CNN、RNN等深度学习模型使用的门槛虽然低,但模型参数多,网络结构复杂。输出如何关联模型的参数,在数学上没有很直观的解释,导致模型网络结构的设计以及训练过程中超参数的调试,都非常依赖于经验。结果不好,是数据的问题还是模型的问题,往往分析起来很困难。如果是数据问题,那么到底是什么问题?如果只凭经验,没有一个很科学的分析工具,则会有盲人摸象的感觉。因此,现在有很多的研究者在致力于深度学习模型的可解释性。
在本篇文章中,我们讲解深度学习可解释性领域中的一个重要方向,模型可视化分析。
作者&编辑 | 言有三
深度学习模型在很多领域中都得到了广泛应用,但是其可解释性相关的研究并未完全完善。对于一些敏感领域,如金融行业,我们不仅需要可靠的模型,还需要可以解释的模型,如它为什么有效,什么时候可能会失效,这样才能更加安全地使用模型,在有必要的时候给用户一个合理的解释。
模型可解释性的本质是用通俗易懂的语言描述模型的能力和逻辑,传统的许多机器学习方法具有非常好的可解释性,比如决策树。通过查看决策树每一个分支节点的决策过程,可以了解模型产生结果的细节。
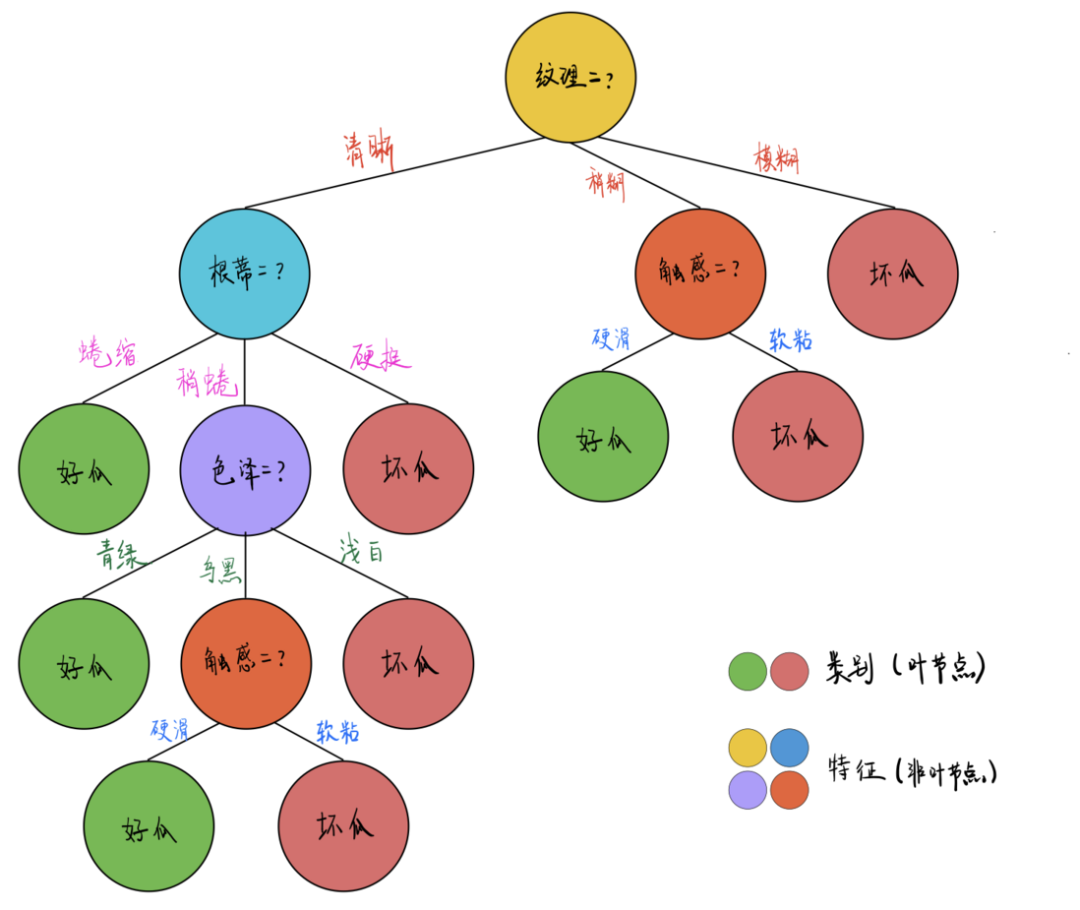
图1 决策树模型
在模型可解释性的研究领域中,可视化是非常直观的方向,可以直观了解数据的分布、模型的结构、特征的分布等,下面我们重点给大家介绍模型结构可视化以及模型可视化分析相关的内容。
神经网络模型具有非常复杂的参数量,在进行前向传播时也有很高的特征维度,因此我们可以可视化的对象包括参数与特征,对不同的目标进行可视化可以从不同角度获得分析结果。
模型结构可视化:神经网络模型通过各层的连接,构成了一个复杂的有向图,通过对模型的结构进行可视化,我们可以获得模型的完整拓扑结构,对层与层之间的关系有更多直观的理解,为后续模型的改进与瓶颈分析提供参考,这一点对于包含较多分支的模型尤其关键。
模型特征可视化:当前的主流神经网络都是前向模型,输入经过多层进行传播直到最终输出结果,每一层的特征直接反映了计算过程,对其进行可视化,可以观察数据在各层的分布情况,辅助分析是否提取到了有效的信息,对结果做出最直观的解释。
模型参数可视化:以卷积神经网络为例,绝大部分参数都集中在卷积核,而卷积核组类似于传统图像处理中的滤波器,不同的卷积核代表不同的滤波模式,单一的卷积核以及多个卷积核的组合,实现的就是特征提取的功能,它可以反映模型学习到了什么样的特征,是对模型最为本质的解释。
输入模式可视化:尽管我们将整个输入无差别的输入模型,但是不同的像素值必然有不同的响应,模型应该学会处理前景目标等重要内容,而丢弃背景等无关内容,通过对输入模式进行可视化,我们可以评估模型是否真正学习到了高层的语义信息,掌握了与人类理解目标相似的“知识”。
本文剩余部分将逐步介绍以上相关方向的核心技术。
所谓模型结构的可视化,就是为了方便更直观的看到模型的结构,从而方便进行调试,下面我们介绍两个比较通用的具有代表性的可视化工具,Graphiz和Netron。
