
概述
逻辑回归(Logistic Regression,简称 LR)虽然名字中带有“回归”二字,但其实是一种线性分类器,其本质是由线性回归变化而来的一种广泛使用于分类问题中的广义回归算法。要理解逻辑回归从何而来,首先要理解线性回归。线性回归是机器学习中最简单的的回归算法,它写作:
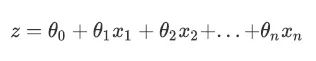
θ 被统称为模型的参数,其中 θ0 被称为截距(intercept), θ1~θn被称为系数(coefficient),这个表达式,其实和我们小学时就熟知的 y=ax+b 是同样的性质。使用矩阵表示这个式子就是:
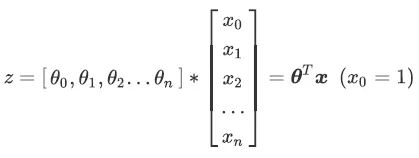
线性回归即是要构造一个预测函数来映射输入的特征矩阵 x 和标签值 y 的线性关系。通过函数,线性回归使用输入的特征矩阵 X 来输出一组连续型的预测标签值,。那如果我们的标签是离散型变量,尤其是,如果是满足0-1分布的离散型变量,要怎么办呢?这时候就可以通过引入联系函数(link function),将线性回归方程 z 变换为 g(z),并且令 g(z) 的值分布在 (0,1) 之间,且当 g(z) 接近 0 时样本的标签为类别 0,当 g(z) 接近1时样本的标签为类别 1,这样就得到了一个分类模型。而这个联系函数对于逻辑回归来说,就是 Sigmoid 函数:
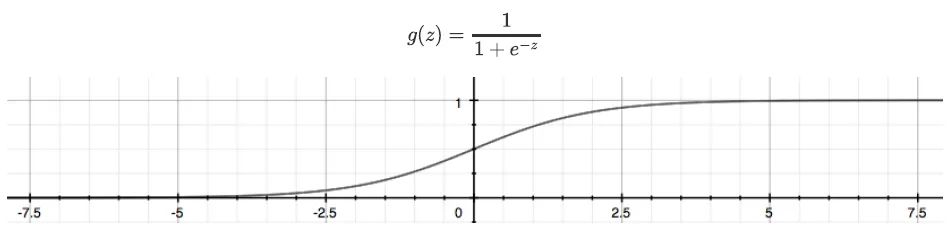
Sigmoid 函数是一个 S 型的函数,当自变量 z 趋近正无穷时,因变量 g(z) 趋近于 1,而当 z 趋近负无穷时,g(z) 趋近于0,它能够将任何实数映射到 (0,1) 区间,使其可用于将任意值函数转换为更适合二分类的函数。
因此我们可以得到二元逻辑回归模型的一般形式:
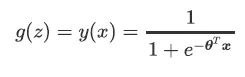
转换为矩阵形式就是:

确定了分类器的函数形式之后,现在的问题就是:最佳回归系数是多少?如何确定它们的大小?
