 标题&作者团队
标题&作者团队论文链接:https://arxiv.org/abs/2107.03055
盲图像超分旨在对未知退化类型的低分辨率图像进行超分增强,由于其对于实际应用的重要促进作用而受到越来越多的关注。近来,有许多新颖、高效方案(主要是深度学习方案)已被提出。尽管经过学术界、工业界多年的努力,盲图像超分仍然是一个极具挑战性的研究课题。
本文系统综述了盲图像超分的近期进展,对现有方案按照退化建模、数据等进行了分类划分以帮助研究人员归纳判别现有方案。我们对现有研究状态进行了深入分析,同时提出了一些值得深入探索的研究方向。此外,总结了盲图像超分常用数据集以及相关竞赛。最后一点,我们采用合成数据与真实数据对现有方法的优缺点进行了分析比较。
Introduction
退化模式(比如高斯模糊、bicubic下采样等)已知的图像超分最近几年取得了极大的进度,但这些方法对于复杂退化的真实场景却难以得到令人满意的效果。为弥补该差距,近年来学术界与工业界开始关注退化未知的图像超分,即盲图像超分。
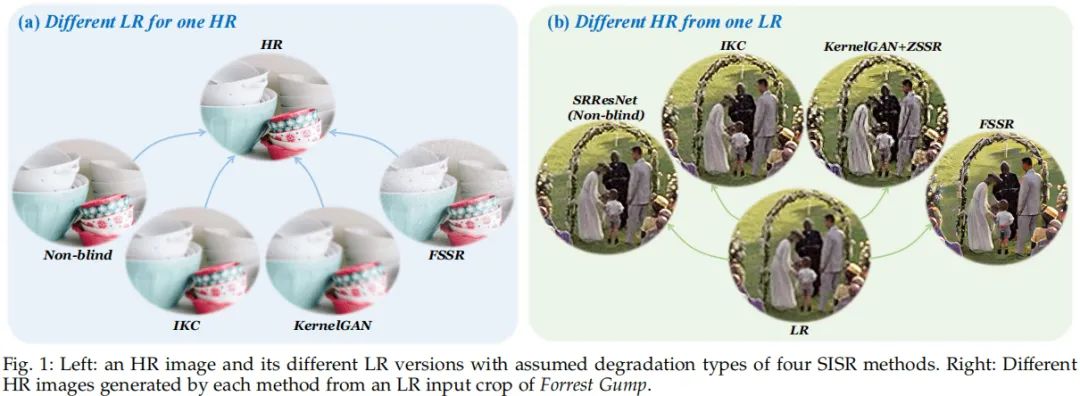
盲图像超分最近几年也取得了显著的进展,但它们仅能处理特定类型的退化。以上图a为例,四种不同的退化假设的LR对应了相同的HR,当给定一个偏离假设数据分布的输入时,现有方法就难以得到满意的结果。以上图b为例,四种不同的超分方法对《阿甘正传》中某一场景的超分效果,很明显:没有一个方法取得令人满意的效果,因为实际图像并不会严格满足各个模型的退化假设。
那么,对于特定的待处理图像,我们该如何选择超分方法呢?或者说,我们采用现有方法能否得到一个高质量的超分结果呢?我们在多大程度上解决了盲图像超分?又或者说,什么在阻碍我们前进,我们又该朝哪个方向努力?