2.1 Graphiz
Graphiz是一个由AT&T实验室启动的开源工具包,用于绘制DOT语言脚本描述的图形,使用它可以非常方便地对任何图形进行可视化。
Graphiz的使用步骤包括创建图,添加节点与边,渲染图,下面是一个简单的案例。
import graphviz
# 创建图
dot = graphviz.Digraph(comment='example')
# 添加节点与边
dot.node('A', 'leader')
dot.node('B', 'chargeman')
dot.node('C', 'member')
dot.node('D', 'member')
dot.edges(['AB', 'AC', 'AD', 'BC', 'BD'])
# 渲染图
dot.render('test-output/team.gv', view=True)
其可视化结果如下图所示。
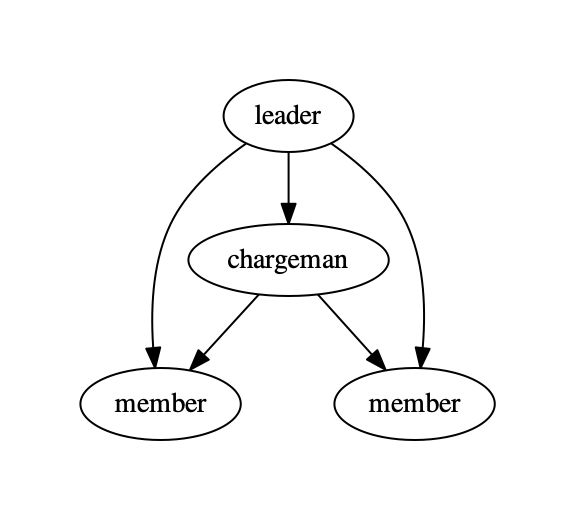
图2 Graphviz可视化图
当我们要对一个深度模型结构进行可视化时,可以调用torchviz库中的make_dot函数,可视化的结果如下图所示:
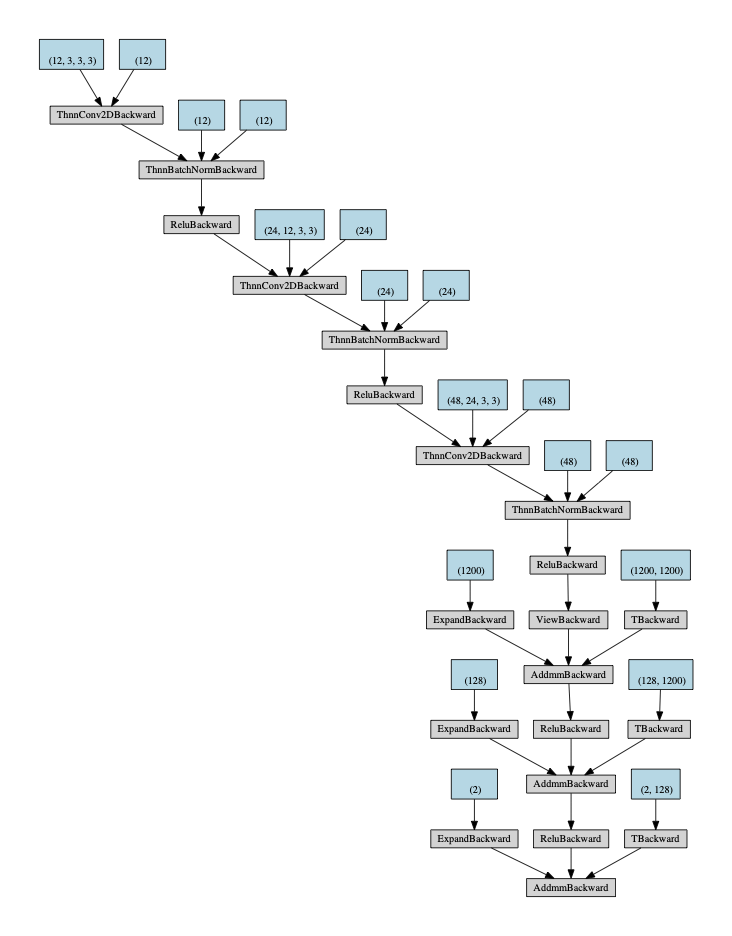
图3 Graphvis可视化网络图
从图3来看,尽管Graphvis可以看到模型的拓扑结构,但仍然不够直观,而且难以获取每一个网络模块的详细信息,功能过于单一,因此我们需要更强大的工具。
2.2 Netron
由于深度学习开源框架众多,如果每一个都需要学习使用一个工具进行可视化,不仅学习成本较高,可迁移性也不好,因此有研究者开发出了可以可视化各大深度学习开源框架模型结构和权重的项目,以Netron为代表,项目地址为https://github.com/lutzroeder/netron。

目前Netron支持大部分主流深度学习框架的模型格式,包括:
ONNX (.onnx, .pb, .pbtxt),Keras (.h5, .keras),Core ML (.mlmodel),Caffe (.caffemodel, .prototxt),Caffe2 (predict_net.pb, predict_net.pbtxt),MXNet (.model, -symbol.json),TorchScript (.pt, .pth),NCNN (.param),nump Lite (.tflite),PyTorch (.pt, .pth),Torch (.t7),CNTK (.model, .cntk),Deeplearning4j(.zip),PaddlePaddle (.zip, __model__),Darknet (.cfg),scikit-learn (.pkl),TensorFlow.js (model.json, .pb),TensorFlow (.pb, .meta, .pbtxt).
