hi,欢迎回来,这里是生信Python3学习笔记系列阶段性小结2。
又过了三个月不知道有没有新的小伙伴的一起加入呢,回顾近半年的笔记,在2020的第二周再重新回顾和梳理一遍,以便查漏补缺。
一路走来,从来不是开拓者。慢慢来,比较快。
也欢迎大家翻阅我的上一篇内容 菜鸟团2019周四发生的那些事。
回顾
上一阶段的小结 中我们就几个方面展开描述,他们包括:
and as assert break class continue def del elif else except exec finally for from global if in import is lambda not or pass print raise return try while with yield
掌握基本数据类型及操作
基本数据类型包括数字、字符串、列表、元组和字典。数字和字符串很好理解,列表和元组最大的差别就是元组是 Immutable ,这会带来更多安全性及性能优化。字典可以理解为hash,元素以关键对的形式 x:y呈现,键是唯一不变的,在生信分析中可用作信息提取,如id对应的基因名、注释,或者是fa序列。
Python当然支持正则表达式。不同的数据类型能够涵盖的信息是不一样,也就会对应函数的使用。
使用函数
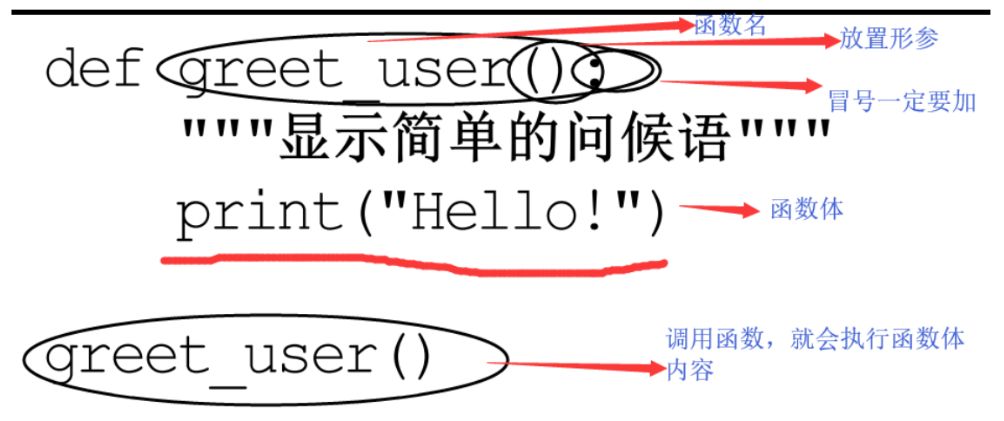
函数从使用范围来看可以分为主函数和子函数,当然变量也会全局和局部之分;从实现不同的功能角度来区分,比如 匿名函数 以及高阶函数。合理使用自定义函数将会使你的代码高效、可读。

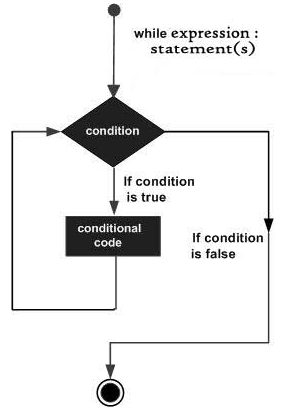
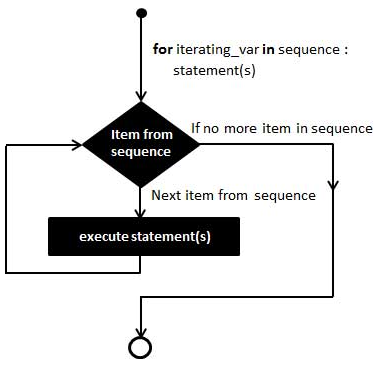
三大结构
python语言中的三大结构指的循序、分支和循环。和其他的逻辑运算一样,python3的与运算使用and 连接,或
运算使用or连接,非运算使用not Ture。需要注意的是python中None是一个一个特殊空值,并不是0,因为0是有意义的。要提一下的是判断:
