

以下文章综合于网络多家媒体公号
如涉版权请加编辑微信iwish89联系
哲学园一并鸣谢
科研圈报道:今天(2019年03月27日),计算机领域最高奖项“图灵奖”迎来了新一届得主:
Yoshua Bengio
加拿大蒙特利尔大学教授约书亚·本希奥
Geoffrey Hinton
谷歌副总裁兼多伦多大学名誉教授杰弗里·欣顿
Yann LeCun
以及纽约大学教授兼 Facebook 首席 AI 科学家杨立昆
这三位被业内人士称为“当代人工智能教父”的科学家是深度神经网络(deep neural network)的开创者,这项技术已经成为计算科学的关键部分,为深度学习(deep learning)算法的发展和应用奠定了基础——这正是现在计算机视觉(Computer Vison)、语音识别(Speech Recognizing)、自然语言处理(Natural Language Processing)和机器人研发等领域展现出惊人活力、掀起科技创业热潮的重要原因。
下面介绍一下神一样存在的
Yoshua Bengio
这是他写的AI圣经

深度学习 AI 圣经
Yoshua Bengio 著
长按二维码购买

专访|深度学习三巨头之一的本吉奥:“人工智能”正在被滥用
来源:澎湃新闻
面对这几年的AI热潮,他这样看待:科学在大部分时候都是小步前进的,我们必须要谦逊。他对澎湃新闻记者表示,人工智能一词正在被滥用,有些公司拟人化了AI系统,仿佛AI系统是与人类相当的智慧实体,但其实目前还没有出现与人类智慧相当的实体,“只是软件做有用的事情,并不比烤面包机有更多的自我意识。”他还担心机器学习被想要一夜暴富的公司所利用,他对澎湃新闻坦言,人类是如此贪婪,金钱有更大的话语声。
他就是Yoshua Bengio(约书亚·本吉奥),人工智能领域无人不知的深度学习大师,加拿大AI“黑手党”之一,与Geoffrey Hinton和Yann LeCun并称为“深度学习三巨头”。在30余年的深度学习研究生涯里,他发表了300多篇学术论文,累计被引用次数超13.8万次。Yoshua Bengio素来低调,除了演讲,他似乎很少在媒体和公众视野中出现。澎湃新闻记者近日以邮件的形式采访了他。这位人工智能学者与澎湃新闻谈了谈他对人工智能的理解。
Yoshua Bengio出生于巴黎,成长于加拿大,现居加拿大蒙特利尔,在蒙特利尔大学(University of Montreal)计算机科学与运算系任教授。他于1991年获得加拿大麦吉尔大学(McGill University)的计算机科学博士学位。业内戏称他与同样活跃于加拿大的“神经网络之父”Geoffrey Hinton和“卷积网络之父”Yann LeCun为“加拿大黑手党”(Canadian Mafia)。Bengio的主要研究领域是深度学习(Deep Learning)和自然语言处理(Natural Language Processing)。吴恩达曾表示Yoshua Bengio的许多理论研究对他有很大启发。

Yoshua Bengio接受媒体采访
Yoshua Bengio顶一头黑白相间的短发,一对漫画式的粗眉会在思考时上扬,笑起来极具表现力。现年54岁的他是深度学习“三巨头”中最年轻的一位。
20世纪80年代,大学时期的Bengio对深度学习产生兴趣并正式进入人工智能研究领域。那时,深度学习还是一个非常冷门的领域。经历过大多数人的热情消失殆尽的AI寒冬,他没有离开;遇上了近年来的又一次AI热潮,他开始批评天花乱坠的许诺。
从1997年深蓝击败卡斯帕罗夫到2011年沃森赢得《危险边缘》,这中间经历了漫长的人工智能寒冬,Bengio曾感慨,很长一段时间里,几乎从来没有人深入挖掘它。但Bengio似乎沉浸其中,他建立了蒙特利尔学习算法研究所(Montreal Institute For Learning Algorithms, MILA)并担任科学主任,还构建起蒙特利尔的人工智能生态系统。他是加拿大统计学习算法研究主席,也在2009年担任了机器学习顶级会议NIPS的主席(General Chair)。