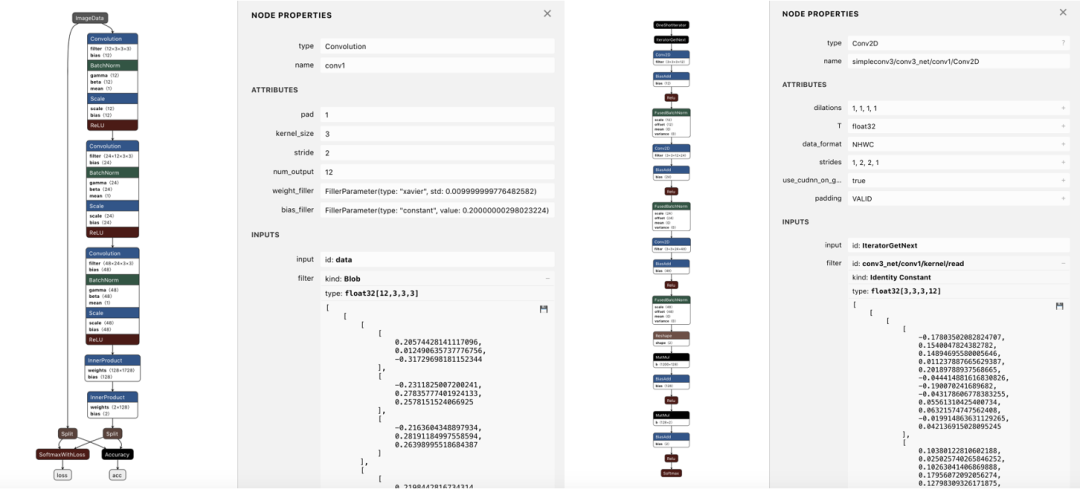
图4 Netron可视化案例
通过可视化模型结构,我们对需要训练的网络就有了整体的把握,修改代码后可以查看模型结构的变化,从而检查是否符合设计的初衷,这在训练大模型与小模型时都是非常实用的技术。假如输入的是训练好的权重文件,还可以直接查看每一个网络层的权重,通过一键导出参数为npy文件,可以简单统计权重的分布。
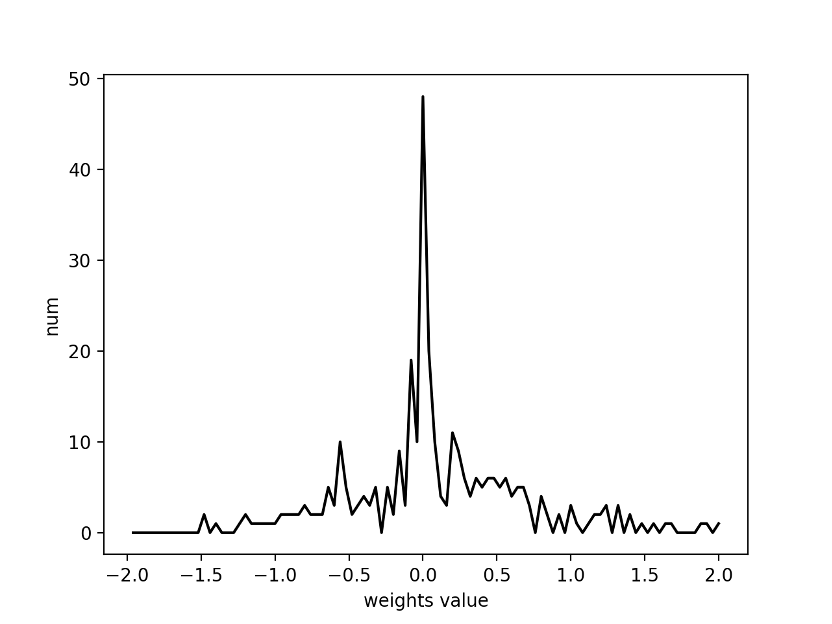
图5 基于Netron导出某一层的权重分布
模型结构可视化可以分析模型的结构设计是否合理,但是无法直观展现模型的性能,接下来我们介绍一些模型可视化分析的技术,可以增进我们对模型的理解。
神经网络与人脑的分层学习机制是类似的,从网络的底层到高层所学习到的知识抽象层次不断增加。在网络底层学习到的特征是边缘,随着网络加深,逐渐学习到目标形状,最后是语义级别的目标。
越是在网络浅层,滤波器有越小的感受野,看到的就是越局部的信息,而到了网络的深层,感受野越大,看到的就是越全局的信息,因此学习到的知识越抽象。
以卷积神经网络为例,假设某一层输入通道数是N,输出通道数是M,我们称之为M个特征。对于正常的多通道卷积,需要的卷积核数量是N×M,每N个为一组,对应M个特征中的一个。
当我们需要可视化某一组卷积核学习到的知识,可以单独对每个卷积核进行可视化,

图6 单个卷积核可视化
但是在多通道卷积中,卷积核实际上是有分组关系的,每一组卷积核会与输入的所有通道进行卷积。由于大部分网络的输入都是RGB彩色图,所以数据层的通道数为3,即第一个卷积的输入通道数为3。
假设第一个卷积的输出通道数为C,卷积核大小为K×K,卷积参数量就是C×3×K×K。每3个卷积核实际上为1组,包括3个K×K大小的卷积核,它分别与输入RGB图的3个通道进行卷积特征提取,因此一次对一组卷积核进行可视化更有意义。
不过除了第1个卷积层外,输入特征图的通道数一般远大于3,因此对于卷积参数的可视化,我们一般是可视化第一个卷积层。我们可以将每组卷积核直接转换为一个彩色图,从而很直观的可视化第一层的卷积参数,这对于任意以3通道彩色图为输入图的网络结构来说都是通用的。
通常情况下,我们希望第一个卷积层学习到的权重模式足够丰富,这样就表明模型有强大的底层特征提取能力。如下图所示,从左到右分别展示了AlexNet,VGGNet,MobileNet的第一层卷积可视化的结果,它们的通道数分别是96,64,32。
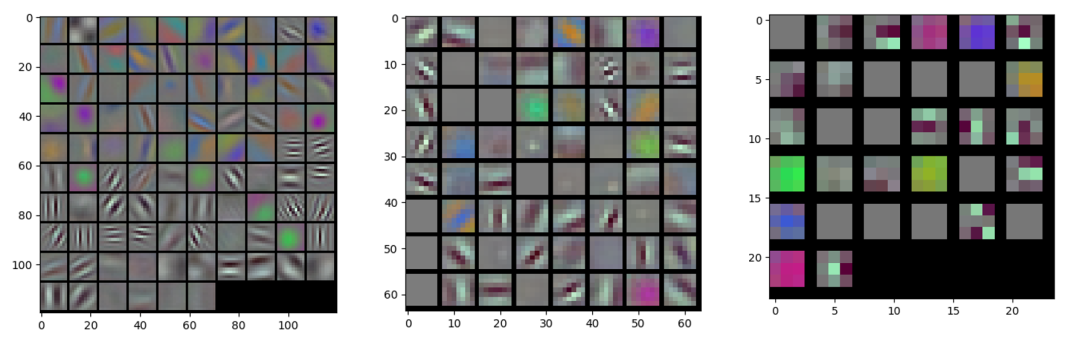
图7 AlexNet,VGGNet,MobileNet第一层卷积参数
以AlexNet模型为例,对第一层卷积96个通道进行彩色图可视化之后发现,其中有一些卷积核为灰度图,说明3个通道的对应参数的数值相近,学习到的是与颜色无关的特征。有一些卷积核为彩色图,说明3个通道的特征差异大,学习到的是与颜色有关的特征。有一些卷积核是不同方向的滤波器,与Gabor滤波器非常像,说明学习到的是边缘和梯度相关的特征。
对每一层的激活值进行可视化也是一种非常直观的方法,它可以直接观测各层的特征值是否学习到了足够具有表达能力的特征。如下图所示为一张RGB图像,以及AlexNet,VGGNet和MobileNet第1个卷积层后卷积输出特征图。
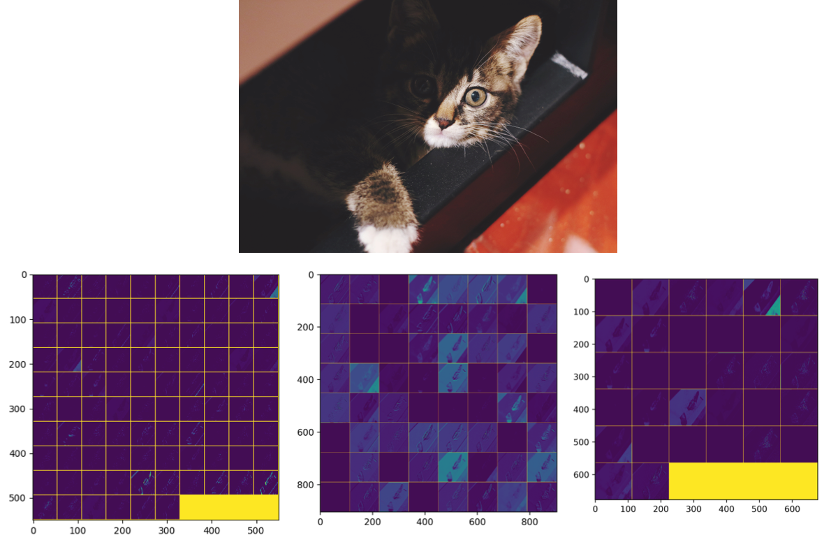
图8 AlexNet,VGGNet,MobileNet第一层卷积的输出特征(从左至右)
从图8中可以看出,经过第一层后,模型提取了各类边缘与颜色特征,而且特征图有一定的冗余性。可以继续对高层的特征进行可视化,查看模型是否学习到了足够抽象的特征。
为了方便查看模型的参数以及特征,有许多研究者都开发过相关的工具,这里我们给大家介绍一个功能比较完善的工具,加拿大蒙特利尔一家公司开发了一个3D的可视化工具Zetane Engine。通过上传一个模型和数据,该工具可以可视化网络中任何一层的特征图,特征图的展示方式比较丰富,支持二维图、三维图和数值直方图。