小实战;
判断基因的位置信息
python3 脚本小实战(代码放送)
字典与FASTA文件序列抽提
如何优雅的数月饼| 2019国自然信息爬取
过渡
更多应用场景ing
在小结1中我们提到几个数据处理和可视化模块(包):NumPy、Pandas、matplotlib、seaborn、pyecharts;python;类和对象以及流程作图。
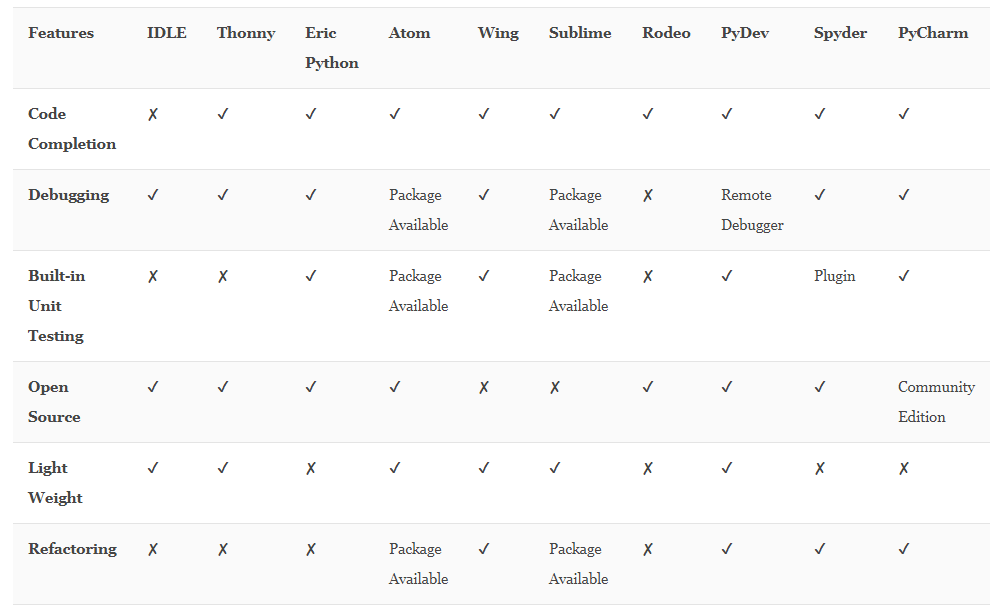
工欲善其事必先利其器
在这里系统介绍了 PyCharm 的使用方法及小技巧,PyCharm在2019年经历了三个大版本 迭代,可见生态非常良好,且受众诸多。除了我们入门使用的社区版本外,付费版也在不断追求更加高级的玩法,形成闭环。
当然还有其他的 IDE和代码编辑器也足够出色,萝卜青菜各有所爱,有兴趣的小伙伴可以翻阅尝试,在后期的可视化上我也会使用更容易展示的平台。
如果你也和我的喜好一样,使用 Pycharm,除了开场拥有三个BUFF外,
外加一个公开的秘籍传授与你:安装autopep8模块,从此让你的代码「精致」好读,就好比练字时临摹了大家的字帖一般。
编程基础与规范代码
类与对象


类
类(英语:class)在面向对象编程中是一种面向对象计算机编程语言的构造,是创建对象的蓝图,用于描述具有相同属性和方法。
类是抽象的模板,我更愿意解释为分类,可以涵括一系列内容(对象),也是相似事物的概括。在python语言中,描述对象特征的被称为属性,表示事物的行为的成为方法(函数)。
对象
对象(英语:object),是一个存储器地址,其中拥有值,这个地址可能有标识符指向此处。对象可以是一个变量,一个数据结构,或是一个函数。
对象是类的一个具体事物。
对象是通过类来创造的,拥有相同的方法,但是对象和对象之间会有差异;类好比是模板,可以创建多个对象,根据类创造对象的过程就称为 实例化,而之后对象也就具备了类的属性和方法。这样就会有继承与模块调用。
Python 有一条哲学理念是:
一切皆对象。
你也是。

NumPy
能干嘛?