他认为,简单来说,人工智能是指计算机在新环境中做出好的决策,并根据它们所掌握的信息进行相应调整的能力。人工智能渴望达到人类的认知能力,这也通常是一些算法的灵感来源。
尽管认为“人工智能”一词正在被滥用,Bengio个人还是很喜欢“人工智能”这个术语,他告诉澎湃新闻,“人工智能”很好地描述了人们想要达到的目标。对他而言,人工智能并不是一个非黑即白的事情,他一方面在个人主页呼吁禁止人工智能的武器化,另一方面又认为人工智能需要在世界范围内民主化。他不希望地球上所有的力量都集中在几个国家。在他看来,人们应该帮助发展中国家发展他们的专业知识和技能,培训他们的学生;同时随着技术的改进,在例如医疗保健、人道主义、环境和教育领域中利用人工智能技术。
许多人工智能领域的学者纷纷加入了工业界,Geoffrey Hinton去了谷歌,Yann Lecun则是Facebook首席人工智能科学家。Bengio也曾给几家公司担任过学术顾问,还联合创立了一家位于蒙特利尔的企业孵化器Element AI,但他仍把大多数的时间放在学术上。Bengio不否认AI公司的价值,但告诉澎湃新闻记者,他想保留绝大多数精力来发展他创建的机构和蒙特利尔的人工智能生态系统,还想通过他的研究和对学生的辅导更直接地为公共利益做出贡献。他说:“当你在工业界做研究员时,你就不可能带那么多的学生”,“我觉得,通过留在学术界,在这条我自己选择的道路上,我的科学影响力和做正确之事的道德感得到了最大化。”他希望每个人都能以一种对这颗星球最好的方式做出自己的决定,但他不会评价其他人在这方面的选择。