图9展示了对输入数据的可视化结果,UserInput表示输入,可看到左侧图像原始大小为60×60,RGB的三个通道分别用灰度图展示。而模型的输入张量大小为1×3×48×48。右上方展示了对所有灰度值的直方图统计,最大像素灰度值为255,最小像素灰度值为24,平均像素灰度值为155。右下角则通过伪彩色的方式显示了输入的一个通道。
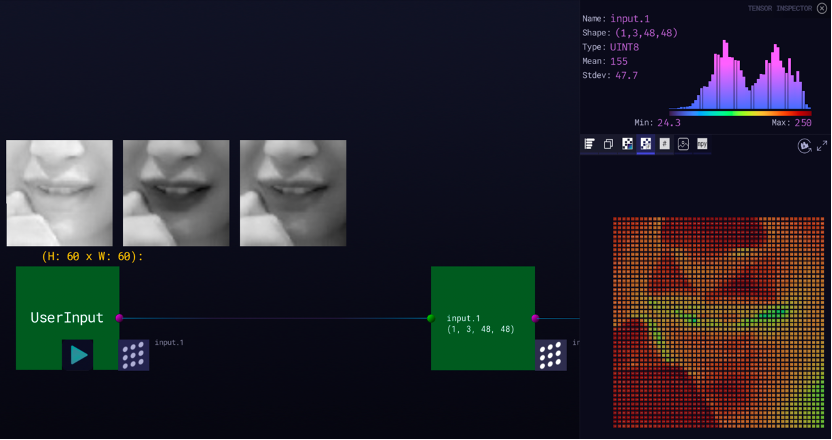
图9 Zetane Engine可视化输入数据
图10展示了对卷积层特征的可视化结果,输出特征图大小为1×12×23×23,左侧展示了平铺的一些特征图,右下角则展示了3D的视角。
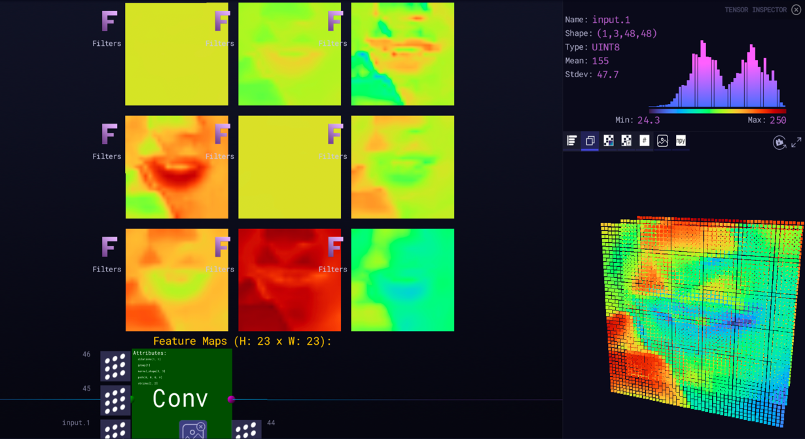
图10 Zetane Engine可视化特征
图11展示了对输出预测结果的可视化结果,输出向量大小为1×2,右下角展示了Top 2分类结果,即2个类别未经过Softmax映射的原始结果,通过值的大小可以获得最大通道的索引值,即分类结果。
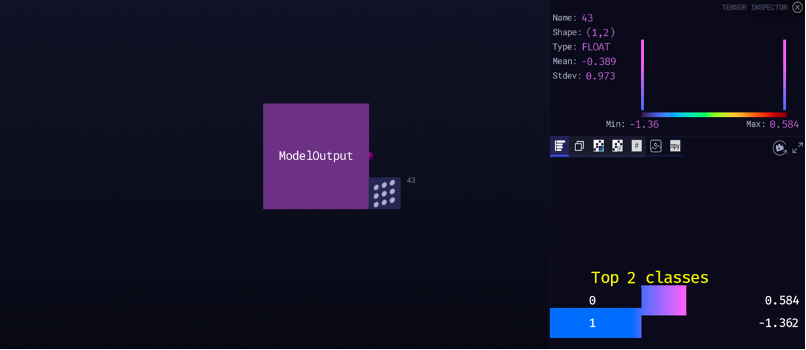 图11 Zetane Engine可视化输出
图11 Zetane Engine可视化输出
对于深层的卷积,由于输入的通道数不再为3,所以无法像第一层那样将卷积核本身直接投射到3维的图像空间进行直观的可视化。大多数时候我们对深层卷积的可视化不再关心卷积核,而是关心特征图,尤其是激活较大的特征图,因为它们对模型的输出有较大影响,目标是可视化网络感兴趣的输入模式,即什么样的图片可以使得特征有最大的激活,这一类方法可以归为激活模式最大化可视化(activation maximization)方法。
具体考虑到最大激活模式时,这里就有很多种选择,是单个神经元、某个通道、某一网络层、Softmax前的激活值还是Softmax之后的概率,不同的选择自然会带来不同的可视化结果。
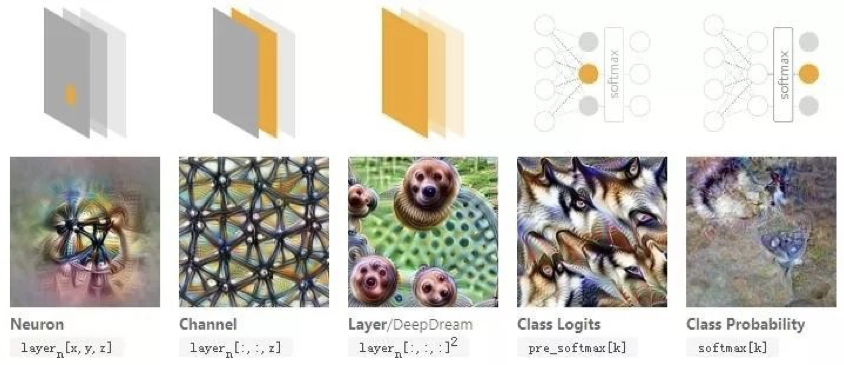
图12 不同最大激活目标的输入可视化结果
图12中以不同的网络结构为目标可以找到不同的最大化输入图像。这里n为层序号,x和y为空间位置,z为通道序号,k为类别序号。
要理解网络中的特征,比如特定位置的某个神经元、或者一整个通道、甚至整个网络层,就可以找让这个特征产生很高的值的样本,大多数的研究方法都是以通道作为目标生成的。
假如要从分类器的阶段出发找到输入样本的话,会遇到两个选择,优化Softmax前的激活值还是优化Softmax后的类别概率。Softmax前的激活值其实可以看作每个类别出现的证据确凿程度,Softmax后的类别概率就是在给定的证据确凿程度之上的似然值。不过不幸的是,增大Softmax后的某一类类别概率的最简单的办法不是增加这一类的概率,而是降低别的类的概率。
激活模式最大化可视化(activation maximization)方法众多,下面我们只介绍其中的梯度反向传播法和反卷积法。
4.1 梯度反向传播法
Dumitru Erhan和Yoshua Bengio等人在2009年提出从DBN网络的输出进行从顶到底的计算来得到输入的样本,以便可视化网络感兴趣的输入模式,后来在2013年,Karen Simonyan等人首次将其应用到深层图像分类网络的可视化中。这是一种基于网络(network-centric)的激活模式最大化可视化方法,它不依赖于真实的图像数据,而是通过最大化某一个神经元的激活模式,采用基于梯度的反向传播方法对输入进行优化求解。基本原理如下:
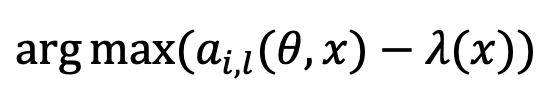
其中l表示网络的第l层,x表示要优化的输入,i表示第i个神经元,θ就是要优化的参数,λ(x)是一个正则项,用于约束x有真实图像的一些分布特性,如局部平滑性。