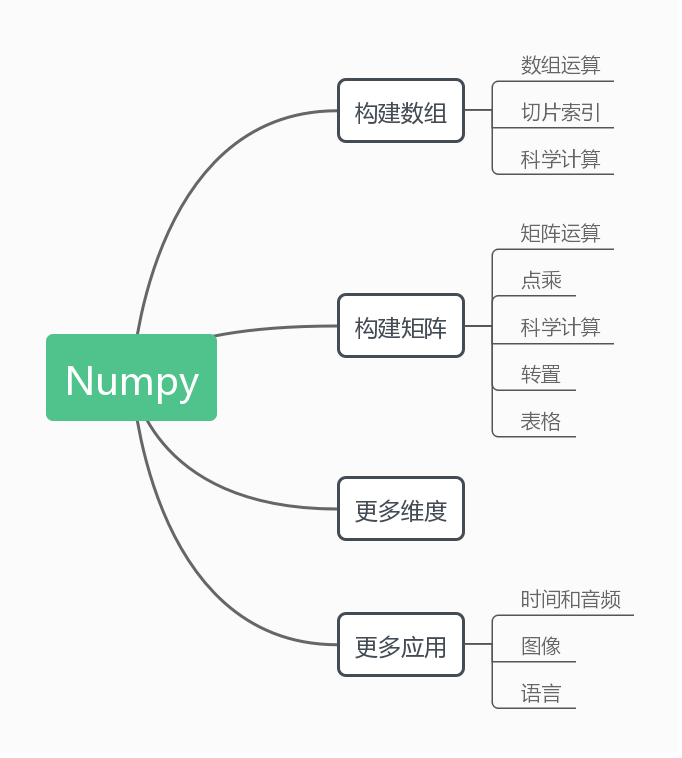
Numpy 主要用于数据分析,整体的模式有点类似于小型的R。它提供多了维数组对象,多种派生对象(如:掩码数组、矩阵)以及用于快速操作数组的函数及API,它包括数学、逻辑、数组形状变换、排序、选择、I/O 、离散傅立叶变换、基本线性代数、基本统计运算、随机模拟等等。
在学习NumPy包的过程中,首先要理解数组的概念
import numpy as np
#定义
my_array_d = np.array([1, 2, 3, 4, 5])
#0或1
my_new_array_0 = np.zeros((5))
my_new_array_1 = np.ones((3,4))
#随机数组
my_random_array_r = np.random.random((5))
#二维数组
my_2d_array = np.zeros((2,3))
#三维及多维
array = np.arange(27).reshape(3,3,3)
一维二维三维的背后的数学知识概要为:
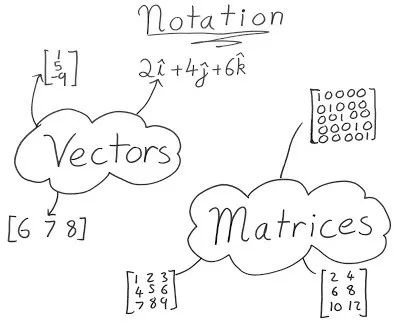
矢量是具有方向和幅度的量。它们通常用于表示速度,加速度和动量等事物。向量有很多种表现方式,最常用的就是将其写为n元组的形式,如(1,4,6,9)。这也是我们在NumPy中表示他们的方式。矩阵类似于矢量,可以通过给出它所在的行和列来引用矩阵中的值。在NumPy中,我们能够通过传递一系列数值来制作数组。
Numpy 自带了很多函数与库,以及多维数组的切片方式,例如:
# MD slicing
print(a[0, 1:4]) # >>>[12 13 14]
print(a[1:4, 0]) # >>>[16 21 26]
print(a[::2,::2]) # >>>[[11 13 15]
# [21 23 25]
# [31 33 35]]
print(a[:, 1]) # >>>[12 17 22 27 32]
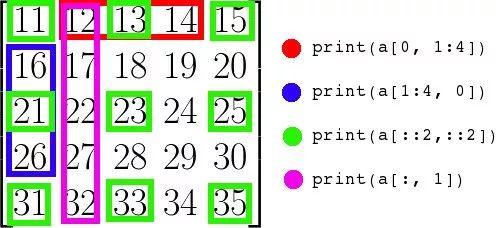
注意,在行的位置我们使用了:代替,因此只取第二列,需要注意的是索引默认是从0开始的,当然如果一开始你定义了索引也是可以从1开始的。这个类似于shell中cut -f 2 *txt的操作。如果不知道数组的大小,可以使用print(my_2d_array)方式查看数组有几行几列。在NumPy中还有高阶索引,例如获得特定元素的花式索引、条件过滤的布尔屏蔽、降维获得一个维度的缺省索引及Where函数:
# Where
a = np.arange(0, 100, 10)
b = np.where(a c = np.where(a >= 50)[0]
print(b) # >>>(array([0, 1, 2, 3, 4]),)
print(c) # >>>[5 6 7 8 9]
