大家好,我是小寒
今天给大家分享机器学习中的一个关键概念,SHAP 值
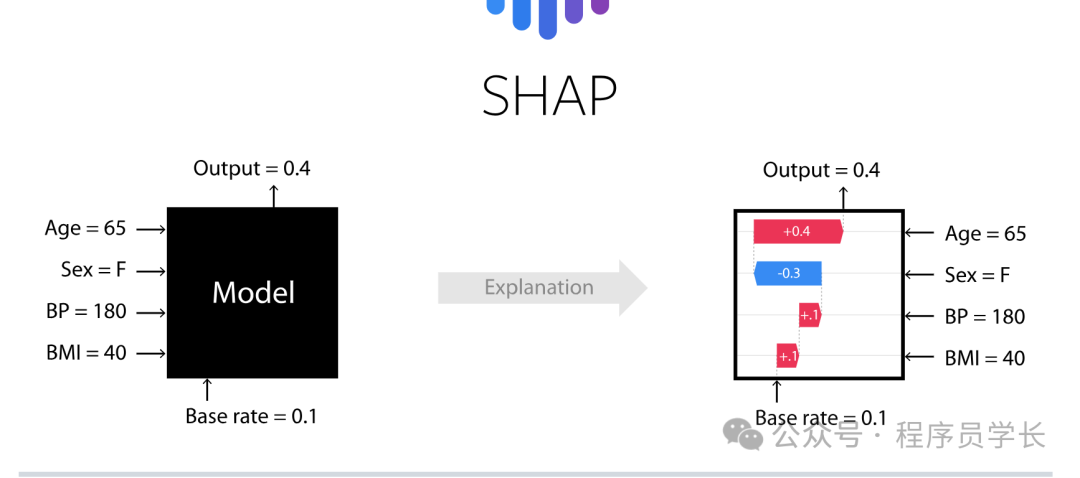
SHAP 值是一种用于解释机器学习模型的技术。它基于合作博弈论中的 Shapley 值概念,通过为每个特征分配一个"贡献值"来解释模型的预测结果。
SHAP 值提供了一种公平且理论稳健的方法来解释机器学习模型的行为,特别是在黑盒模型(如深度学习、集成方法等)中,这种解释方法非常有价值。
Shapley 值的理论背景
Shapley 值是由 Lloyd Shapley 于1953年提出的,它最初是用来衡量在合作博弈中,各个参与者对合作结果的贡献。
在机器学习中,特征被看作是博弈中的参与者,模型的预测结果则是合作博弈的总收益。
Shapley 值的核心思想是,计算每个特征在所有可能特征排列中的边际贡献,并基于这一贡献分配模型的预测结果。
Shap 值的计算
给定一个预测模型,假设模型的输入是一个特征向量 ,模型的预测结果是 。
Shap 值用来度量特征 对模型预测结果 的贡献。
数学公式如下所示
其中
- 是特征 的 Shap 值,表示特征 对最终预测结果的贡献。
- 是在特征子集 的基础上,加入特征
后的模型预测值。
解释过程
边际贡献
对于每个特征 ,其边际贡献是通过计算在包含该特征时的模型输出与不包含该特征时的模型输出之间的差异来确定的。
通过对所有可能的特征排列进行计算,Shap 值能够公平地分配每个特征对最终模型预测结果的贡献。
权重
公式中的 是每个排列的概率,它保证了每个特征在不同排列中的贡献都会被平等对待。这确保了 Shap 值的公平性。
这个公式的核心思想是,计算所有可能的特征组合,并分析某个特征在不同组合下的贡献,最终通过加权平均计算其 Shap 值。
然而,由于遍历所有子集的计算复杂度是指数级别,直接计算 SHAP 值在高维数据上是不现实的,因此 SHAP 提供了多种近似算法,能够在多种复杂模型下快速计算 SHAP 值。
近似 SHAP 值的方法
为了降低计算SHAP值的复杂度,研究人员提出了几种近似方法,其中最著名的包括。
- Kernel SHAP:一种通过采样和加权的方法,用于近似SHAP值的计算。
- Tree SHAP:针对树模型(如随机森林、XGBoost等)优化的SHAP计算方法,可以显著加快计算速度。
SHAP 值的加法性
SHAP 值是加法性的,这意味着每个特征的 SHAP 值可以直接加起来,以得到模型的预测结果。
设模型的预测值为 ,其中
是所有特征。则SHAP值满足:
其中, 是模型的基准预测值(例如,在没有任何特征时的预测值),而 是每个特征 对预测的贡献。
SHAP 值通过这种加法性确保了各个特征的贡献可以独立计算并加和,得到模型的最终预测。
SHAP 值的应用
SHAP 值可以应用于多种领域
模型可解释性
SHAP 值可以用来解释复杂模型(如深度学习模型、XGBoost、随机森林等)在个体预测中的决策过程,帮助理解模型如何依赖每个特征。