为回答上述问题,我们对近期盲图像超分的进展进行了系统的综述,对不同方法的优缺点进行了对比分析,同时提出了一些值得探索的研究方向。
Problem Formulation
我们首先对SISR问题的定义进行介绍。一般来讲,SISR指的是从给定LR输入重建HR图像,特指HR的高频成分。从HR到LR的潜在退化过程可以描述如下:
因此,SR就等价于建模并解决逆函数。对于non-blind SR来说,退化函数一般假设为双三次下采样(描述如下):
或者,下采样与固定模糊核的高斯模糊:
无论是那种假设,对应的超分模型仅能处理特定类型的退化。对于其他类型的退化,当SR模型与输入的退化不一致时,就会产生较差的重建质量问题。
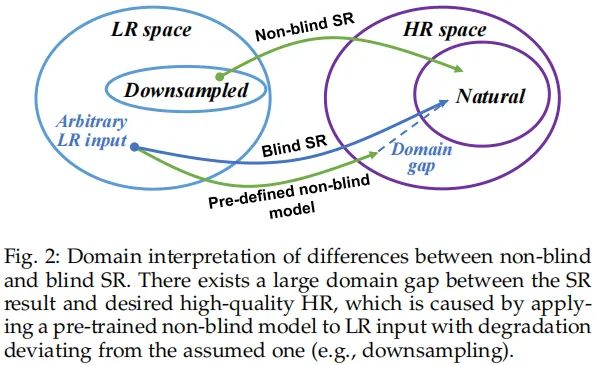
上图从图像域的退化不匹配角度给出了可视化说明:如果对应特定退化的超分模型被用于任意LR输入,这就会导致较大的域差异,进而产生较差的重建结果。
截至目前,关于盲图像超分主要有两种退化建模方案:(1) 显式建模;(2) 隐式建模。显式建模方案:它采用了所谓的经典退化模型,一种更广义的退化方式,描述如下:

上图给出了不同模糊、噪声下的图像示例,这些退化图像明显要比bicubic下采样更复杂。现有方法包含IKC、SRMD。除了模糊与噪声外,JPEG压缩也是一种常见退化,此时退化模型表示如下:
还有一些方法(比如ZSSR、DGDML-SR)则利用图像内部统计信息进行超分,且无需额外数据进行训练。但是,内部统计信息仅仅能反应上图b中的块重复属性。
然而,真实退化通常过于复杂而导致难以通过显式多退化组合方式建模,见上面图c。因此,隐式建模则试图绕开显式建模方式,它通过数据分布模拟退化过程。所有的隐式建模方法均需要额外数据进行训练。一般来讲,这些方法通过GAN学习数据分布,比如CGAN。