数组运算
加减乘除比较好理解,这里提一下点积的数学知识点:
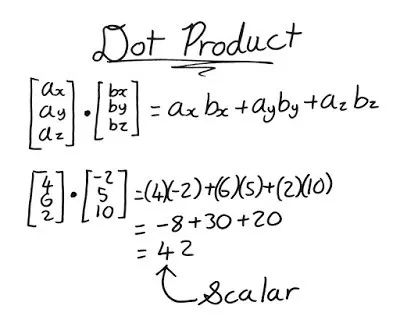
运算符也是一个很好用的工具,可以快速计算最大值data.max()、最小值data.max()、均值data.min()、标准差data.std()、求和data.sum()等。
NumPy图解 | NumPy正确食用指南
Pandas
这又是啥?
Pandas是一个基于Numpy专业的数据结构化分析工具,可用于数据挖掘和数据分析,同时也提供数据清洗功能。
基础
1.Series
Series 是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。
2.DataFrame
DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。包括一维、二维及多维。
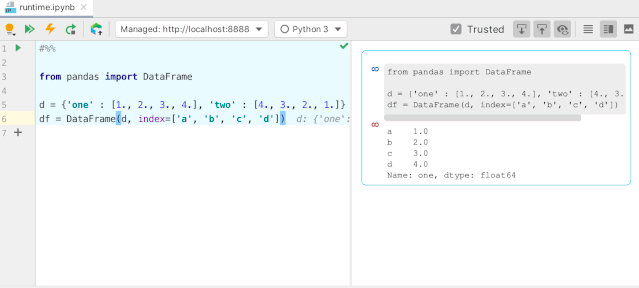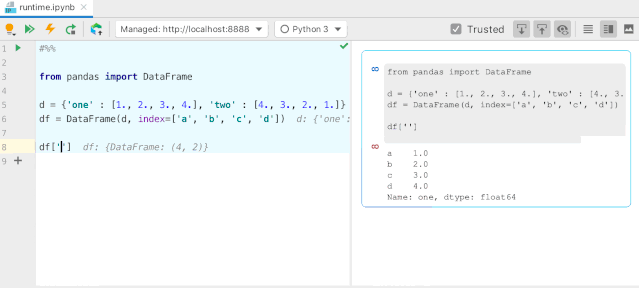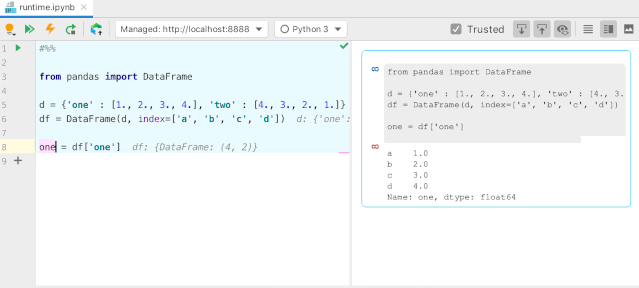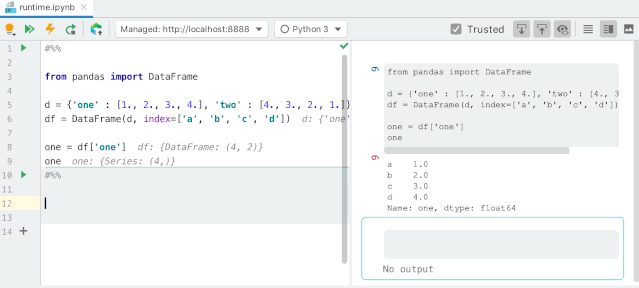
#用 Series 字典或字典生成 DataFrame
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two': pd.Series([1., 2
., 3., 4.], index=['a', 'b', 'c', 'd'])}
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0
#用多维数组字典、列表字典生成 DataFrame
d = {'one': [1., 2., 3., 4.], 'two': [4., 3., 2., 1.]}
pd.DataFrame(d, index=['a', 'b', 'c', 'd'])
one two
0 1.0 4.0
1 2.0 3.0
2 3.0 2.0
3 4.0
1.0
#用结构多维数组或记录多维数组生成 DataFrame
data = np.zeros((2, ), dtype=[('A', 'i4'), ('B', 'f4'), ('C', 'a10')])
pd.DataFrame(data)
A B C
0 1 2.0 b'Hello'
1 2 3.0 b'World'
#index 和 columns 属性分别用于访问行、列标签:
pd.DataFrame(d, index=['d', 'b', 'a'], columns=['two', 'three'])
two three
d 4.0 NaN
b 2.0 NaN
a 1.0 NaN
能干嘛?
