引言
在机器学习中,构建一个能够很好泛化的模型至关重要。我们希望模型不仅能在训练数据上表现优秀,还能在未见过的测试数据上取得相似的结果。
然而,这个过程中我们常常会遇到两个常见的问题:欠拟合(Underfitting)和过拟合(Overfitting)。
欠拟合就像是学生只看了课本的封面就去参加考试,没掌握足够的知识,导致考试成绩糟糕。
过拟合就像是学生死记硬背了课本上的所有例题,却没有真正理解问题的本质,导致他只能应对熟悉的题目,对于新题目无从下手。
1. 欠拟合与过拟合的定义
1.1 欠拟合
欠拟合是当模型太简单,无法捕捉数据中的复杂模式时发生的情况。模型在训练集上表现不佳,同时在测试集上也无法提供良好的预测。这意味着模型没有“学”到足够的知识来解释数据。
欠拟合的常见表现:
在训练集和测试集上的误差都很高。
模型无法准确描述数据的趋势或模式。
欠拟合的原因:
1.2 过拟合
过拟合发生在模型过于复杂,甚至学到了训练数据中的噪声和细节,导致在训练集上表现极好,但在测试集上效果不好。这种模型在新数据上的泛化能力较差。
过拟合的常见表现:
过拟合的原因:
1.3 模型的泛化能力
泛化能力是指模型不仅能在训练数据上表现良好,还能在测试数据(未见过的数据)上表现优异。理想的模型应该能够在训练集上达到适度的拟合,同时能对测试集保持良好的预测效果。
为了更直观地理解欠拟合和过拟合,我们假设有一个二元数据集,模型需要通过一条曲线来拟合数据,让我们看下图中三种不同的情况:
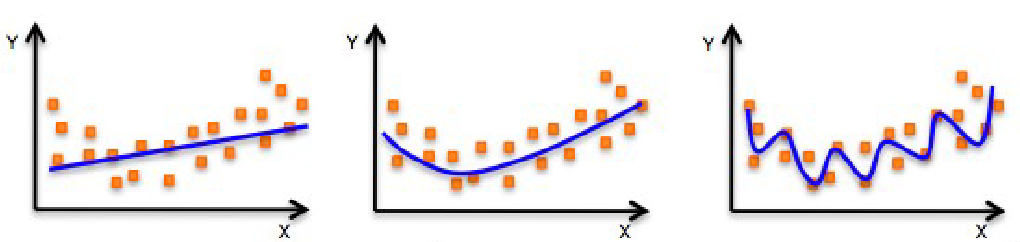
第一张图表示欠拟合:模型是线性的,数据呈现复杂的非线性模式,线性模型无法很好地拟合这些数据。
第三张图表示过拟合:模型使用了非常高阶的多项式,拟合了每一个数据点,包括数据中的噪声。
第二张图表示正确拟合:模型适当复杂,能够准确捕捉数据的主要趋势和模式,能够泛化。
2. 欠拟合与过拟合的数学表达
2.1 欠拟合
欠拟合通常发生在模型偏差(Bias)较高的情况下。偏差是指模型无法准确捕捉数据中的模式。此时,模型的损失函数L很大,计算公式为:
其中:
由于模型简单,预测值与真实值相差较大,造成了高偏差。
2.2 过拟合
过拟合与模型的方差(Variance)有关。方差较高意味着模型对训练数据中的每一个细节和噪声做出了过度反应,导致它在训练集上表现非常好,但在测试集上表现不佳。损失函数可能在训练集上很小,但在测试集上很大。
在数学上,方差高的模型在训练数据上的拟合效果会非常好,但在未见过的数据上预测不准确,失去了泛化能力。
3. 欠拟合与过拟合的Python示例
接下来,我们通过Python的代码示例来展示欠拟合、过拟合以及正确拟合的模型表现。
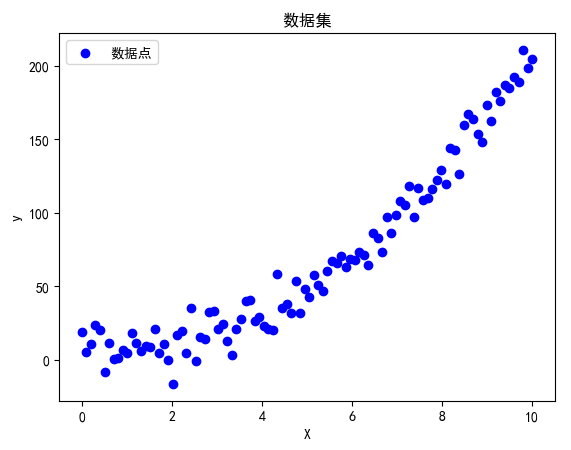
3.1 数据生成
我们将生成一个简单的二元数据集,数据大致符合二次函数的趋势,并添加一些随机噪声。
import numpy as npimport matplotlib.pyplot as plt
np.random.seed(0)X = np.linspace(0, 10, 100)y = 2 * X**2 + 1 + np.random.randn(100) * 10
plt.scatter(X, y, color='blue', label='数据点')plt.title('数据集')plt.xlabel('X')plt.ylabel('y')plt.legend()plt.show()
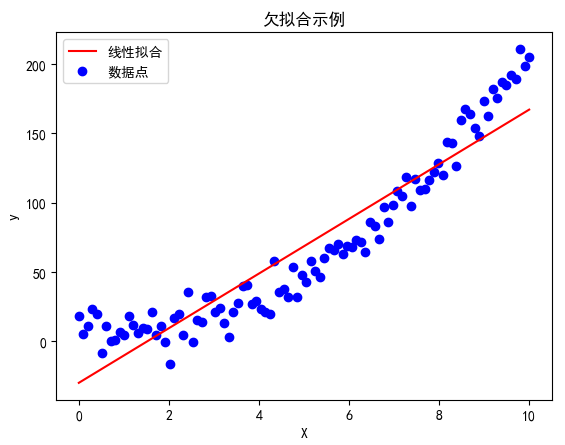
3.2 欠拟合示例:使用线性模型拟合复杂数据
我们首先使用线性模型来拟合一个非线性的数据集,看看欠拟合的情况。
from sklearn.linear_model import LinearRegression
model = LinearRegression()model.fit(X.reshape(-1, 1), y)
y_pred = model.predict(X.reshape(-1, 1))