尽管已有这么多模型在推动盲图像超分,但仍有很长的路需要探索。现有方法仅仅聚焦于特定的场景,而真实场景的退化类型、数据场景要复杂的多。
Challenges from Real-World Images
随着拍摄设备的普及,我们可以随时随地拍摄大量的图像,这种图像源的可变性同样带来了挑战。一般来讲,主要有以下三个因素导致不同的退化:
- 不同的拍照设备:可参考下图不同拍摄设备的画质对比。

- 图像处理算法:该问题主要几种在数码相机与智能手机。ISP一般包含多个步骤,不同的相机具有不同的算法,进而导致不同的退化。
- 存储带来的退化:为降低资源占用,图像/视频往往要进行压缩,压缩则会导致伪影问题,进而产生了退化。此外,时间是一把杀猪刀,老照片、老电影的退化场景也就出现了。

Taxonomy
按照前面所提到的,主要有两种退化建模方式:
- 显式建模:基本思想采用覆盖大范围退化的额外数据训练一个超分模型,往往需要将模糊核与噪声信息进行参数化。这其中代表性的方法包含SRMD、IKN、MKSR。另一种利用块重复的方法探索内部统计信息,代表性方法有KernelGAN与ZSSR。
- 隐式建模:它不依赖于任何显式参数,它利用额外的数据通过数据分布隐式的学习潜在超分模型。代表性方法有CinCGAN、FSSR。
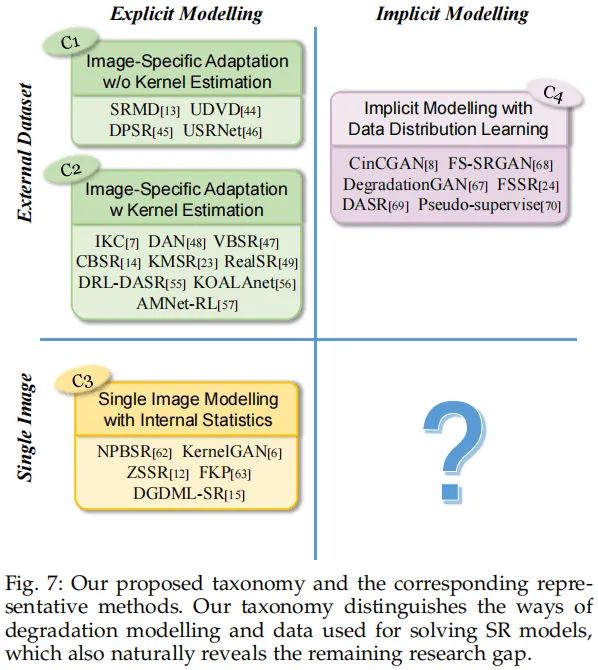
基于此,我们提出了如上图的划分方法。主要有两个原因:
- 隐式与显式建模的划分有助于我们理解特定方法的假设;
-
是否使用了额外数据或者单图像输入指示了不同的显式建模策略;
- 经过上述划分后,我们很自然的可以引申出一个极具潜在研究价值的方向:单图像输入隐式建模。
