来源:古月居
强化学习,又叫Reinforcement learning,简称RL。在现在的AI研究中,RL相信大家一定都会经常听到。并且在很多的一些项目中也用到了RL的技术。比如阿尔法狗等。
我们前面所学到的,实际上使用的都是监督学习的算法。不管怎么说,我们实际上都是给了它们一个label标签的。不管是CNN,或者是RNN,又或者是GAN,包括自监督学习等等。
但是RL所研究领域,就和这有所不同了,因为有的时候机器并不知道做哪一步是最好的,或者说我们不知道最佳输出应该是什么。举例来说,我们一个13-13的棋盘,在对手下了一个子后,你能够很确定的给出下一步应当走哪里最好吗?这个label应该怎么给呢?可能人类自己都不知道。你或许可以说可以参照什么棋谱来去学习观察来确定落在哪里最好。但是你又能确定落在这里一定是最好的吗、棋谱上所写的一定是最好的吗?我们并不知道。所以说,这样的label标注工作是很难的。
在你不知道正确答案是什么样的情况的问题下,往往RL或许就能派上很好的用场。
当然,机器也并不是一无所知的。我们虽然不知道正确答案是什么,但是我们还是知道,相对来说,哪里好或者哪里不好。机器会跟环境做互动,得到一个叫Reward的东西。也就是说,机器是可以通过和环境进行交互,并且知道什么样的结果是好的,什么样的结果是不好的,从而学习得到一个模型。
RL和我们之前所学习的机器学习的算法一样,同样是遵循三个步骤。
在我们的RL里面,会有一个Actor,会有一个Environment,那么这个Actor会和Environment进行互动。
具体来说,如下图,环境会给Actor一个Observation,这个就是会作为Actor的输入,然后这里的Actor,就是作为一个Function来去存在的。而产生的Action就是Actor的输出。也就是说,Actor作为一个函数,将从环境得到的Observation作为输入、并经过变换后产生Action作为输出。
而这个产生的Action呢,又会对环境产生影响。那么环境就会基于新的Observation给Actor,然后Actor呢再产生新的Action。
而在这样一个过程中,环境会不断地给Actor一些Reward来告诉Actor,你的这个Action好不好。
那我们就可以说,我们就是要找一个函数function,它以Observation作为输入,Action作为输出,以最大化Reward为目标。注意这里的Reward应当为从环境中得到的环境激励总和。
假如说上面的描述比较抽象,那我们就通过具体的例子来去描述。我们可以来举一个Space invader的例子,如下图。
在这里,我们左上角的分数,就是相当于Reward,然后我们的Action有向左、向右和开火三个选择。我们的目标是要通过开火把所有的外星人都干掉,同时,我们也会拥有护盾来抵御外星人的攻击。游戏结束的条件是所有的外星人都被干掉或者你的被外星人击中。当然了,也可能在有的版本里面,会给个补给包什么的然后击中也会有积分加成。
那么,我们如果用上面的模型那个来去描述这个游戏,它就是这个样子(如下图):
它的observation就是游戏主机中一张一张的游戏图像画面,而它的Action有三个,分别为向左、向右和开火。当开火打中外星人的时候,环境将会给Actor简历,假如说给的reward是5,然后向右和向左我们都给0分。那么我们总的任务,就是要训练出Actor使得它能够在一整个游戏中所获得的reward是最大的。
然后我们再来举一个AlphaGo的例子:在AlphaGo下围棋的时候,它的环境就是它的人类对手,而它的输入就是棋盘上黑子和白子的相对位置,然后它的输出呢,就是下一个将要落子的位置,每一种可能性都会对应棋盘上的一个位置,这很容易理解。
选定落子位置后,落子,那么接下来将这个落子后的棋盘反馈给环境,再由环境产生新的Observation(这一个过程即人类对手又下了一步棋),把它用作Actor的输入,进而产生新的Action,如此循环反复下去。
那么就目前而言,我们可以认为,对于下棋这件事情,在绝大多数情况下,reward都是0,只有当你赢了的时候,才会得到reward,我们假设为1分;倘若你输了,那么reward就是-1分。