损失函数
衡量参数的优劣就需要引入损失函数的概念,损失函数越小,模型在训练集上表现越优异;损失函数越大,说明模型在训练集上表现差劲,拟合不足,参数糟糕。损失函数分为许多种,而在逻辑回归中,采用的是对数似然损失函数。(推导过程比较复杂。。这里就不展开介绍啦)
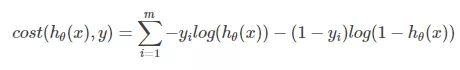
梯度下降法
逻辑回归的数学目的是求解能够让模型最优化,拟合程度最好的参数的值,即求解能够让损失函数最小化的值。对于二元逻辑回归来说,有多种方法可以用来求解参数,最常见就是梯度下降法(Gradient Descent)。
所谓梯度下降法的基本思想可以类比为一个下山的过程。假设这样一个场景:一个人被困在山上,需要从山上下来(找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低。因此,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走,同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
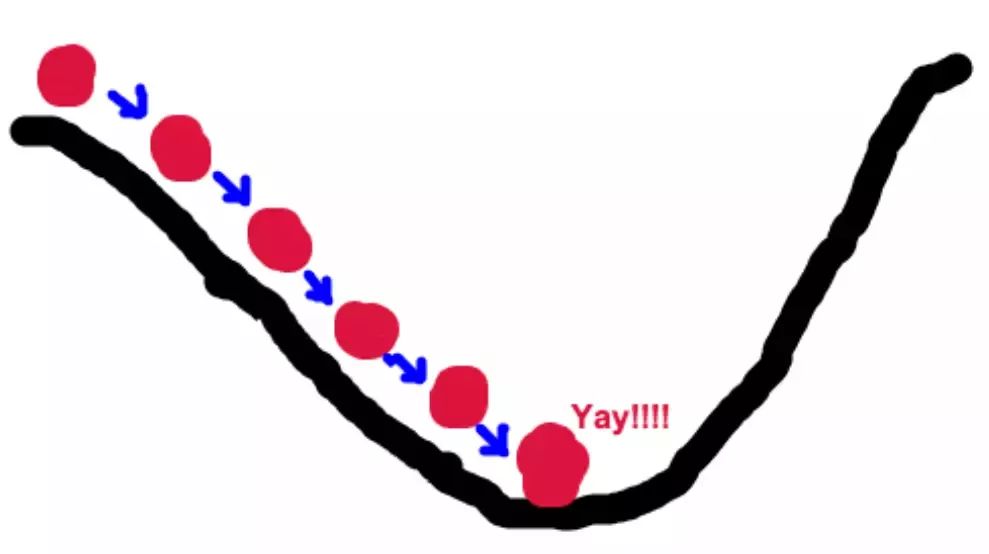
所以,此人每走一段距离,都需要一段时间来测量所在位置最陡峭的方向。那么为了在太阳下山之前到达山底,就要尽可能的减少测量方向的次数。这是一个两难的选择,如果测量的频繁,可以保证下山的方向是绝对正确的,但又非常耗时,如果测量的过少,又有偏离轨道的风险。
用向量来表示的话,梯度下降算法的迭代公式表示如下:(这里推导过程也不做介绍)
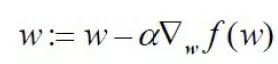
该公式将一直被迭代执行,直至达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可以允许的误差范围。
梯度下降法的类型
批量梯度下降法(Batch Gradient Descent,BGD):这种方法使用整个数据集(the complete dataset)去计算代价函数的梯度。每次使用全部数据计算梯度去更新参数,批量梯度下降法会很慢,并且很难处理不能载入内存的数据集。
随机梯度下降法(Stochastic Gradient Descent, SGD):随机梯度下降法的第一步是随机化整个数据集。在每次迭代仅选择一个训练样本去计算代价函数的梯度,然后更新参数。即使是大规模数据集,随机梯度下降法也会很快收敛。随机梯度下降法得到结果的准确性可能不会是最好的,但是计算结果的速度很快。
小批量梯度下降法(Mini-Batch Gradient Descent, MBGD):小批量梯度下降法是最广泛使用的一种算法,该算法每次使用m个训练样本(称之为一批)进行训练,能够更快得出准确的答案。小批量梯度下降法不是使用完整数据集,在每次迭代中仅使用m个训练样本去计算代价函数的梯度。
使用梯度下降求解逻辑回归
现在,假设我们有100个样本点,每个点包含两个数值型特征:X1 和 X2。在此数据集上,我们将使用批量梯度下降法(BGD)找到最佳回归系数,也就是拟合出逻辑回归模型的最佳参数。
梯度下降法的伪代码如下:
每个回归系数初始化为 1
重复下面的步骤直至收敛:
计算整个数据集的梯度
使用 alpha × gradient 更新回归系数的向量
返回回归系数
逻辑回归梯度下降优化算法:
import pandas as pd
import numpy as np
dataSet = pd.read_table('testSet.txt',header = None)
dataSet.columns =['X1','X2','labels']
def sigmoid(inX):
s = 1/(1+np.exp(-inX))
return s
def regularize(xMat):
inMat = xMat.copy()
inMeans = np.mean(inMat,axis = 0)
inVar = np.std(inMat,axis = 0)
inMat = (inMat - inMeans)/inVar
return inMat
def BGD_LR(dataSet,alpha=0.001,maxCycles=500):
xMat = np.mat(dataSet.iloc[:,:-1].values)
yMat = np.mat(dataSet.iloc[:,-1].values).T
xMat = regularize(xMat)
m,n = xMat.shape
weights = np.zeros((n,1))
for i in range(maxCycles):
