
对于二分类问题,使用模型预测的值和实际的肯定会有所偏差,那么我们是如何来评价分类器的优良呢?今天就给大家介绍几个常用的概念,对这块内容有个系统的认知~
四个基本概念
首先给大家介绍四个基本概念:
TP(True Positive):真阳性 ,预测为正,实际也为正;
FP(False Positive):假阳性,预测为正,实际为负,这就是统计学上的第二类错误(Type II Error);
FN(False Negative):假阴性,预测为负、实际为正,这就是统计学上的第一类错误(Type I Error);
TN(True Negative):真阴性,预测为负、实际也为负。
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):
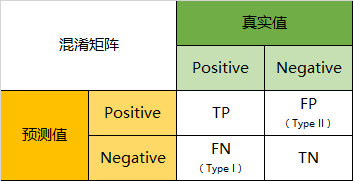
预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望 TP 与 TN 的数量大,而 FP 与 FN 的数量小。但是,混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。因此混淆矩阵在基本的统计结果上又可以延伸出如下 4 个概念:
准确率(Accuracy)
精确率(Precision)
灵敏度(Sensitivity)
特异度(Specificity)
模型整体效果:准确率
准确率 Accuracy 就是所有预测正确的所有样本除以总样本,代表分类器对整个样本判断正确的比重,通常来说越接近 1 越好。
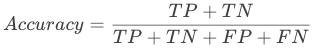
但准确率有时候过于简单, 不能全面反应算法的性能,除了识别率,还有一些常用的指标,就是接下来要介绍的 F1-Score, Recall, Precision。
精确率,召回率和 F1score
精确率(Precision),即实际是正类并且被预测为正类的样本占所有预测为正类的比例,精确率更为关注将负样本错分为正样本(FP)的情况。
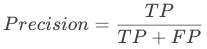
灵敏度(Sensitivity)又被称为召回率(Recall),即实际是正类并且被预测为正类的样本占所有实际为正类样本的比例,召回率更为关注将正样本分类为负样本(FN)的情况。
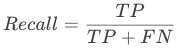
构建模型,我们当然是希望,Precision 和 Recall 都比较高,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是正确的,那么 Precision 就是 100%,但是 Recall 就很低;而如果我们把所有结果都返回,那么比如 Recall 是 100%,但是 Precision 就会很低。因此在不同的场合中需要自己判断希望 Precision 比较高或是 Recall 比较高。所以为了同时兼顾精确度和召回率,我们可以引出另一个评价指标 —— F1-Score(F-Measure)。将两者的调和平均数作为考量两者平衡的综合性指标。两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,因此我们追求尽量高的 F1-Score,能够保证我们的精确度和召回率都比较高。F1-Score 在 [0,1] 之间分布,越接近 1 越好。
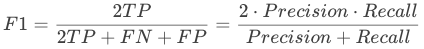
此外还有 F2 分数和 F0.5 分数。F1 分数认为召回率和精确率同等重要,F2 分数认为召回率的重要程度是精确率的 2 倍,而 F0.5 分数认为召回率的重要程度是精确率的一半。计算公式为:
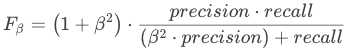
ROC 曲线和 AUC 值
上述评价指标还有一个孪生兄弟,就是 ROC 曲线和 AUC 值。
ROC曲线:全称是“受试者工作特性”曲线(Receiver Operating Characteristic),源于二战中用于敌机检测的雷达信号分析技术,是反映敏感性和特异性的综合指标。
它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,判别的准确性越高。
在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
那么 ROC 曲线是如何绘制出来的呢?
首先需要了解几个基本概念:
1)真阳性率(TPR, True positive rate):所有实际为阳性的样本被正确地判断为阳性的个数与所有实际为阳性的样本个数之比,TPR 又被称为 Sensitivity(灵敏度);
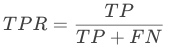
2)假阳性概率(FPR, False positive rate):所有实际为阴性的样本被错误地判断为阳性的个数与所有实际为阴性的样本个数之比,FPR 也等于 1-Specificity。
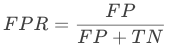
ROC曲线其实就是以FPR为横坐标,TPR为纵坐标绘制出来的曲线。首先,根据机器学习中分类器的预测得分对样本进行排序 ,接着按照顺序逐个把样本作为正例进行预测,计算出 FPR 和 TPR,最后分别以 FPR、TPR 为横纵坐标作图即可得到 ROC 曲线。
AUC(Area Under Curve)就是为 ROC 曲线下方的那部分面积的大小。我们往往使用 AUC 值作为模型的评价标准,是因为很多时候 ROC 曲线并不能清晰的说明哪个分类器的效果更好,AUC 值介于 0.5 到 1.0 之间,较大的 AUC 值代表分类器效果更好。
参考
https://blog.csdn.net/sinat_28576553/article/details/80258619
https://blog.csdn.net/matrix_space/article/details/50384518
https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839
猜你喜欢
支持向量机 sklearn 参数详解
一文带你了解什么是支持向量机
机器学习实战 | 逻辑回归
机器学习实战 | 朴素贝叶斯
机器学习实战 | 决策树
机器学习实战 | k-邻近算法
一起来学习机器学习吧~










