Confusion Matrix,混淆矩阵也称误差矩阵,是表示机器学习预测精度的一种标准格式,用n行n列的矩阵形式来表示。
对于一份机器学习数据,一般会先分成Trainning Data和Testing Data,分别用于构建模型和模型评价。由于对于同一份数据而言,往往有多种机器学习算法可供选择,比如决策树、K近邻算法及logistic回归,那么可以同时做上述模型,然后选出最佳模型(Cross Validation),此时模型间的比较可以选择使用Confusion Matrix来对比。
以一个例子来看一下,有如下数据,使用Chest Pain、Good Blood Circ.、Blocked Arteries及Weight来预测病人是否患有Heart Disease。
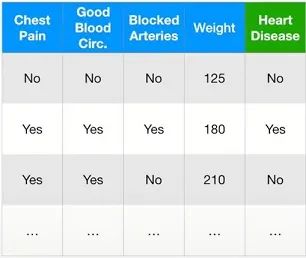
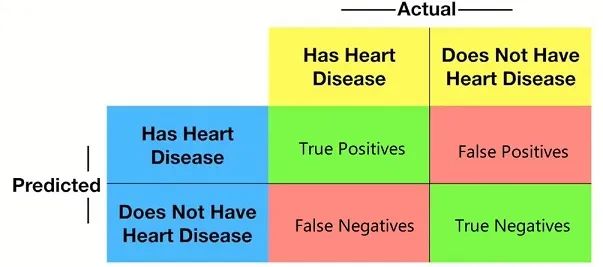
比如使用决策树构建好模型后,会对TestingData进行预测,此时可以将预测值和实际值作如下表格,此表格就是Confusion Matrix。具体而言,Actual代表样本的真实情况,Predicted代表模型预测的样本情况,绿色代表模型正确预测了结果,而红色代表模型错误预测了结果。
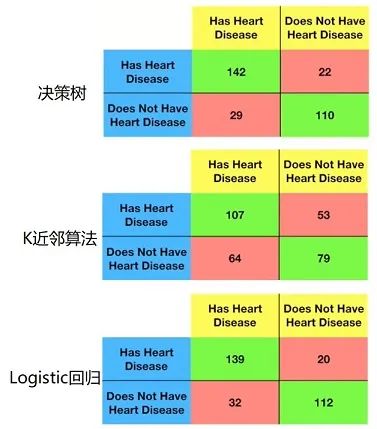
假如决策树、K近邻算法及logistic回归的ConfusionMatrix结果如下,那么可以很明显的得出决策树的预测结果最好。
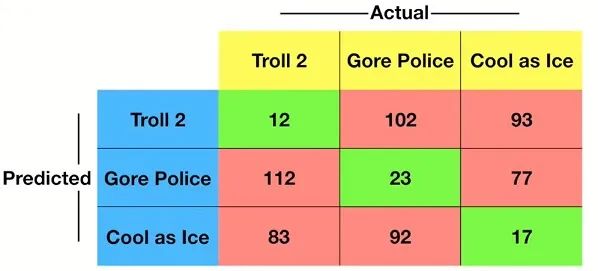
这是比较简单的情况,如果对于结果是比较复杂的情况,比如预测结果是三个分类的,询问一个人喜欢Jurassic Park III、Run for your Wife、Out Kold、Howard the Duck与否,从而预测其喜欢Troll2、Gore Plice、Cool As Ice三部电影中的哪一部。
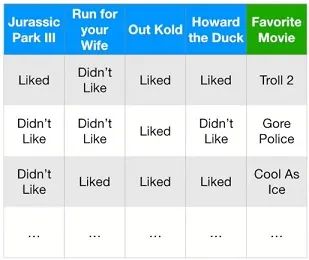
那么其Confusion Matrix就是如下样式,绿色为正确预测结果,红色为错误预测结果。
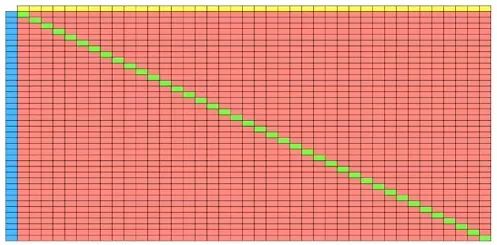
进一步的,如果结果有40个分类,那么Confusion Matrix也会是40*40的一个矩阵,而对角线就是正确预测的结果。
参考资料:
StatQuest课程:https://statquest.org/video-index/
文末友情宣传
强烈建议你推荐给身边的博士后以及年轻生物学PI,多一点数据认知,让他们的科研上一个台阶:
每周文献分享
https://www.yuque.com/biotrainee/weeklypaper
肿瘤外显子分析指南
https://www.yuque.com/biotrainee/wes
生物统计从理论到实践
https://www.yuque.com/biotrainee/biostat