grad = xMat.T*(xMat * weights-yMat)/m
weights = weights -alpha*grad
return weights
def logisticAcc(dataSet, method, alpha=0.01, maxCycles=500):
weights = method(dataSet,alpha=alpha,maxCycles=maxCycles)
p = sigmoid(xMat * weights).A.flatten()
for i, j in enumerate(p):
if j 0.5:
p[i] = 0
else:
p[i] = 1
train_error = (np.fabs(yMat.A.flatten() - p)).sum()
trainAcc = 1 - train_error / yMat.shape[0]
return trainAcc
示例:从疝气病症预测病马的死亡率
本节将使用逻辑回归来预测患有疝病的马的存活问题。这里的数据包含 368 个样本和 28 个特征。原始数据下载地址:http://archive.ics.uci.edu/ml/datasets/Horse+Colic
收集数据:给定数据文件。
准备数据:用 Python 解析文本文件并填充缺失值。
分析数据:可视化并观察数据。
训练算法:使用优化算法,找到最佳的系数。
测试算法:为了量化回归的效果,需要观察错误率。根据错误率决定是否回退到训练阶段,通过改变迭代的次数和步长等参数来得到更好的回归系数。
使用算法
准备数据:处理数据中的缺失值
数据中的缺失值一直是个非常棘手的问题,下面给出了一些常用的方法:
使用可用特征的均值来填补缺失值;
使用特殊值来填补缺失值,如-1;
忽略有缺失值的样本;
使用相似样本的均值添补缺失值;
使用另外的机器学习算法预测缺失值。
在这个例子中预处理做了两件事:
如果测试集中的一条数据已被确认,那么使用 0 来替换缺失值,因为这里使用的是逻辑回归,因此不会影响回归系数的值。
如果测试集中一条数据的类别标签已经确实则将该类别数据丢弃。
原始的数据集经过处理,保存为:horseColicTraining.txt 和 horseColicTest.txt。
测试算法:使用逻辑回归进行分类
前面已经介绍了优化算法,但目前为止还没有在分类上做任何实际尝试。使用逻辑回归方法进行分类并不需要做很多工作,所需做的只是把测试集上每个特征向量乘以最优化方法得来的回归系数,再将该乘积结果求和,最后输入到 Sigmoid 函数中即可。如果对应的 Sigmoid 值大于0.5就预测类别标签为 1,否则为 0。
导入数据:
train = pd.read_table('horseColicTraining.txt',header=None)
test = pd.read_table('horseColicTest.txt',header=None)
封装函数:
def classify(inX,weights):
p = sigmoid(sum(inX * weights))
if p 0.5:
return 0
else:
return 1
def get_acc(train,test,alpha=0.001, maxCycles=500):
weights = BGD_LR(train,alpha=alpha,maxCycles=maxCycles)
xMat = np.mat(test.iloc[:, :-1].values)
xMat = regularize(xMat)
result = []
for inX in xMat:
label = classify(inX,weights)
result.append(label)
retest=test.copy()
retest['predict']=result
acc = (retest.iloc[:,-1
]==retest.iloc[:,-2]).mean()
print(f'模型准确率为:{acc}')
return retest
测试结果:
get_acc(train,test,alpha=0.001, maxCycles=500)
Reference
猜你喜欢
机器学习实战 | 朴素贝叶斯
机器学习实战 | 决策树
机器学习实战 | k-邻近算法
一起来学习机器学习吧~
生信基础知识100讲
生信菜鸟团-专题学习目录(5)
还有更多文章,请移步公众号阅读
▼ 如果你生信基本技能已经入门,需要提高自己,请关注下面的生信技能树,看我们是如何完善生信技能,成为一个生信全栈工程师。

▼ 如果你是初学者,请关注下面的生信菜鸟团,了解生信基础名词,概念,扎实的打好基础,争取早日入门。