那Actor所学习的目标就是要去最大化它的reward,也就是要它赢。当然了,我们会在后面说到,我们可以通过一些其他的方式,例如spare reward的方式,来去进一步细化和优化每一步落子的方式。直接用这种方式硬train,肯定还是过于粗糙了的。
如上图所示,就是我们说的Alpha Go的下棋的例子,在绝大多数情况下,reward都是0,只有当你赢了的时候,才会得到reward,我们假设为1分;倘若你输了,那么reward就是-1分。
那希望通过这样一种架构,能够帮助大家搞清楚一整个RL的流程是怎么样。
我们前面在学习机器学习的时候就已经进行了探讨,说,机器学习一共需要经历三个步骤,即找一个带有位置参数的函数、定义Loss函数、最佳化。
那么RL也同样遵循这三个步骤。
一、找一个含有未知参数的函数
我们前面说到过,我们要找的这个含有未知参数的函数,实际上就是Actor。那Actor又是什么呢?它实际上就是一个Network,我们现在通常叫它为Policy的Network。在过去Network还没有被用到Actor的时候,它可能就只是一个Look-Up-Table,就相当于Key-Value一样,即看到什么样的结果就产生什么样的输出。
那我们今天已经知道我们的function就是一个复杂的network。
在我们上面所举的例子中,输入就是我们的pixels(像素),然后输出就是每一个行为的分数。
我们可以看到,它实际上和Classification有着非常类似的地方。
举例来说,在我们刚刚的那个例子中,我的输入就是我的pixels,我的输出就是向左、向右或者开火的选择,它们的分数就表示着一个可能性。
在这里的Network应该是怎样的呢?那就需要你自己来去设计了。比如说当你输入的是一张图片的时候,那你就会想要用CNN来去处理。当然,当你需要看的是整场游戏到目前为止所发生的所有事情,那么你所需要的可能就是RNN。当然,你也可以用Transformer等。
那最终机器决定采用哪一个Action,取决于最后得到的概率;注意,这些最后的分数只表示其做这些动作的概率。具体机器要去做哪一个Action,实际上是需要机器按照这个概率去sample的。也就是说,这些分数它只代表一个概率,对于每一个样本它所采取的行为是什么,它具有一定的随机性;这里的分数只是能够代表其发生的可能性。这样做的好处,就是说今天你即便是相同的游戏画面,也可能有不同的动作,那么这样的随机性可能对于某些游戏而言是重要的。比如石头剪刀布。
我们思路回到这一个大步骤上,也就是说,我们第一步就是要找一个带有未知参数的Function,那么这个Function实际上就是带有未知参数的Network,就是我们要学出来的东西。也就是我们的Actor。
二、定义Loss
那么假如我们现在有这样的情景了(如下图):
我们一开始有了一个画面,假如我们叫它s1,然后经过Actor之后,它得到了行为a1(我们假设该动作是右移),然后由于没有杀死任何一个外星人,所以得到了一个reward = 0;然后右移之后形成了新的observation,我们假设叫它s2,然后这个s2又作为Action的输入,假设经过Actor之后,得到行为a2(我们假设该动作是开火),我们假设它杀死了一个外星人,然后得到一个reward = 5;紧接着得到新的observation s3,然后机器再采取新的行为...像这样机器(Actor)和环境反复互动下去,直到终止条件为止。这就是一个episode。
那么在这样一些过程中,机器可能会采取很多的行为,而每一种行为都会有其对应的reward,那么我们的任务就是要让将所有的reward集合起来,从而让整个游戏的Total reward(或者叫return)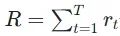 最大。那么这里的 R 就是我们要最大化的东西。当然,如果你想要和之前的Loss的习惯一致,即想让其最小化、求其最小值的话,我们只需要在 R 的前面加个负号就可以了。
最大。那么这里的 R 就是我们要最大化的东西。当然,如果你想要和之前的Loss的习惯一致,即想让其最小化、求其最小值的话,我们只需要在 R 的前面加个负号就可以了。