Overview of Non-blind SISR
经典的非盲图像超分方法有SRCNN、FSRCNN、LapSR、ProSR、EDSR、ESRGAN、RCAN、IMDN、RDN、RFDN等,这些方法的基本架构形式可参考下图。它们主要有这样三个主要模块:浅层特征提取模块、深层特征提取模块、 SR重建模块。
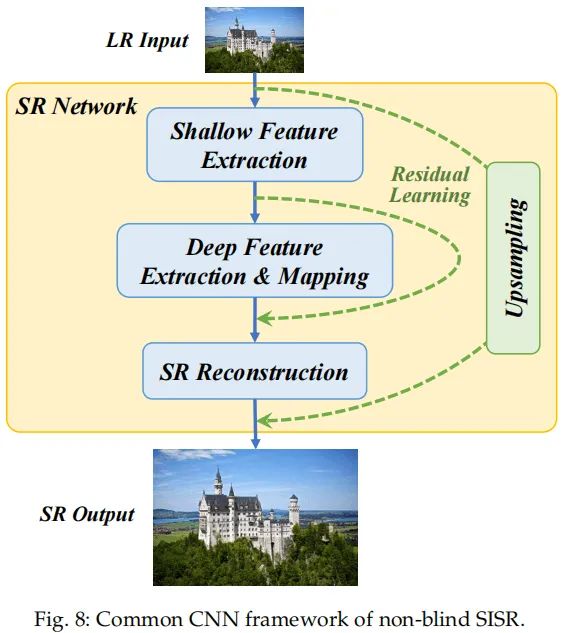
尽管非盲超分在特定退化下取得非常好的性能,但是对于复杂退化类型效果则显著下降,可参考下图。因此,盲图像超分的研究非常有价值。

Explicit Degradation Modeling
接下来,我们对近年来所提出的显式建模盲超分进行介绍。这些方法可以进一步按照是否采用了额外数据、单图像输入划分为两个子类。
Classical Degradation Model with External Dataset
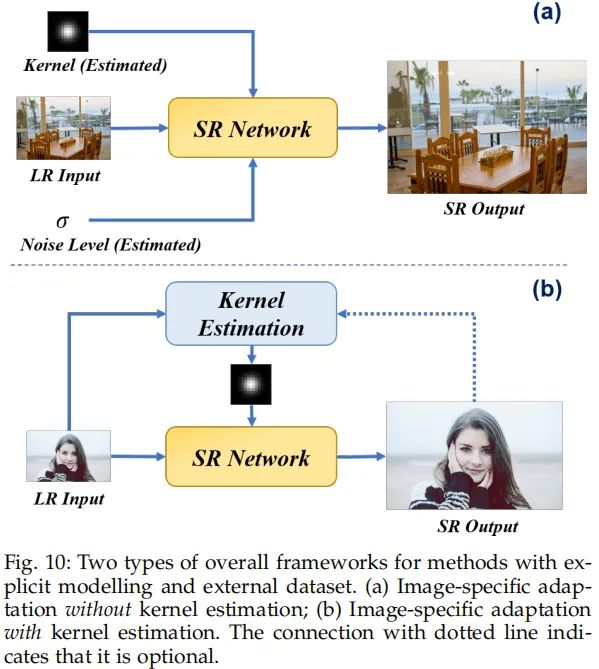
这类方法采用额外数据训练超分模型以适配不同的模糊核、噪声。具体来说,它们将退化信息参数化并作为条件输入。完成训练后,这些模型可以处理包含在训练数据种的任意退化类型。按照超分网络是否包含退化估计,我们进一步将其划分为(可参见上图):
- image-specific adaptation without kernel estimation: 它接收估计的退化信息未作输入,聚焦于如何利用先验信息提升重建质量;
- image-specific adaptation with kernel estimation:在超分过程中对退化估计添加关注。