读写excel文件!
import pandas as pd
#特定读取
cols = [1, 2, 3]
data = pd.read_excel('expression_text.xlsx',sheet_names='FPKM', usecols=cols)
df.head()
#查看列表大小
data.shape
#统计行数和列数
data.count
#设置数据或列的数据类型
df = pd.read_excel('example_sheets1.xlsx',sheet_name='Sheet1',
header=1,dtype={'Names':str,'ID':str,
'Mean':int, 'Session':str})
#缺失数据的处理
df = pd.read_excel('my_text.xlsx', na_values="Missing", usecols=cols)
df.head()
#写入
df = pd.DataFrame({'Names':['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
'Age':[21, 22, 20
, 19, 18, 23]})
df.to_excel('NamesAndAges.xlsx')
取代excel的vlookup函数
#加载包
import pandas as pd
#import xlrd
#读取表格
df1 = pd.read_excel(r'C:\Users\user\Desktop\test.xlsx')
df2 = pd.read_excel(r'C:\Users\user\Desktop\all.xlsx',usecols=[7,8])
#核心
df3 = pd.merge(df1,df2,on='PathwayEntry',how='left')
#修正列
last_col = df3.pop(df3.columns[-1])
df3.insert(1, last_col.name, last_col)
#保存表格
df3.to_excel(r'C:\Users\user\Desktop\3.xlsx', sheet_name='result')
核心代码即加载 ->读取两张表格 ->处理 ->保存;关键就是这个函数 merge,使用方法如下:
DataFrame.merge(self, right, how='inner', on=None
, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
on:join用来对齐的那一列的名字,即字典中的key;在这里需要理解一下的是how这个参数
how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
Type of merge to be performed.