具体来说,有关于评判一个Actor好坏的判断标准:
实际上和最大似然估计很相似。假设我们可以穷举所有的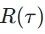 ,那我们 Rθ 的期望就可以表示为
,那我们 Rθ 的期望就可以表示为 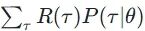 。而假设我们sample出来了n个 ,那么我们sample出来的这n个应当是和
。而假设我们sample出来了n个 ,那么我们sample出来的这n个应当是和 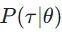 成正比关系的,也因此, Rθ=
成正比关系的,也因此, Rθ=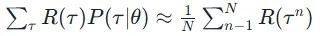
注意,我们后面所学的(比如MC、TD等,比如如何来确定一个 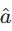 ),是在评价一个Action的好坏,而不是在评价一个Actor的好坏。
),是在评价一个Action的好坏,而不是在评价一个Actor的好坏。
三、Optimization(优化)
我们再用下面的图示来表示一下:
环境给Actor一个s1,然后s1经过Actor后得到动作a1,那么a1再经过环境变换后得到s2,然后s2再经过Actor得到a2...以此类推;然后我们将s1,a1,s2,a2...这样在同一个episode内的所有action和observation我们叫做一个trajectory;我们将s1和a1经过Reward函数得到 r1,也就是说,这里的r1不仅仅和a1有关,也和s1有关。理由也很简单。因为有的时候这个动作必须在特定的环境下才会得分。比如你开火,必须能打到外星人才能得分。
然后我们用R来表示所有得分的总和。我们的目标就是让这里的R最大。
那Optimization具体问题是什么呢?就是要在Actor的Network里找一组参数,把这一组参数代入到Actor之后,能使得得到的Reward最大。就这样,就结束了。这就好像循环神经网络一样。
但RL与之不同、或者是说有挑战性的地方在于:
1、你的a1、...是sample出来的,也就是说,它就只是一个样本,它是具有一定的随机性的。每次给定一样的s1所产生的a1不一定一样。
2、我们的Env和Reward它们不是Network。它们就仅仅是一个黑盒子而已。“黑盒子”的意思就是你给定什么输入,它就会给出什么样的输出。但是里面经历了什么你并不知道。Reward往往还是一条规则,即看到这样的Observation和Action,就会得到什么样的分数。所以它往往就是一条规则。
3、有的时候还会更糟——即环境和Reward也是具有随机性的。比如在下围棋的时候,你下一个子,你的对手接下来将会下在哪里,它的具有随机性的。一般对于游戏而言,Reward可能是固定的。但是生活中的场景中,比如在自动驾驶中,你可能都无法判断哪种方式是好,哪种方式是不好,它的Reward都有可能是随机的。
实际上,我们还会发现,它和GAN也是有异曲同工之妙的。
在训练GAN的时候,我们会把Generator和Discriminator接一起训练。在调整Generator参数的时候,我们希望Discriminator越大越好。那么,在RL里,这里的Actor实际上就相当于Generator,那Environment和Reward就相当于是Discriminator。我们要去调整Generator的参数,来使得Discriminator越大越好,那在RL里面,我们要调整Actor的参数,让Reward越大越好。当然,和GAN也有不一样的地方,就是GAN的Disciminator也是一个Neural Network,你可以用Gradient Descent来去调整你的参数从而使得你可以得到最大的输出。但是在RL里面,这里的Reward它不是一个Network,它是一个黑盒子。所以,你没有办法用一般Gradient Descent的方法来去调整你的参数来得到你的最大输出。