对于第一类无需核估计的方法,其中知名的当属SRMD,它直接将先验信息与输入图像拼接,然后送入网络进行图像重建,可参见下图a。此外,UDVD采用了与SRMD类似的方法,但引入了动态卷积进一步提升重建性能。
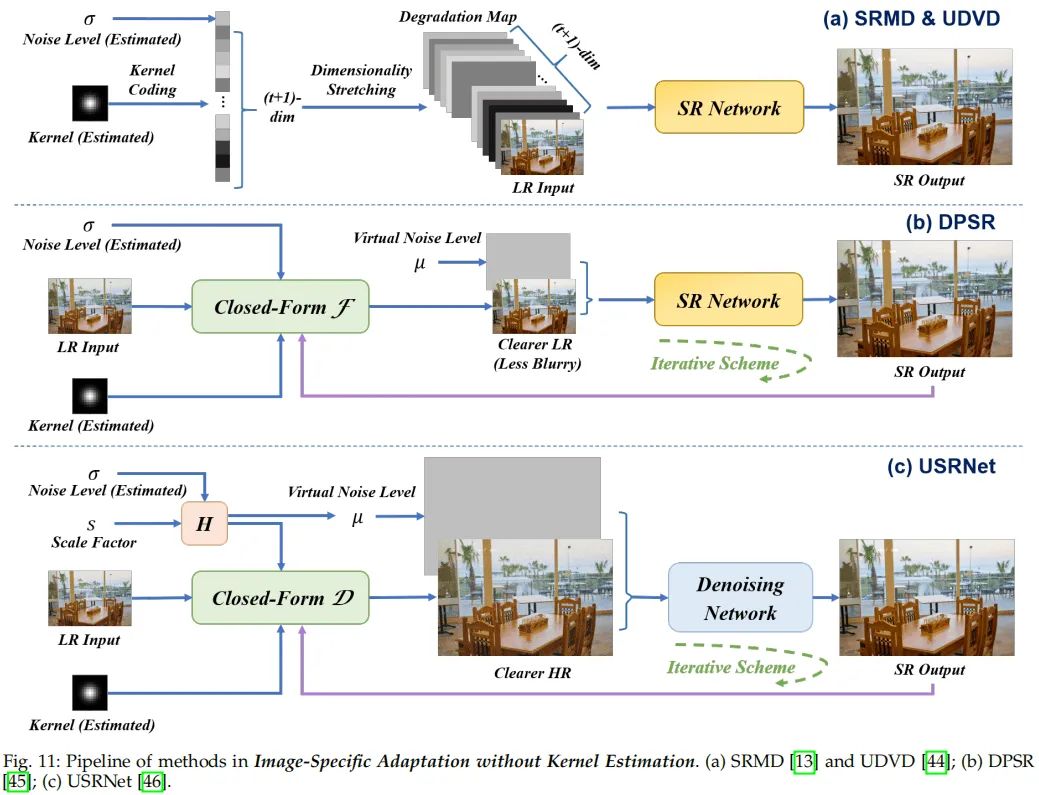
尽管SRMD扩展了超分模型的泛化性,但仍存在局限性:无法处理任意核。因此,另外一种依托MAP框架的DPSR与USRNet闪亮登场,它们采用迭代优化的思路进行处理。

这类方案的局限性在于:依赖于额外的退化先验信息,尤其是模糊核。然而,模糊核的精确估计并不容易,不精确的模糊核则会产生退化不匹配问题。上图对比了SRMD在核不匹配时的超分效果对比。
对于第二类需要核估计的方法,其中知名的方法有IKC、DAN、VBSR、KMSR、RealSR等,可参考下图。
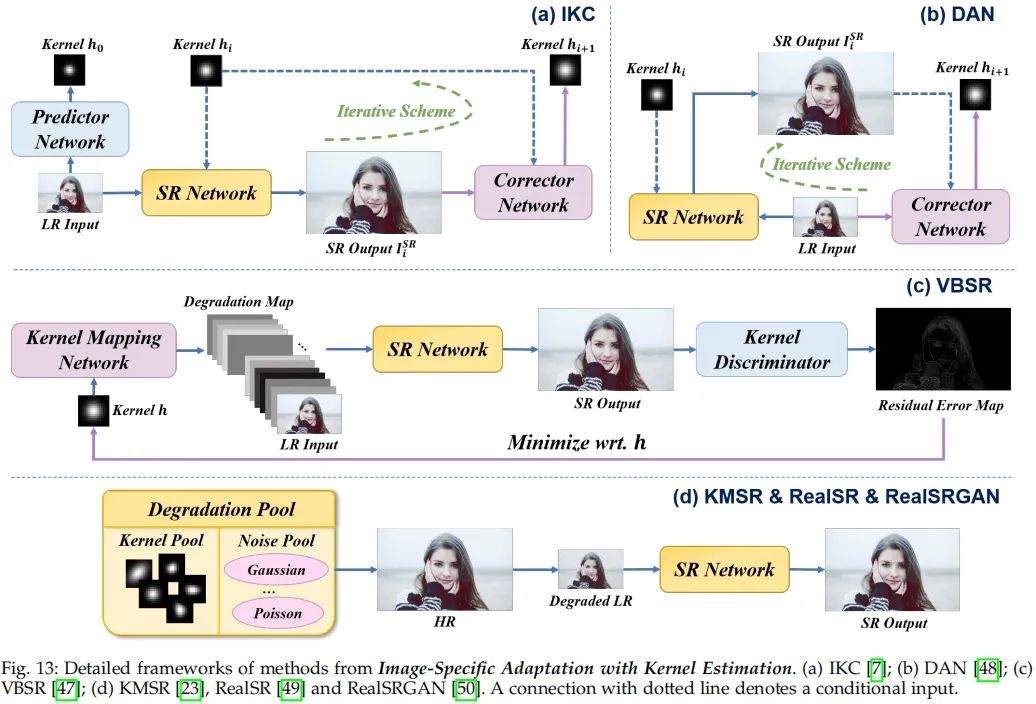
这类方法的局限在于:对于模型未覆盖的退化,这些方法无法给出令人满意的结果。下图给出了一个对比示例。

Single Image Modeling with Internal Statistics

块自相似性是自然图像的一种内在统计特性,该特性可以被量化并用于降噪、超分。上图为深度学习时代采用该相似性进行盲图像超分的方案示意图。除了之外,知名的方法还包含KernelGAN、FKP、ZSSR等,前两者旨在进行退化建模,而后者则采用自监督方式进行学习。
这类方法的局限性在于:基本假设很容易无法满足,尤其是自然图像包含各式各样的内容、场景,因此,很难采用该先验信息进行超分重建。这类方法仅能处理非常有限的场景。
Implicit Degradation Modeling
Learning Data Distribution within External Dataset
