欢迎回来,上一周我们整理了基础课中三大结构有关内容的具体应用及案例。可以通过以下几篇推文进行回溯:
Python语言基础50课
我的Python - 100天笔记 |D1-D7
我的Python - 100天笔记 |D8-D14
列表是Python中非常常见的数据结构,在基础课中也占了不小的篇幅。今天的推送就列表相关的内容再整理。
列表是包含有索引的元素集,其中的元素可由字符、数字、字符串及子列表组成,用 list = []表示。基本操作包括:
增加元素
list.append(obj) 在列表末尾添加新的元素
list.insert(index,obj) 能够在列表任意位置添加新的元素。
删除元素
list.pop(index) 移除索引位置的元素,同时会返还被移除元素的值。
del list[index] 移除移除索引位置的元素,但不返回移除元素的值,注意中间是空格。
list.remove(obj) 移除第一个匹配到的元素。
修改元素
list[index] = obj
查找元素
list.index('obj')
列表排序
sort(list) 永久性排序。
temp_list = sorted(list) 返回一个新建的已排序列表。
list.sort(reverse=Ture) 反向排序。
列表切片
list[start:end:step] 切片是支持步长选择的。
嵌套列表的使用
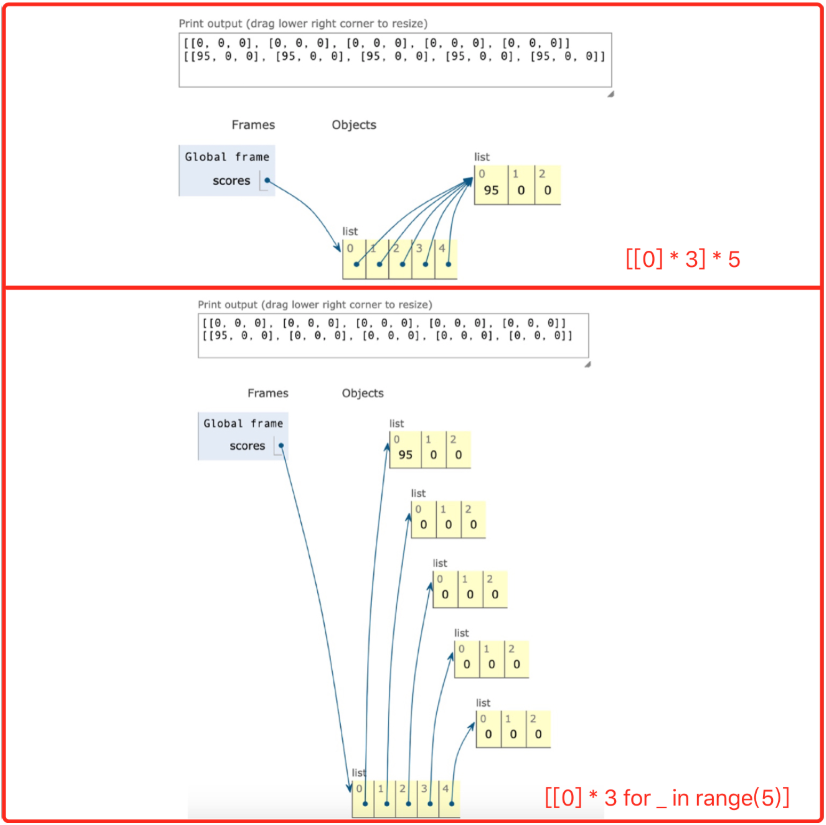
嵌套的列表可以用来表示表格或数学上的矩阵,可以用于记录多维的数据,但是需要注意的是,嵌套列表不能够使用以下的方式生成:
scores = [[0] * 3] * 5
print(scores) # [[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
# 嵌套的列表需要多次索引操作才能获取元素
正确的方式如下(生成式):
scores = [[0] * 3 for _ in range(5)]
scores[0][0] = 95
print(scores) # [[95, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
示例图如下:
第011课:常用数据结构之列表
列表生成式
[exp for iter_var in iterable]
生成式中,首先会将可迭代对象iterable中的每个元素的结果赋值给iter_var,然后通过exp得到一个新的计算值;最后把所有通过exp得到的计算值以一个新列表的形式返回。也就是与下列语句同效:
L = []
for iter_var in iterable:
L.append(exp)
类似的,还有以下两种可使用的方式:
#带过滤功能语法格式
[exp for iter_var in iterable if_exp]
#循环嵌套语法格式
[exp for iter_var_A in iterable_A for iter_var_B in iterable_B]
也就是在之前的基础上,添加判断条件或嵌套循环。
例如,过滤出一个指定的数字列表中值大于20的元素
L = [3, 7, 11, 14,22, 33, 26, 57, 99]
# 不使用列表生成式实现
list_new = []
for x in L:
if x 20:
list_new.append(x)
# 使用列表生成式实现
list_newi = [x for x in L if x > 20]
再来一个例子:把一个列表中所有的字符串转换成小写,非字符串元素移除