plotly可视化
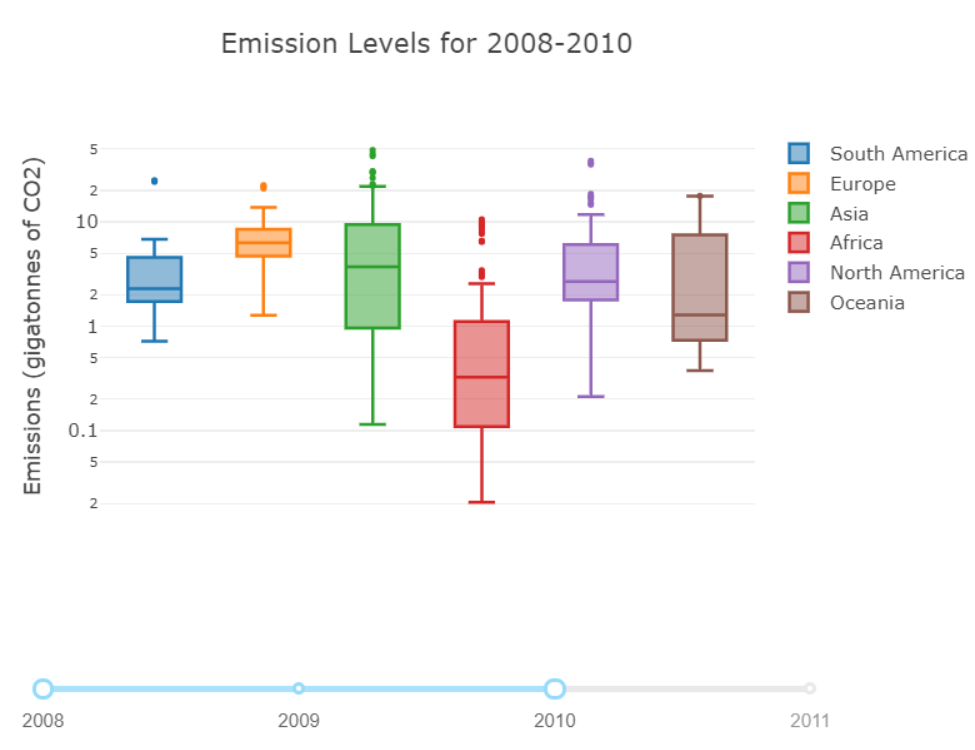
以下图片在展示时使用了 plotly.offline.init_notebook_mode() 下的 jupyter notebook。举一个箱线图的例子:
import plotly
import plotly.express as px
'''初始化jupyter notebook中的绘图模式'''
plotly.offline.init_notebook_mode()
df = px.data.tips()
fig = px.box(df, x="time", y="total_bill", color="smoker",
notched=True, # used notched shape
title="Box plot of total bill"
)
fig.show()
快速定义绘图类型
'''构造trace,配置相关参数'''
# 散点图
trace = go.Scatter(
x = random_x,
y = random_y,
mode = 'markers'
)
# 折线图
trace2 = go.Scatter(
x = random_x,
y = random_y2,
mode = 'lines',
name = 'lines'
)
# 带点的折线图
trace2 = go.Scatter(
x = random_x,
y = random_y2,
mode = 'lines+markers',
name = 'lines+markers'
)
定义 Layout
'''创建layout对象'''
layout = go.Layout(title='测试',
font={
'size':22,
'family'
:'sans-serif',
'color':'9ed900'},
xaxis={
'title':'这是横坐标轴',
'titlefont':{
'size':30
},yaxis={
'showline':False,
'showgrid':True,
'gridcolor':'#3d3b4f',
'zeroline':False
})
导出格式
image:str型或None,控制生成图像的下载格式,有'png'、'jpeg'、'svg'、'webp',默认为None,即不会为生成的图像设置下载方式
filename:str型,控制保存的图像的文件名,默认为'plot'
image_height:int型,控制图像高度的像素值,默认为600
image_width:int型,控制图像宽度的像素值,默认为800
未完待续
未来会在查漏补缺的基础上,添加更多的场景应用及可视化,2020与你一起学习,继续前行,加油!
最后友情宣传一下生信技能树:
你可能会需要:
广州专场(全年无休)GEO数据挖掘课,带你飞(1.11-1.12)和 生信入门课全国巡讲2019收官--长沙站