以最大化分类网络的某一个类别的输出概率为例,一个实际的优化目标如下:
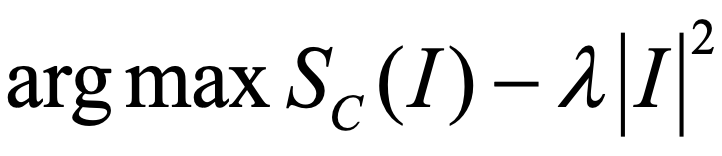
其中,c是类别,Sc就是该类别的激活值,通常是没有归一化过的Softmax层的输出。之所以不进行归一化,是因为如果归一化,有可能优化上面的式变成了最小化其他类别的分数,那样会更加简单,而我们想要的仅仅是最大化本类别的分数,根据作者们的实验,以Softmax前的激活值作为优化目标可以带来更高的图像质量。
优化的目标是通过求解I,使得式最大化,其中I^2是一个二阶正则项。在反向传播的过程中,网络的权重是不会发生变化的。初始化的输入图I通常采用训练集的平均值。上式可以通过当前的反向传播机制进行学习,只是需要学习的是输入图像,而不是模型权重。
另外,如果我们考虑线性近似模型,计算S_c对 I的偏导数可以得到w,它反映的是每一个图像像素对输出结果的敏感程度,因此也可以被当作显著目标图。
下图展示了一些基于梯度计算的可视化结果。

图13 梯度法激活可视化结果
原生的基于梯度计算的可视化结果存着较多的噪声,与真实的图片差异较大。有一些研究者致力于能够获得更加真实的激活模式,通过添加一些约束来使得生成的图片更接近自然图像,常见的操作包括权重衰减、范数约束、全变分约束、图像去模糊、图像块先验和生成对抗网络等。
以GoogleBrain团队的Deep Dream研究为例,它们在梯度计算法的基础上采用图像抖动的方式,对Inception网络进行了逐层的特征可视化,揭示了每一个网络层的特性,图14展示了其中的一个案例。

图14 Deep Dream可视化某一层图像案例
4.2 反卷积法
反卷积方法与梯度计算法不同,它的核心思想是利用上采样从特征空间逐步恢复到图像空间,必须要使用真实的输入数据进行前向和反向传播。
假设我们要可视化某一个特征图的一个神经元,即特征图的一个像素的激活模式,则首先从数据集中计算多个输入图像各自经过前向传播后在这个神经元上产生的激活特征,取出激活最大的一些图像,这些图像是真实的输入图。然后将这些图在这个神经元上产生的激活进行反向传播,直到回到原始图像空间。
反向传播的模型结构和前向传播模型结构是对应的,其中与池化(Pooling)对应的就是反池化(Uppooling),它通过在卷积过程中记录下最大激活位置,在反卷积的时候进行恢复。与卷积对应的就是转置卷积,激活函数则仍然不变,如图15所示为反卷积的示意图。
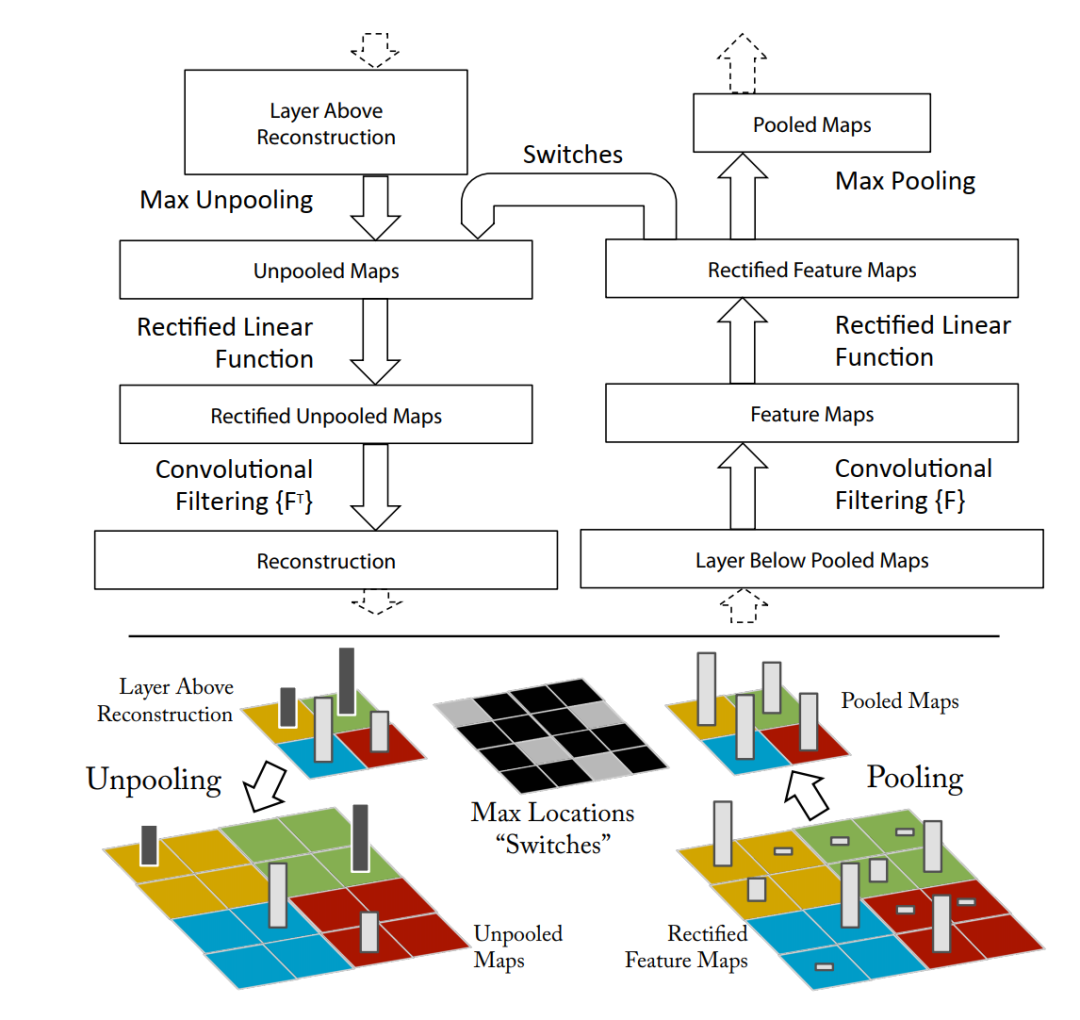
图15 反卷积可视化原理
完整的可视化流程包括如下几个步骤:
• 从样本集中选择N个样本,输入网络进行前向传播,统计各个通道特征图的激活值。
• 当想对某一层进行可视化分析时,对该层的特征通道的激活值进行排序,选择统计激活值最大的特征通道,将其作为该层最显著的特征。
• 保留激活最大的特征通道,将其他通道置为0,进行反向计算,往图像空间进行上采样,每一次反向计算都可以与样本的前向计算过程对应上
• 反向计算结束,得到尺度等于输入图像的图,它是一个重建图,如图16中左图,有点类似于特征图,但并不是实际的样本经过网络前向传播后计算出来的特征图,而是经过反向计算后的重建图。虽然它的语义特征与对应前向计算的RGB图相似(图16中右图),但纹理与颜色细节明显不同,这是因为卷积和池化过程可逆,但激活函数不可逆。

图16 反卷积可视化重建图(左图)与前向计算对应的图(右图)
不论是不依赖真实样本优化的梯度法,还是依赖于真实样本的反卷积法,它们都通过激活特征的最大化可视化,反映出了什么样的模式可以让神经元产生激活,也就反映出了模型所学习到的特征,因此可以作为对高维卷积权重可视化分析的重要工具。
