机器学习(Machine learning)是关于计算机系统执行特定任务的算法和统计模型的科学研究,它不使用明确的指令,而是依靠模式和推理来完成任务。(Wikipedia)
机器学习被认为是人工智能(Artificial Intelligence)的子集,机器学习中的无监督式的探索性数据分析也被称为数据挖掘(Data mining)。
机器学习的用途分为两种:分类(classification)和预测(prediction),这里的“预测(prediction)”容易引起误解,因为机器学习的工作本来就是在做预测(做分类也是在做预测),这里的“预测(prediction)“和分类相对应,两者可以认为是分别对连续变量和分类变量进行预测。也就是说,分类是预测分类变量的分类(是否垃圾邮件,是否购买),而“预测(prediction)”是预测出一个连续变量的具体值(身高、体重等)。
预测型与分类型机器学习的例子
机器学习中使用的统计模型有人工神经网络Artificial neural networks、决策树Decision trees、支持向量机Support vector machines、回归分析Regression analysis、贝叶斯推断Bayesian networks、遗传算法Genetic algorithms。
决策树(decision tree)就是典型的分类机器算法,如下就是一个决策树的样式:它是一个树状结构,根节点和中间节点是问题,左分支代表答案为“是”,右分支代表答案为“否”。末节点是决策树的结果:喜欢StatQuest、不喜欢StatQuest :( 。也就是说这个决策树是为了预测一个人是否喜欢StatQuest。
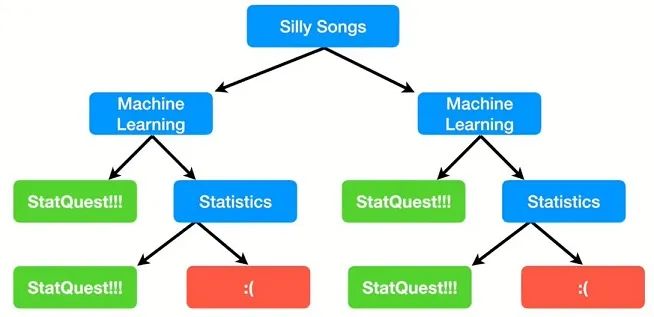
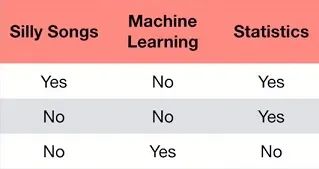
如果对于三个人获取如下信息,那么对于第一人,喜欢Silly Songs,然后进入左侧分支,不喜欢Machine Learning,再进入右侧分支,喜欢Statistics,进入左侧分支,于是预测此人喜欢StatQuest。对第二人和第三人的预测结果也都是喜欢StatQuest,其中第三人只需要问完Machine Learning即可得出分类结果。
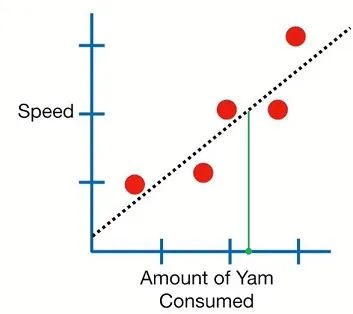
线性回归是一种经典的预测型机器学习算法,(回归也可以解决响应变量是分类变量的问题:如Logistics回归)。如下图,可以获得Speed和Yam食用量之间的线性预测结果,并可据此求出一个人当他的Yam使用量是2.3时的速度是多少。
一个关键的机器学习问题——bias variance tradeoff
对于一个机器学习而言,原始数据至少会分为两种:Training Data用于构建模型和Testing Data用于评价模型的优劣。
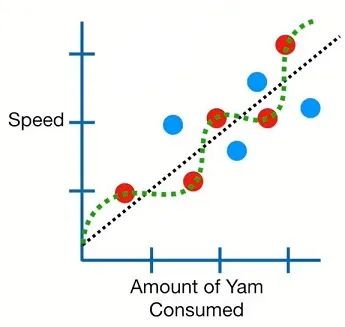
仍以上述的线性回归为例,如下图,红色点是建模用的原始数据,蓝色点是测试数据,黑色线为线性回归线,绿色线为一种新拟合的回归线。
结果表明绿色回归线的拟合结果要远远好于黑色的线性回归,因为它的拟合度是100%。但是如果此时使用测试数据去衡量两者的预测效果,可以发现其预测值的偏差要大于线性回归的偏差。
也就是说,并不是模型的拟合度高就一定有优秀的预测能力。
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了算法本身的拟合能力,拟合越差偏差越大。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响,模型受数据扰动至越差,则方差越大(预测能力也越差)。
黑色回归线的偏差虽然大于绿色回归线,但是其预测能力更好,虽然没有计算方差,但是可以预见的是其方差是比较低的。(bias variance tradeoff中的偏差和方差不同于常规使用的偏差和方差,注意辨别)
为何会有训练集的变动?
实际的机器学习中,会有很多种模型可用,如K近邻算法、支持向量机,到底选择哪一个模型可以通过交叉验证来解决,也就是将可用模型都计算测试一次,哪个优秀就使用哪个模型。
在这个过程中有一个问题,就是哪一部分作为Training Data,哪一部分作为Testing Data,而实际操作时,是将所有的数据拆分方案(如将数据分为4份,Testing Data分别是1、2、3、4份,而剩余为Training Data,则共有4种数据拆分方案)都做一遍,因此也就存在训练集(Training Data)的变动。
参考资料:
StatQuest课程:https://statquest.org/video-index/
文末友情宣传
强烈建议你推荐给身边的博士后以及年轻生物学PI,多一点数据认知,让他们的科研上一个台阶:
每周文献分享
https://www.yuque.com/biotrainee/weeklypaper
肿瘤外显子分析指南
https://www.yuque.com/biotrainee/wes
生物统计从理论到实践
https://www.yuque.com/biotrainee/biosta