在人工智能的伦理问题上,他呼吁政府制定规则以确保公司或政府部门做出正确而非经济或政治上有利可图的选择,也希望公众和媒体更多地了解这个话题,以确保政府行为得当。
2016年,Yoshua Bengio与Ian Goodfellow和Aaron Courville合著了《Deep Learning》(深度学习),该著作长期位居美国亚马逊人工智能和机器学习类图书榜首,被称为人工智能领域的必读书目,还因封面图案被亲切地称为“花书”。他还写了另一本人工智能经典之作《Learning Deep Architectures for AI》。
深度学习 AI 圣经
Yoshua Bengio 著
长按二维码购买
他透露了自己目前的研究兴趣:超越当前深度学习的局限,以最终构建真正理解其所处环境且能根据语言环境理解语义的系统。
澎湃新闻请他给刚入门的学生提些意见,他说,大量阅读,通过从零开始编写基本算法来弄脏你的双手,学习使用通用平台,以及尝试再现这个领域许多科学论文中的结果。
至于对AI教育的建议,他称自己合著了一本书来回答这个问题。这本书就是“花书”——《Deep Learning》。
2018年11月7日,Bengio将前往北京参加微软亚洲研究院举办的“二十一世纪的计算”学术研讨会。
澎湃新闻与Yoshua Bengio的交流实录:
目前的AI系统“不比烤面包机有更多的自我意识”
澎湃新闻:简单来说,你认为什么是人工智能?
Yoshua Bengio:计算机在新环境中做出好的决策,并根据它们所掌握的信息进行相应调整的能力。人工智能渴望达到人类的认知能力,这通常是一些算法的灵感来源。
澎湃新闻:你认为“人工智能”这个概念被过度使用了吗?
Yoshua Bengio:是的,被那些把自己搭建的AI系统拟人化的公司(过度使用了),仿佛AI系统是与人类相当的智慧实体,但其实它们并不是。目前还没有出现与人类智慧相当的实体。只是软件做有用的事情,并不比烤面包机有更多的自我意识。
但我喜欢“人工智能”这个术语,因为它很好地描述了我们想要达到的目标。这并不是非黑即白的事情:无论是在自然界还是在人工系统中,都存在着很多不同程度的智能,智能主体可能对某些事情很聪明,而在许多其他事情上很愚蠢。
澎湃新闻:我注意到你在个人主页呼吁禁止人工智能的武器化,你对人工智能的伦理问题持什么态度?
Yoshua Bengio:我认为人工智能伦理是一个重要的议题,人工智能领域的行动者需要有更强的意识并且在这方面受到更好的教育。学生和研究人员需要了解这些问题,这样一来,如果他们在未来遇到必须做出选择的情况,比如选择做什么项目,或者为哪家公司工作,他们就会考虑到伦理问题,并做出负责任的选择。
当然,在AI领域布局的公司也需要了解伦理问题,但在某些情况下,我们也需要政府制定规则以确保公司或政府部门能够做出正确的,而不是经济或政治上有利可图的事情。
公众和媒体也需要知道这些伦理问题,以确保政府行为得当。
与人脑相比,深度学习系统不是黑盒
澎湃新闻:《自然-机器智能》的主编对我们说,她认为深度学习方法目前仍然是一个黑盒,可能因此引起伦理问题。你同意这个观点吗?
Yoshua Bengio:我不认为黑盒子是一个很大的问题,但做更多研究来改进这个方法是值得的,我们已经有了一些,这能使我们更容易地解释这个复杂系统做出的决策。
实际上,这些系统并不是黑盒子:与你的大脑不同,这些系统中每个细节的计算过程都可以被测量;而对于大脑的决定,我们并不能做出解释,因为我们不能接触到直觉和潜意识中发生的一切。
真正的问题首先是透明度,我们需要确保当所做的决定切身相关时,普通公民以及为他们工作的人可以访问这些白盒子。
第二是复杂性,因为这些计算很复杂,想提取一个简单的故事来总结做出某个具体决定的原因十分困难;但是,我们已经可以确定例如哪些变量是最重要的,重要程度如何,方向上是正相关还是负相关。
澎湃新闻:机器学习研究需要大数据集。但目前,似乎没有足够的数据用于研究?
Yoshua Bengio:并不是这样。有大量的数据可用于一般性研究。对于某些特殊的任务,我们希望有更多人为标记的数据。因为这是目前来说最好的方式,这些AI系统并不能靠自己就变得聪明,它们需要人类反馈和先验知识的填鸭式灌输。在像医学这样的应用中,数据有很多,但由于社会和经济原因(还有贫穷的原因),研究人员无法获得这些数据。总的来说,缺乏数据主要影响那些想解决特定任务的公司。对于基础研究来说,这并不是一个问题。
澎湃新闻:但数据质量和数据披露的监管问题似乎不太令人满意。这种情况是人工智能或机器学习研究的瓶颈吗?
Yoshua Bengio:对于基础研究来说不是问题,但是对于构建系统来说是一个问题。这通常是公司的关切,但同时也是学术界的应用研究所关心的事情。
为何留在学术界?Bengio:人类贪婪,金钱至上
澎湃新闻:美国有许多人工智能学者来自学术界,而且与工业界保持密切的联系,也有许多学者创办自己的企业。你认为这种模式对人工智能研究有什么影响?在中国,一些研究者认为这不利于科学研究的进展。你个人如何看待?
Yoshua Bengio:不幸的是,人类是如此贪婪。金钱的话语声更大。而且创办一家公司会在最初给人一种掌控感,(但投资人往往会在一段时间后成为主宰者)。
开办一家公司对于开发新的和有用的产品来说非常重要。有时候这是完成一个实际目标、解决一个特定问题的最佳方法,因为你可以快速地获得大量资金来进行这项工作。只要利润能够被公平地分配,AI公司确实能为所在的城市和国家带来繁荣,这也是好的,但许多国家的情况并非如此。
就我个人而言,我想帮助创业者做这些好事,但想保留我的绝大多数精力来发展我创建的机构和蒙特利尔的人工智能生态系统,还想通过我的研究和我对学生的辅导更直接地为公共利益做出贡献。
当你在工业界做研究员时,你就不可能带那么多的学生,所以我觉得,通过留在学术界,在这条我自己选择的道路上,我的科学影响力和做正确之事的道德感得到了最大化。
我们每个人都需要决定什么是对自己最好的,(希望是以一种对这颗星球也最好的方式)。我不会评价其他人在这方面的选择。
“让人工智能在世界范围内民主化”
澎湃新闻:你目前的研究兴趣是什么?
Yoshua Bengio:超越当前深度学习的局限,以最终构建真正理解其所处环境且能根据语言环境理解语义的系统。
澎湃新闻:你对AI教育有什么建议?你认为AI教学中最重要的因素是什么?
Yoshua Bengio:我合著了一本书来回答这个问题:《深度学习》(Deep Learning),麻省理工学院出版社。
澎湃新闻:那你对刚进入人工智能或者机器学习领域的学生有什么建议?
Yoshua Bengio:大量阅读,通过从零开始编写基本算法来弄脏你的双手,学习使用通用平台,以及尝试再现这个领域许多科学论文中的结果。
澎湃新闻:历史上人工智能的发展经历过高潮和寒冬。在你看来,为什么AI遇到了又一个热潮?这种热潮是可持续的吗?
Yoshua Bengio:这次热潮很大程度上是由工业界的巨大需求驱动的。大多数大技术公司都在使用人工智能。随着技术在社会许多领域中的扩展,这种需求只会继续增长。
澎湃新闻:目前,美国、英国、欧盟、日本等许多国家都在大力开展人工智能研究,您如何评价他们在这方面的工作?
Yoshua Bengio:没有评价,只想说让人工智能在世界范围内民主化很重要。我们不希望地球上所有的力量都集中在几个国家,包括帮助发展中国家发展他们的专业知识和技能,培训他们的学生。同时随着技术的改进,在例如医疗保健、人道主义、环境和教育领域中利用这些技术。