输入图片中包含了很多的像素,但前景和背景对神经网络的重要性显然是不一样的,即使前景的各个像素也是不一样。通过对输入中各个元素的重要性进行量化和分析,能够帮助大家理解是什么样的内容影响了模型的输出,一个很常见的相关研究领域就是目标显著性(Saliency Detection)检测,所得的结果可以称之为敏感图(Sensitivity Map)或者显著图(Saliency Map),本节介绍对输入区域重要性的可视化方法,从输入图像的角度解释CNN在关注图片中的什么目标。
5.1 基本原理
最大激活区域可视化,即对不同的图片,找到能够使特定卷积核获得最大激活的图片样本中的有效区域,一般的流程可以分为几个步骤。
第一步,准备一个比较大的测试数据集,把所有图片送入网络后记录激活响应图,得到每一层的激活特征图。
第二步,假如我们需要观测某一个卷积核的激活区域模式,那么只需要对所有激活特征图根据最大激活值进行排序,然后记录下对应的图像样本。
第三步,将激活特征图上采样到图像空间中,根据激活值进行二值化,根据结果掩膜就可以在图像中分割出语义区域。越是高层的特征图,越可以定位到图像中完整的语义目标,这反映出高层的卷积核已经学习到了目标检测的能力。
后来研究者将该思想进行拓展,提出“网络解剖(Network Dissection)”方法,使其可以自动标定出每个卷积核对应的语义概念,并且通过图像分割掩膜的准确性对语义检测概念,或者检测能力进行量化,其原理如图17。
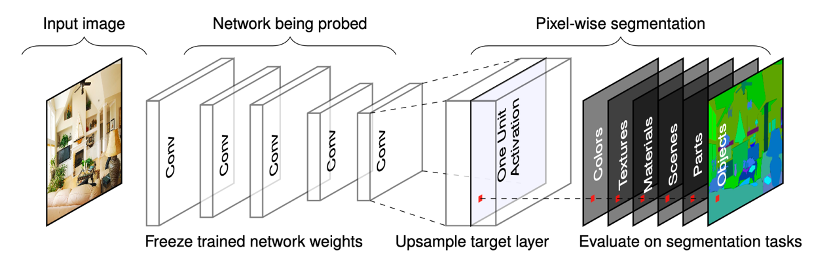
图17 Network Dissection可视化原理
Network Dissection方法的基本原理是将每一个卷积核对应的最大的激活特征图上采样到图像空间中,根据激活值进行二值化得到掩膜,将其与图片的所有真实语义标签进行IoU计算,假如其最大的IoU值超过0.04,即认为该卷积核学习到了有效的语义信息,即IoU重叠度最大的语义类别。
5.2 反向传播输入可视化
前述方法是通过对最大激活值进行统计来直接推断激活神经元的像素区域,而更加直观的方法是直接基于反向传播的思路来进行计算,通过计算各个输入单元的梯度,将其作为输入单元的重要性。在进行可视化的时候,通常使用图像×梯度。这一类方法称之为基于反向传播的输入可视化方法,或者简称为梯度计算法。
梯度计算法包括标准的梯度计算法以及它的一些改进版本,包括平滑梯度法(SmoothGrad),导向反向传播(guided backprop),积分梯度法(integrated gradients)等。
图18展示了梯度法可视化的典型结果:
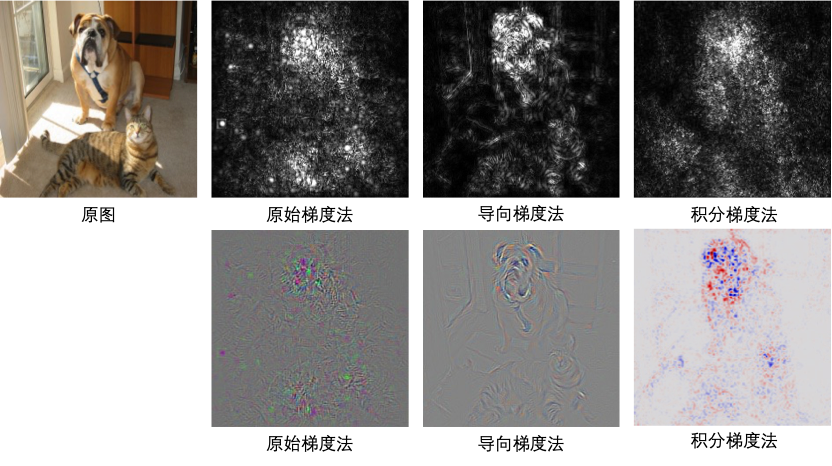
图18 梯度法可视化原理
基于反向传播的输入可视化方法,得到的结果往往是图像边缘像素获得大的响应,因为这些像素的梯度较大,但带来的一个主要问题就是结果图中噪声过多。一个比较典型的改进就是在原图的基础上,添加随机高斯噪声得到多幅图,然后对这些图像的结果图进行平均,这实际上相当于对局部梯度进行了平滑,从而减少了结果图中的噪声,这就是所谓的平滑梯度法。
在导向反向传播算法中,除了ReLU层外,卷积层和池化层都采用正常的反向传播算法,而对于ReLU层,小于0的梯度被置为0,然后再继续进行传播,这与ReLU在正向传播中的计算方法一致。通过去掉无效的梯度,同样减少了结果图中的噪声。
积分梯度法(Integral Gradient,IG)是对原始梯度法的一个典型改进,它的核心思路是考虑当输入像素只有部分信息能够输入网络时各部分输入能够得到的梯度,然后基于这些梯度来计算重要性。积分梯度法可以估计像素的全局重要性而不仅仅是局部重要性。
5.3 类激活可视化方法(CAM)方法
通过对最大激活特征图进行二值化,可以找到图像中的有效激活区域,但是其计算量较大,要想获得比较准确的区域定位结果,必须要有足够多的样本来进行最大激活值统计。
假如我们只关注最终的任务,即从输入图像中找出对最终高层语义任务有较大贡献的区域,比如分类为某一个类别的区域,则可以采用CAM(Class Activation Mapping,类激活映射方法)方法,它可以反应网络到底在学习图像中的什么信息,是否学习到对任务真正有用的信息,其结果为敏感图(Sensitivity map,或者Saliency maps,或Highlight maps)。