特征选择
通过评估不同特征的 SHAP 值,可以筛选出对模型预测最重要的特征。
公平性和合规性
SHAP值有助于提高机器学习模型在实际应用中的透明度,尤其在涉及到金融、医疗等领域时,SHAP值可以帮助确保模型的决策过程符合监管要求。
SHAP 值的优点
SHAP 值相较于其他解释方法(如LIME)有几个重要的优点
-
理论基础:SHAP 值基于博弈论中的Shapley值,具有明确的理论基础,确保解释结果的公平性。
- 一致性:SHAP 值满足一致性原理,如果某个特征在所有情况下对模型预测的贡献都增加,那么其SHAP值也不会减少。
- 模型无关性:SHAP值适用于各种类型的模型,包括线性模型、树模型、深度学习模型等。
案例分享
下面是一个使用 SHAP 值来解释 XGBoost 模型预测结果的完整示例代码。
这个示例将展示如何训练一个 XGBoost 模型,并使用 SHAP 值来解释模型的预测。
import shap
import xgboost as xgb
import pandas as pd
import numpy as np
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 加载糖尿病数据集
data = load_diabetes()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化特征
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 创建并训练 XGBoost 模型
model = xgb.XGBRegressor(objective='reg:squarederror', random_state=42)
model.fit(X_train_scaled, y_train)
# 使用 SHAP 解释模型
explainer = shap.Explainer(model, X_train_scaled) # 创建解释器
shap_values = explainer(X_test_scaled) # 计算 SHAP 值
# 可视化 SHAP 值的汇总图
shap.summary_plot(shap_values, X_test_scaled, feature_names=X.columns)

Force Plot
解释单个样本的预测贡献
shap.initjs() # 初始化 JavaScript 环境
sample_index = 10 # 选择某个测试样本
shap.force_plot(explainer.expected_value, shap_values[sample_index].values, X_test.iloc[sample_index])

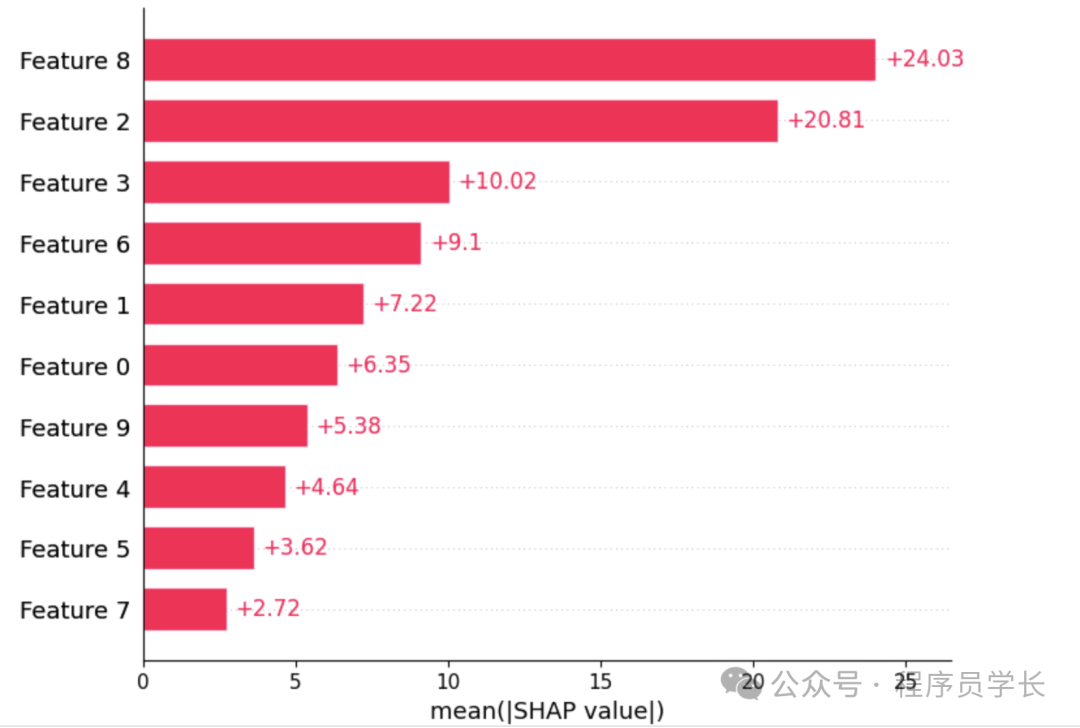
Bar Plot
SHAP 条形图,观察特征重要性
shap.plots.bar(shap_values)