论文链接:https://ieeexplore.ieee.org/document/10412086
Y. Jin et al., "RobotGPT: Robot Manipulation Learning From ChatGPT," in IEEE Robotics and Automation Letters, vol. 9, no. 3, pp. 2543-2550, March 2024, doi: 10.1109/LRA.2024.3357432. ( corresponding author: Bin Fang)
1 引言
大型语言模型(LLMs)在文本生成、翻译和代码合成方面展示了令人印象深刻的能力。最近的工作集中在将LLMs,特别是ChatGPT,整合到机器人技术中,用于任务如零次系统规划。尽管取得了进展,LLMs在机器人技术中的潜力的完整范围仍然未被探索。人机交互(HRI)的不断发展从LLM的进步中受益,特别是在自然语言交互方面。ChatGPT以其代码生成和对话灵活性脱颖而出,允许用户直观地与机器人互动。先前的工作展示了ChatGPT在任务如无人机导航和物体操纵方面的有效性。
近期三星电子中国研究院与中国工程院外籍院士张建伟教授、孙富春教授和方斌教授合作,提出RobotGPT,探讨了ChatGPT在机器人操控应用中的应用,旨在推进相关实际实施。本文的框架将环境线索转换为自然语言,使ChatGPT能够为智能体(Agent)训练生成动作代码。该系统赋予机器人使用自然语言进行理性互动的能力,便于执行如拾取和放置等任务。团队探索了有效的提示(Prompt),提供了关于ChatGPT任务边界和系统稳定性的见解。虽然承认存在一定限制和安全风险,团队的贡献包括创新框架,并探索了ChatGPT在机器人任务上的能力边界。
2 方法
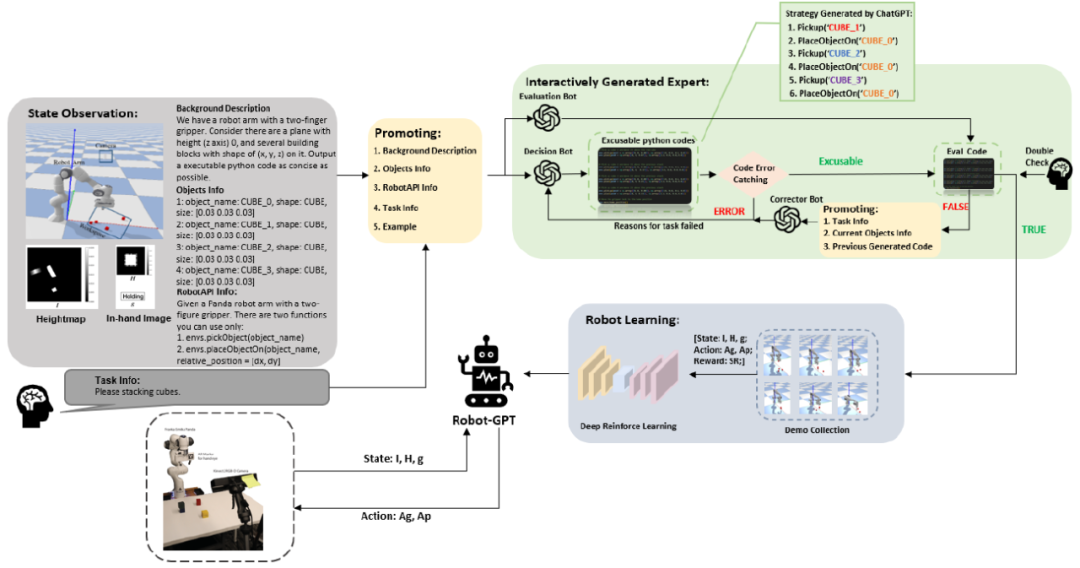
图1 整体架构
图1. 描述了本文的系统架构。在该系统中,ChatGPT扮演三个角色,分别是决策机器人、评估机器人和纠正机器人。操作员指示机器人完成任务,然后根据环境信息和人类指令生成自然语言提示。决策机器人将基于提供的提示生成相应的可执行代码。接下来,生成的代码将逐行执行。如果运行时出现错误,将为决策机器人提供错误原因和发生错误的代码行,以便修改,直到代码能够成功运行。然后,由评估机器人生成的Eval Code模型将测试可执行代码。如果可执行代码不能通过Eval Code,纠正机器人将分析导致结果失败的潜在原因,并将这些失败原因发送回决策机器人进行纠正。之后,满足评估条件的代码将用于生成演示数据。经过训练,训练有素的智能体可以完美地部署真实机器人。
2.1 提示描述