图19展示了CAM可视化的原理。
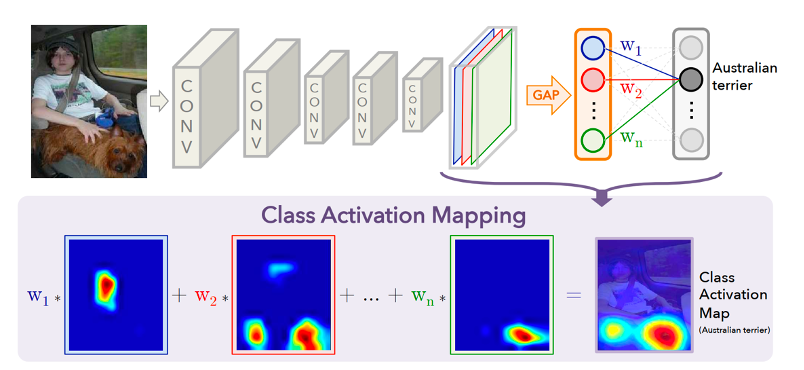
图19 CAM可视化原理
对于一个深层的卷积神经网络,通过多次卷积和池化之后最丰富的空间和语义信息被包含在最后一层卷积层中,这也是人眼可以理解的最深层的信息,之后就是以全连接层和softmax层为代表的分类层。
对于一个图像分类任务,CAM框架首先利用全局平均池化(Global Average Pooling,简称GAP)对最后一个卷积特征层进行池化,替换掉经典模型中的全连接层。
假设特征图为f,通道数为N,分类类别数为C,需要使用N×C大小的矩阵w获得Softmax映射层的输入S,从而获得各个类的输出概率,则某一个类别c对应的Sc的计算如下;
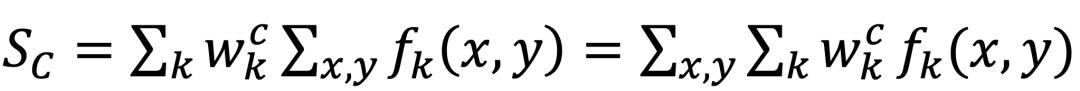
其中,x,y对应图像的高与宽,求和表示池化操作。如果不考虑公式中的池化操作,可以定义对应类别c的类激活映射热图M_C如下:
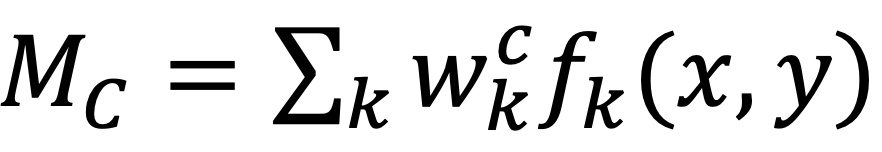
S_C实际上就是M_C对空间位置的求和,在不同的空间位置有不同的值,越重要的区域值更大。将M_C直接上采样到原图中,就能观察在原图中对应的激活区域,查看模型是否定位到了重要语义区域,实现对模型有效性的分析。
原始的CAM无法直接对现有的一些基于全连接的分类模型进行可视化,因为它需要全局平均池化层进行改造,所以后来研究者提出它的变种Grad-CAM[来进行改进。
Grad-CAM的核心思想就是不需要修改已有的模型结构,而且不再局限于图像分类任务。
假设A表示特征图,K表示通道,C表示类别,y表示预测值,y可以是多种任务的预测值,常见的如图像分类的类别和回归任务的数值。
我们定义第k个特征图对第c类预测值的重要性如下:
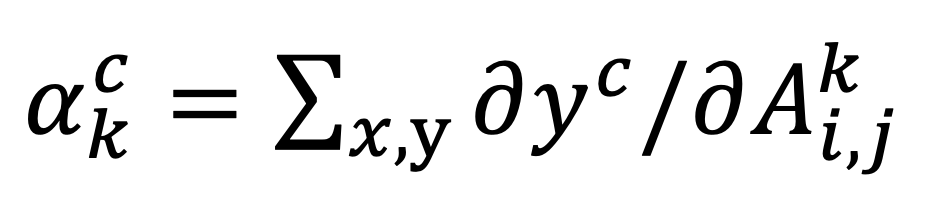
类激活图就可以采用下式进行计算:
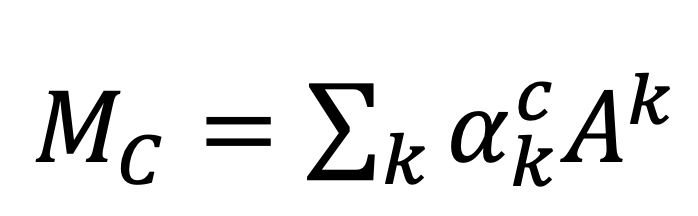
与原始的CAM相比,基于梯度来定义重要性,比基于直接的连接来定义重要性更加具有通用性,因此Grad-CAM应用更加广泛。
使用Grad-CAM对分类结果进行解释的效果如图20所示:

图20 基于CAM的图像分类模型结果解释
除了直接生成热力图对分类结果进行解释之外,Grad-CAM还可以与其他经典的模型解释方法如导向反向传播相结合,得到更细致的解释,如图21所示。
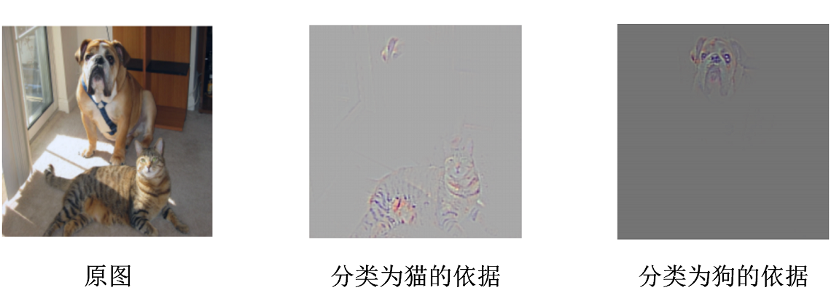
作为一个研究人员相对较少的领域,模型可视化虽然不比图像分类、目标检测和图像分割等领域受到很多研究者的关注,但对其研究是构建更完备的深度学习理论体系不可缺少的重要一环。在金融、医疗和军事等行业中,许多时候我们不仅要求模型有高精度,还必须拥有很好的可解释性,在模型出现问题的时候,必须能够精准定位并且做出对于民众可接受的解释说明,其中,可视化就是非常好的技术。
如果大家想要深入学习深度学习模型可视化理论与相关的实践,可以参考有三今年出版的新书《深度学习之图像识别:核心算法与实战案例(全彩版)》,本书从深度学习的背景和基础理论开始讲起,然后介绍了深度学习中的数据使用,以及计算机视觉的三大核心领域,图像分类、图像分割、目标检测,并介绍了深度学习模型的可视化、模型的优化和部署,大家可以参考阅读。
如果你是一个深度学习与计算机视觉学习新手,想要从Python编程、Pytorch框架使用与深度学习开始,到较为深入系统地掌握计算机视觉的核心领域,培养出独立完整的CV算法研发与工程项目能力。欢迎了解我们2023年CV初阶-基础算法组的学习内容,详情可以阅读。