该类方法旨在从额外数据中隐式抓取退化模型。对于成对的HR-LR,监督学习方法已经取得了非常好的结果,比如NTIRE2018、AIM2020的冠军方案。真正难以处理的是退化未知的数据,现有方法往往采用GAN框架探索数据分布,可参考下图。
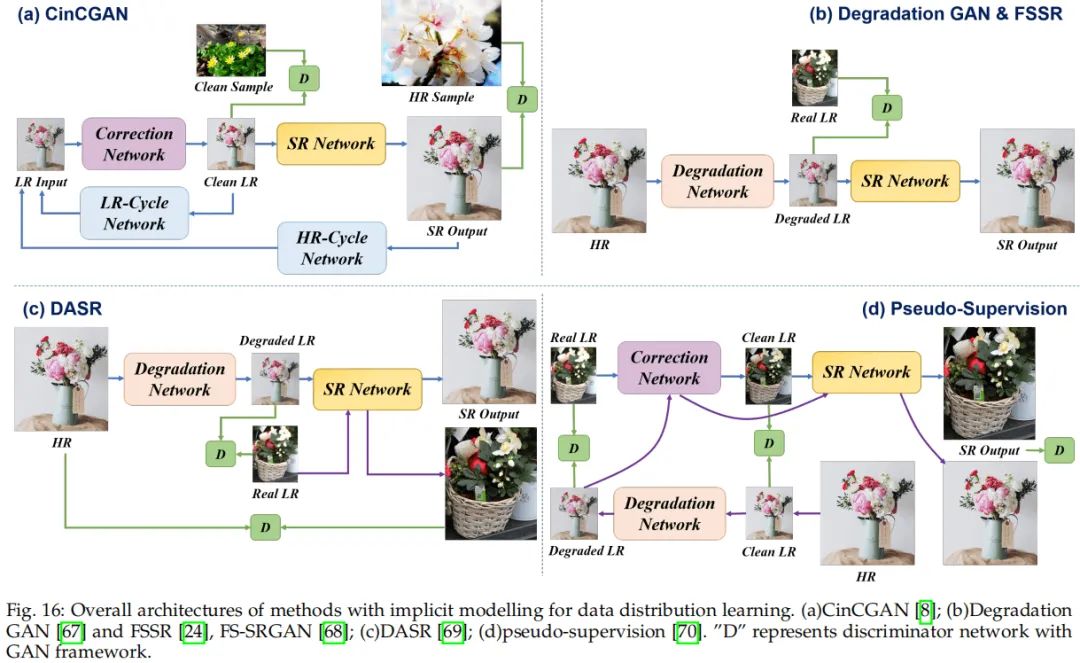
尽管这类方法看起来非常灵活有效,但仍非盲超分的“万能灵药”。下图给出了两组对比图,重建效果仍然无法令人满意。

Implicit Modeling with a Single Image: Future Direction
只要能提供成对的HR-LR,隐式建模方法看来能够处理复杂的真实退化。然而,这些方法严重依赖于GAN框架学习数据分布,而GAN导致的伪影问题则会妨碍实际应用。除了,探索更鲁棒的生成模型外,另一个尚未探索的方向值得关注:单帧输入隐式建模。
正如前面所提到,现有方法均有各自的局限性,尤其当面对的是复杂真实场景退化。比如安防视频、老照片、老电影等在我们生活中常见的图像为现有盲超分带来了新的挑战。其主要挑战在于:缺陷有效的超分先验信息。
Datasets and Competitions
在合成数据方面,常见的训练数据主要为DIV2K、Flickr2K、DIV2KRK;而测试数据则多为Settle、Set14、BSD100、Urban100;
在真实数据方面,常见的数据包含City100、DRealSR、RealSR、DPED等。
相关盲图像超分可参见下表。

Quantitative Comparison
对现有方法进行公平而系统的比较是一项非常难的事情,主要体现在以下几个方面:
- Inaccessible Code,尽管SRMD、IKC、RealSR、KernelGAN、ZSSR开源了相关code,但还有不少方法并未开源,而复现GAN类方法的难度比较大;
- Different Training Data:尽管有一些预训练模型,但仍无法公平比较,因为这些模型采用了不同的训练数据、退化类型。
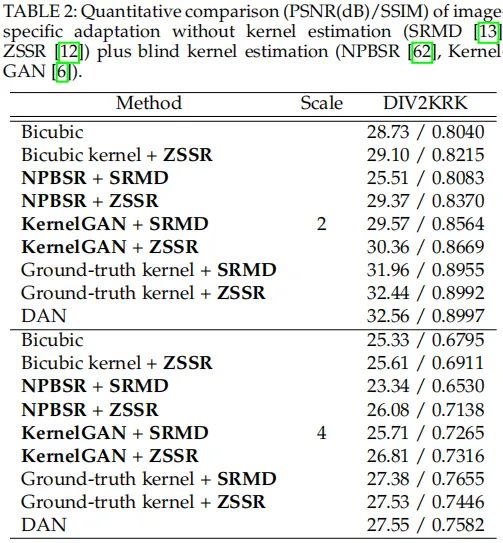
上表对比了显式建模方案的性能对比,从中可以看到:
- 采用退化信息作为额外输入的方法,如果组合适合的核估计算法可以很好的拟合盲图像超分;但是距离真实核方案仍存在显著性能差距;
- 退化信息与超分网络联合优化的DAN方案具有最佳的性能。
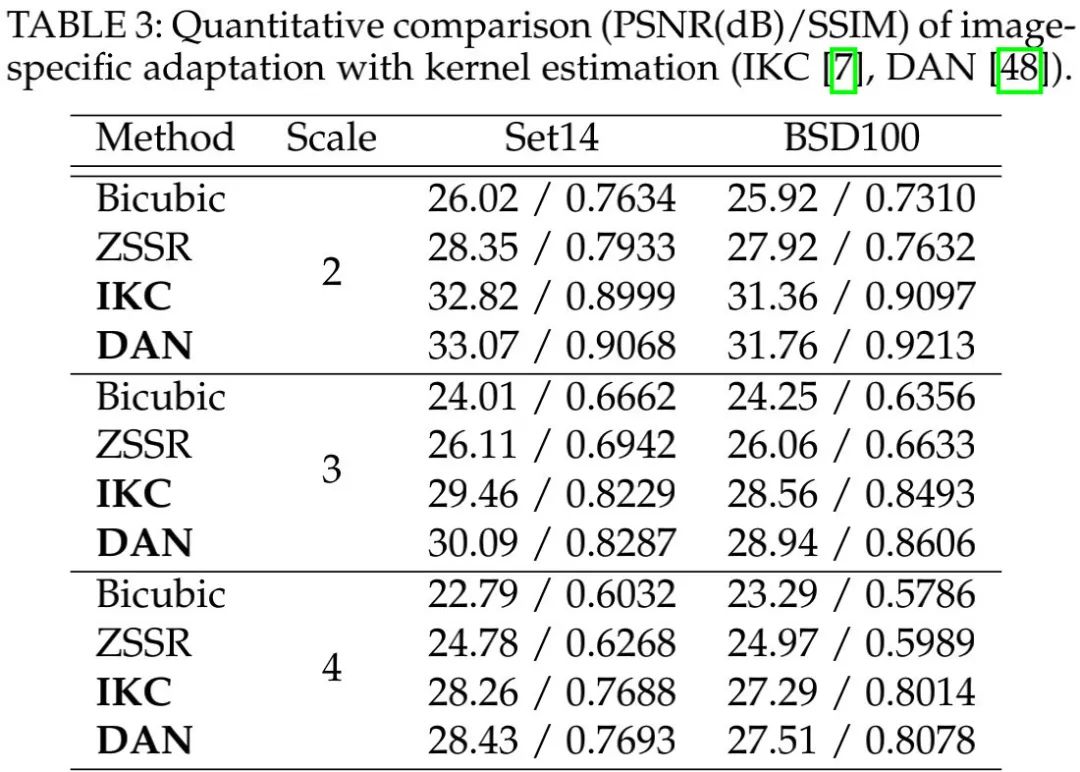
上表对比了显式建模集成核估计的两种代表性方法IKC与DAN,从中可以看到:在三个尺度上,DAN显著优于IKC。
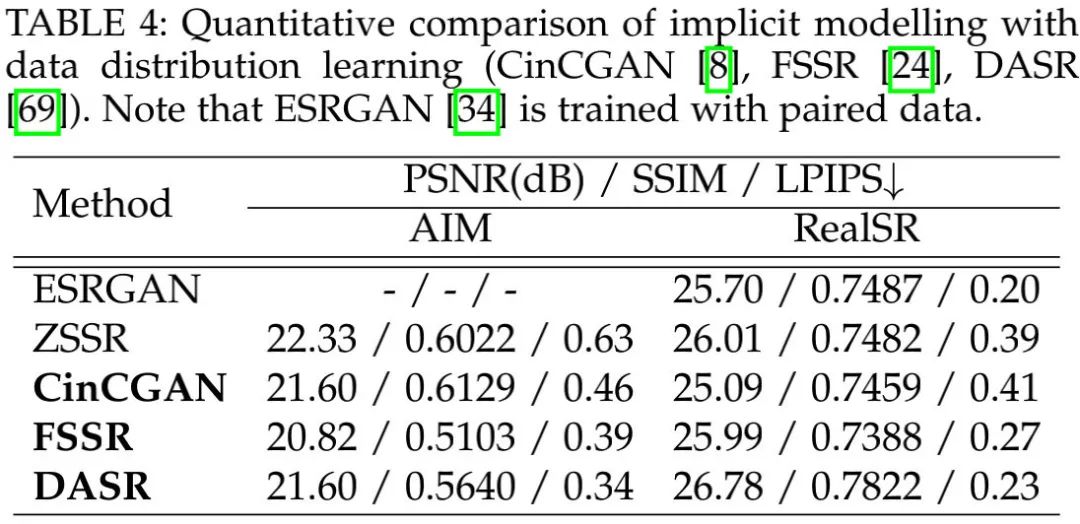
上表对比了隐式建模的几个方案的性能对比,从中可以看到:由于具有更好的减少域差异的训练策略,DASR取得了最佳的视觉质量。

上表给出了不同方案的模型在不同退化图像上的效果对比。基于上述测试图像,我们可以得出如下发现:
- 对于采用额外数据的方案,其泛化性能严重依赖于退化建模的覆盖范畴以及训练数据分布。比如SRMD、USRNet仅能处理带噪声输入;其他方法(如IKC、SRResNet)对于带噪声输入会产生伪影问题;在真实数据训练的模型对于合成数据很难产生好的结果,比如RealSR、FSSR。
- 真实场景图像确实包含更复杂的退化类型,这使其分布显著差异于合成数据。显式建模方案SRMD与IKC可以很好的处理合成图像,但对于真实图像表现差强人意。