本文提出了一个包含五个部分的提示方法,包括背景描述、对象信息、环境信息、任务信息和示例。在背景描述部分,描述了环境的基本信息,如环境的目的、布局和相关实体。在对象信息部分中,列出了所有对象的名称、形状、姿态以及其他有用的信息,如它们的属性和与其他对象的关系。在环境信息部分中,描述了机器人和ChatGPT可以用来执行任务的API函数。在任务信息部分,则给出了ChatGPT的具体任务,通常是为给定的工作生成Python代码。最后,在示例部分,提供了一些代码示例,以促进对环境和API使用的更好理解。根据OpenAI的建议,文中将背景信息和RobotAPI信息设置为ChatGPT API中的系统消息,以获得满意的响应。
2.2 自纠正过程
在生成复杂任务的响应时,ChatGPT可能偶尔会产生一些小错误或语法错误,需要进行更正。本文介绍了一种用于纠正ChatGPT响应的交互式方法。要使用这种方法,首先在模拟器中执行生成的代码并评估结果。生成的代码将逐行执行,当运行时错误发生时,运行时错误,包括错误消息及其位置,将被代码错误捕捉模块捕获。然后,这些数据被发送回ChatGPT决策机器人进行进一步分析。在结果失败的情况下,纠正机器人可以基于提示分析失败的潜在原因,并生成一个解释任务失败原因的回复。最后,原始的ChatGPT决策机器人将基于纠正机器人的失败分析重新生成代码。利用这种反馈,ChatGPT修正其响应并产生准确的代码。这个交互过程可能迭代多达三次。这里的目标是提高ChatGPT响应的准确性和可靠性,使它们在各个领域越来越相关。
2.3 代码评价
如图1所示,团队使用一个名为评估机器人的ChatGPT来生成评估代码。评估机器人的提示与决策机器人的提示有一些不同。评估机器人生成的函数is_task_success()将作为判断整个任务成功与否的标准。人类的角色是复核生成的评估代码是否正确。如果生成了不正确的评估代码,人类将介入进行更正。这种设计可以最小化人类的负担。
2.4 机器人学习
依靠ChatGPT执行一般的机器人任务是不可靠的,因为ChatGPT的输出是随机的,这扩大了机器人工作的风险。尽管将temperature设置为零可以产生一致的结果,但代价是减少了多样性和创造力,这也可能导致任务的连续失败。为了解决这个问题,团队期望机器人学习机器人策略,以吸收ChatGPT解决一般任务的知识。对于机器人学习,团队利用最先进的开源机器人操纵基准和学习框架BulletArm,从ChatGPT生成的演示中训练代理。
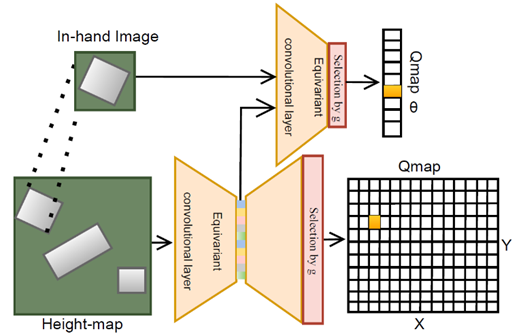
图2 机器人学习网络架构
在本文中,采用了SDQfD 算法来进行机器人学习任务,使用等变ASR网络,如图2所示。损失函数是n-step TD loss和strict large margin loss之和。