[1] Erhan D,Bengio Y,Courville A,et al. Visualizing higher-layer features of a deep network[J]. University of Montreal,2009,1341(3):1.
[2] Simonyan K,Vedaldi A,Zisserman A. Deep inside convolutional networks:Visualising image classification models and saliency maps[J]. arXiv preprint arXiv:1312.6034,2013.
[3] Mordvintsev A,Olah C,Tyka M. Inceptionism: Going deeper into neural networks[J/OL].https://research.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html,2015.
[4] Zeiler M D,Fergus R. Visualizing and understanding convolutional networks[C]//Computer Vision–ECCV 2014:13th European Conference,Zurich,Switzerland,September 6-12,2014,Proceedings,Part I 13. Springer International Publishing,2014:818-833.
[5] Bau D,Zhou B,Khosla A,et al. Network dissection:Quantifying interpretability of deep visual representations[C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2017:6541-6549.
[6] Smilkov D,Thorat N,Kim B,et al. Smoothgrad:removing noise by adding noise[J]. arXiv preprint arXiv:1706.03825,2017.
[7] Sundararajan M, Taly A, Yan Q. Axiomatic attribution for deep networks[C]//International conference on machine learning. PMLR, 2017: 3319-3328.
[8] Springenberg J T, Dosovitskiy A, Brox T, et al. Striving for simplicity: The all convolutional net[J]. arXiv preprint arXiv:1412.6806, 2014.
[9] Zhou B,Khosla A,Lapedriza A,et al. Learning deep features for discriminative
localization[C]//Proceedings of the IEEE conference on computer vision and pattern
recognition,2016:2921-2929.
[10] Selvaraju R R,Cogswell M,Das A,et al. Grad-cam:Visual explanations from deep
networks via gradient-based localization[C]//Proceedings of the IEEE international conference on computer vision,2017:618-626.