plt.scatter(X, y, color='blue', label='数据点')plt.plot(X, y_pred, color='red', label='线性拟合')plt.title('欠拟合示例')plt.xlabel('X')plt.ylabel('y')plt.legend()plt.show()
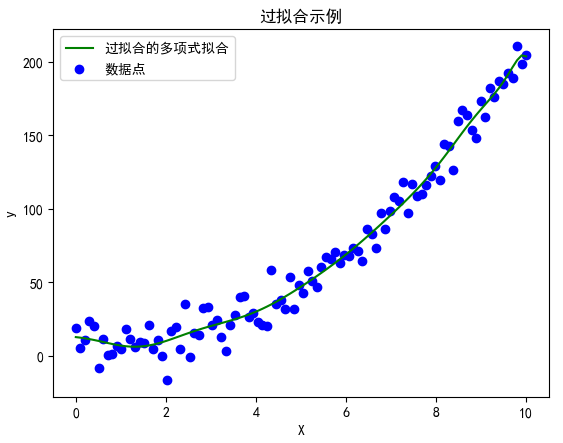
3.3 过拟合示例:使用高阶多项式模型拟合数据
接下来,我们使用一个非常复杂的多项式模型来拟合数据,展示过拟合的情况。
from sklearn.preprocessing import PolynomialFeaturesfrom sklearn.pipeline import make_pipeline
poly_model = make_pipeline(PolynomialFeatures(degree=15), LinearRegression())poly_model.fit(X.reshape(-1, 1), y)
y_pred_poly = poly_model.predict(X.reshape(-1, 1))
plt.scatter(X, y, color='blue', label='数据点')plt.plot(X, y_pred_poly, color='green', label='过拟合的多项式拟合')plt.title('过拟合示例')plt.xlabel('X')plt.ylabel('y')plt.legend()plt.show()
3.4 正确拟合示例:使用适当复杂度的多项式模型
我们展示如何使用合适的多项式模型来进行合理的拟合,避免欠拟合和过拟合。
poly_model_correct = make_pipeline(PolynomialFeatures(degree=2), LinearRegression())poly_model_correct.fit(X.reshape(-1, 1), y)
y_pred_correct = poly_model_correct.predict(X.reshape(-1, 1))
plt.scatter(X, y, color='blue', label='数据点')plt.plot(X, y_pred_correct, color='orange', label='正确拟合的多项式拟合')plt.title('正确拟合示例')plt.xlabel('X')plt.ylabel('y')plt.legend()plt.show()
4. 如何避免欠拟合与过拟合
在实际操作中,我们可以通过以下几种方式来减少欠拟合和过拟合的风险。
4.1 增加数据量
增加数据量是减少过拟合最直接的方法。当数据量充足时,模型能够更好地学习数据的整体模式,而不是数据中的噪声。特别是对于复杂模型来说,更多的数据可以帮助模型更准确地识别规律,避免过度拟合细节。
4.2 选择合适的模型复杂度
不同的任务需要不同复杂度的模型。如果你发现模型欠拟合,可以尝试增加模型的复杂度;如果发现模型过拟合,则可以选择降低模型的复杂度。
4.3 使用交叉验证
交叉验证是一种在训练模型时确保模型具有泛化能力的方法。常见的k折交叉验证将数据集分成 k 份,其中 (k-1) 份用于训练,剩下的 1 份用于验证。通过多次迭代训练和验证,可以找到性能最好的模型,避免过拟合和欠拟合。
4.4 特征工程
特征工程是指对数据中的特征进行加工,使其能够更好地反映数据的真实模式。通过合理选择和构造特征,模型可以更好地拟合数据,避免欠拟合。比如:
总结
欠拟合和过拟合是机器学习模型训练中常见的问题。为了构建一个能够良好泛化的模型,我们需要在模型复杂度、数据量、训练时间等多个方面找到平衡。
希望通过本文的讲解和代码示例,你能够更清晰地理解这两个概念,并能够在实际机器学习项目中有效地避免欠拟合和过拟合。
如果你有任何问题或者想深入探讨某些概念,欢迎在评论区留言!
请备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“加群。
(也可以加入机器学习交流qq群772479961)











