,即使使用相对较小的数据集也能带来改进。对于 OmniGen,1000 个示例就足以使其优于基线模型。SDXL 的基线更强,因此需要更多的示例才能实现改进。
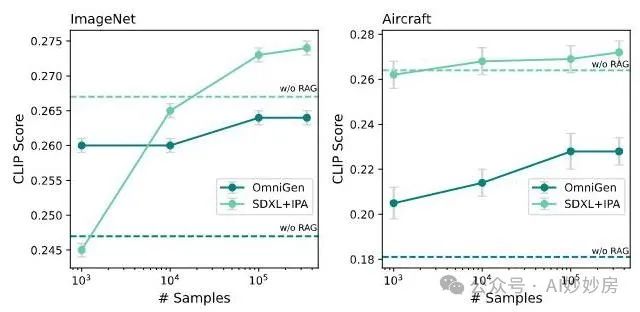
图 5:检索数据集大小与 ImageNet(左)和 Aircraft(右)上的 CLIP 分数对比。虚线表示基础模型的分数。即使是相对较小、未专门优化的检索集也能改善结果。更多的数据会使分数进一步提高。然而,小的数据集可能不包含相关的检索示例,使用它们可能会损害结果,尤其是对于更强的模型。
最后,我们研究不同相似性度量方法对检索的影响。我们使用了 CLIP(Radford 等人,2021)、SigLIP(Zhai 等人,2023),并对 GPT 为检索候选生成的图像描述使用 GPT(Hurst 等人,2024)和 BM25(Robertson 等人,2009)进行重新排序。在从 CLIP 和 SigLIP 各自检索 3 个候选后进行重新排序。结果列于表 4 中。虽然使用 GPT 重新排序产生的结果略好,但与更直接的 CLIP 度量方法相比,其改善程度不足以证明应用这种复杂策略的成本是合理的。因此,我们的其他实验使用 CLIP。尽管如此,所有不同的度量方法都通过提供有用的参考提高了基础模型的生成能力。
4. 定性比较
图 7 展示了来自 ImageNet(邓等人,2009 年)、CUB(瓦等人,2011 年)和 iNaturalist(范霍恩等人,2018 年)数据集的定性示例,比较了使用和不使用我们方法时 OmniGen 和 SDXL 的结果。
为了进一步评估我们结果的质量,我们进行了一项用户研究,有 46 名参与者,总共进行了 767 次比较。我们进行了两种类型的研究——一种评估使用和不使用我们方法时 SDXL 和 OmniGen 的情况,另一种将我们的结果与其他基于检索的生成模型进行比较。具体来说,我们将其与使用检索到的图像专门为图像生成任务训练的模型进行比较:RDM(布拉特曼等人,2022 年)、knn - 扩散(谢宁等人,2022 年)和 ReImagen(陈等人,2022 年)。由于这些大多是没有 API 的专有模型,我们将其与他们论文中发表的图像和提示进行比较。在这两种情况下,我们要求参与者一次比较两张图像:一张是用我们的方法创建的,另一张是使用基线方法创建的。我们要求用户根据对文本提示的遵循程度、视觉质量和总体偏好选择他们更喜欢的那张。由于一些提示包含不常见的概念,我们为用户提供每个提示中最不熟悉概念的真实图像(不取自我们的数据集)。在为用户研究运行 ImageRAG 时,我们禁用了询问 GPT 初始图像是否与提示匹配的决策步骤。这样做是为了避免在 GPT 认为初始图像很合适的情况下向用户展示同一张图像两次。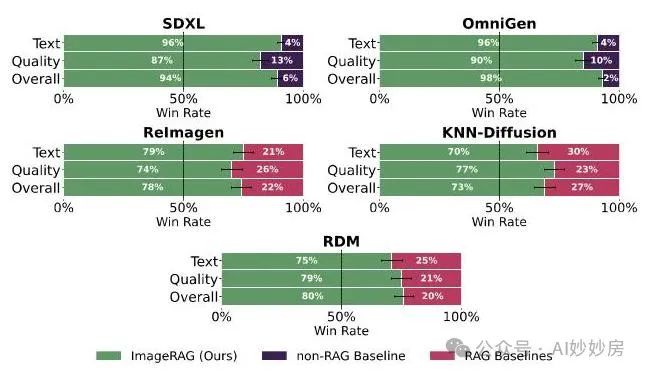
图 6:用户研究结果。与其他方法相比,用户在文本对齐、视觉质量和总体偏好方面对我们方法的偏好百分比。
如图 6 所示,在文本对齐、视觉质量和总体偏好这三个标准上,参与者都更青睐 ImageRAG 而不是所有其他方法。附录 提供了关于研究中所提问题的更多信息、每个基于检索的生成模型的视觉比较示例(图 8),以及使用和不使用 ImageRAG 时与 SDXL(图 9)和 OmniGen(图 10)的更多比较。图 11 展示了我们的方法在更复杂和有创意的提示下的额外视觉结果。
总结
在这项工作中,我们探索了如何通过一种简单而有效的方法,将检索增强生成(RAG)应用于预训练的文本到图像模型。我们表明,使用相关的图像参考可以提高文本到图像(T2I)模型生成稀有概念的能力,并展示了如何利用视觉语言模型(VLM)通过一种简单的方法动态检索相关参考。我们对代表两种模型类型的两个模型进行了实验,展示了我们的方法如何应用于多个不同的模型。我们得出结论,使用图像参考可以拓宽文本到图像生成模型的适用性,只需进行最少的修改就能增强生成的可能性。