L = ['TOM', 'Peter', 10, 'Jerry']
# 用列表生成式实现
list1 = [x.lower() for x in
L if isinstance(x, str)]
# 用map()和filter()函数实现
list2 = list(map(lambda x: x.lower(), filter(lambda x: isinstance(x, str), L)))
我们在之前推送中聊过这类 map()和filter() 高阶函数的简单用法,高阶函数的英文为 Higher-order function ,怎么理解呢。我们从内置函数再来理解一下上面的提及到的函数名定义规则与变量一致,换句话说函数名也可以认为是一个变量。
那么,既然变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
高阶函数,我们以 map(f,list) #对列表内元素逐个处理,举个栗子:
# 对每一个元素进行平方计算
def f(x):
return x*x
for i in map(f,[1,2,3,4,5,6,7]):
print(i)
# 使用正则取列表中所有元素的关键字,省略部分代码
import re
def id(x):
return re.findall(r'ORF\d+_(.*?):',x)[0]
for
line in f:
if line.startswith('P'):
line = line.split('\t')
line1 =list(map(id,line))
print(line1)
比较来看,对于大部分需求来讲,使用列表生成式和使用高阶函数都能实现。这对于那些元素数量很大或无限的可迭代对象来说显然是更合适的,因为可以避免不必要的内存空间浪费。
enumerate函数
遍历列表时,课程中有一个函数值得关注 enumerate,该函数在循环遍历时会取到一个二元组,解包之后第一个值是索引,第二个值是元素,下面是一个简单的对比。
items = ['Python', 'Java', 'Go', 'Swift']
for index in range(len(items)):
print(f'{index}: {items[index]}')
for index, item in enumerate(items):
print(f'{index}: {item}')
第013课:列表和元组的应用
终于梳理了生成式的一些用法,同时从比较中引申出不同方法实现相同目的的用法,希望对你有启发~
参考资料
jackfrued/ Python-Core-50-Courses
https://www.cnblogs.com/yyds/p/6281453.html
往期推荐
ComplexHeatmap包更新支持pheatmap转换
生信技能树目前已经公开了三个生信知识库,记得来关注哦~
每周文献分享
https://www.yuque.com/biotrainee/weeklypaper
肿瘤外显子分析指南
https://www.yuque.com/biotrainee/wes
生物统计从理论到实践
https://www.yuque.com/biotrainee/biostat
友情宣传
强烈建议你推荐给身边的博士后以及年轻生物学PI,多一点数据认知,让他们的科研上一个台阶:
•生信爆款入门-全球听(买一得五)(第4期) ,你的生物信息学入门课。•数据挖掘第2期(两天变三周,实力加量),医学生/医生首选技能提高课。•生信技能树的2019年终总结 ,你的生物信息学成长宝藏•2020学习主旋律,B站74小时免费教学视频为你领路