3 实验结果
3.1 实验设置
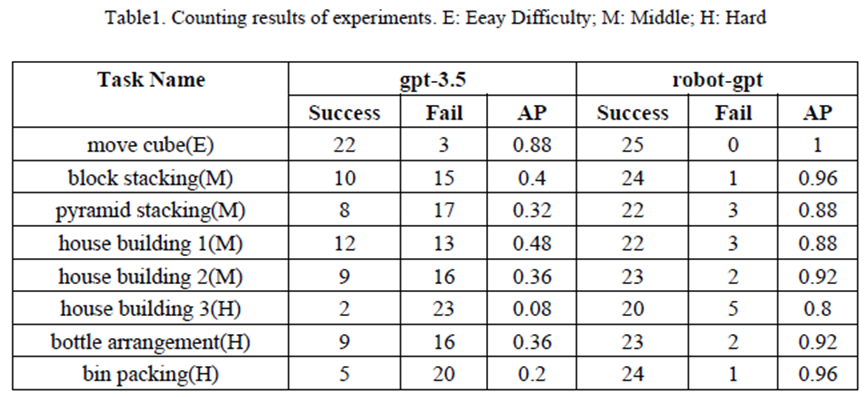
表1展示了八个实验的定量结果。事实是,尽管每次输入相同的提示,由于决策机器人的temperature设置为1.0,生成的代码及其结果输出总是存在显著差异。此外,ChatGPT生成的代码包含语法或逻辑错误。尽管文中的自我修正模块可以修正一些语法错误,但在大多数情况下,如果ChatGPT最初未能生成成功的代码,这个实验成功的难度就会大大增加。
对于ChatGPT来说,很明显,随着任务难度的增加,成功率显著下降。简单、中等和困难任务的成功率分别为0.88、0.39和0.21。相比之下,本文的RobotGPT模型在所有级别的任务中都显示出稳健性,保持良好的表现,在模拟中平均可以达到0.915的成功率。在真实世界的实验中,RobotGPT可以达到0.86的成功率,这是在完全使用模拟数据进行训练的情况下达到的。
3.2 AB测试
为了分析本文的LLM驱动的机器人在解决非LLM方法难以解决的问题上的能力,团队引入了两个开放式实验。第一个实验涉及一个整理房间的挑战,需要组织40个自定义的家庭物品,而第二个实验是一个拼写单词游戏,目标是使用给定的一组字母A-L拼写出最长的单词。此外,团队邀请了人类参与者完成相同的任务。
与手工编码相比,RobotGPT在代码质量和时间消耗方面都展示了优势,分别是0.762和221.8秒,相比之下,人类的数据是0.70和554.9秒。只有五名参与者在70分钟内完成了所有任务,因此即便是对于具有强大编程背景的工程师来说,通过手工编码生成机器人演示数据也是耗时的。
4 结论
在本文中,团队首先开发了一个有效的提示结构,以增强ChatGPT对机器人环境和它需要实施的任务的理解。接下来,本文介绍了一个名为RobotGPT的框架,该框架利用ChatGPT的问题解决能力来实现更稳定的任务执行。在实验中,团队构建了一个度量任务难度的指标,并观察到随着任务难度的增加,ChatGPT执行任务的成功率降低。
相比之下,RobotGPT能够以91.5%的成功率执行这些任务,展示了更稳定的性能。更重要的是,这个智能体也已经被部署在真实世界环境中运行。因此,利用ChatGPT作为专家来训练RobotGPT,比直接使用ChatGPT作为任务规划器是一种更稳定的方法。此外,AB测试显示,文中的LLM驱动的机器人在两个开放式任务上显著优于手工编码,这得益于LLM庞大的先验知识库。总的来说,机器人学和LLMs的结合仍处于起步阶段。本文的工作只是初步探索,团队相信,未来在这一领域的研究很大一部分是探索如何恰当地利用ChatGPT在机器人学领域的能力。
本文由CAAI认知系统与信息处理专委会供稿