深度学习 AI 圣经
Yoshua Bengio 著
长按二维码购买
作者:邱陆陆 来源:机器之心
「对表征(representation)空间的依赖贯穿计算机科学乃至日常生活的始终。在计算机科学中,如果数据有精当的结构,辅以智能化的索引,那么搜索任务的速度可以指数级加快;对于人来说,计算『 210 除以 6 等于几?』是容易的,计算『 CCX 除以 VI 等于几?』则需要更多时间。表征空间的选择对机器学习算法的性能影响,由此可见一斑。」《深度学习》[1] 一书如是评价表征的重要性。
对于作者之一 Yoshua Bengio 来说,「表征学习」甚至比「深度学习」更适合描述其研究重心。
好的表征意味着学习任务变得更加容易,意味着计算机可以拥有「知识」,进而可以进行人与动物所擅长的决策。而如何定义好的表征?如何学习好的表征?那些试图理解人类自身的研究(例如脑科学与自然语言学科的研究),又给表征学习带来了哪些启发?这些都是 Bengio 试图回答的问题,而深度学习,一方面是表征学习的手段,另一方面,是可以利用好的表征实现人类水平 AI 的「获益者」。
2007 年,Bengio 与 Yann LeCun 合著的论文 [2] 着重强调表征必须是多层的、逐渐抽象的。13 年,Bengio 在综述论文中 [3],增加了对解纠缠(Disentangling)的强调。
17 年,Bengio 在 ArXiv 发布了一篇题名为《意识先验》(The Consciousness Prior)的 、仅有四页纸长的文章 [4]。这四页纸,与其说是论文,不如说是他回首过去十年在表征学习一途的研究之路,无论大路小路、歧路远路,然后为未来十年画下的一张蓝图。
近日,长居于蒙特利尔的 Bengio 来到了北京,除了发表了两场公开演讲之外,也接受了机器之心的专访。以「意识先验」这张可以串联起前后数百篇论文的蓝图为线索,Bengio 向我们解释他如今思考表征学习的理论框架、在此框架下完成的一系列工作、以及为什么这个框架能够引导深度学习走向人类水平的 AI。
从「意识先验」理论说起
「深度学习的主要目标之一就是设计出能够习得更好表征的算法。好的表征理应是高度抽象的、高维且稀疏的,但同时,也能和自然语言以及符号主义 AI 中的『高层次要素』联系在一起。现在,我们还无法用无监督学习的方法找到这样的表征。
一个有关世界的描述其实只需要很少几个高层次要素,就像你可以用寥寥几个单词组成一句话一样。一句话,或者符号主义 AI 系统的一条规则之中,通常只涉及几个概念,而相比之下,当前的机器学习算法则需要学习大量变量的联合分布(比如一张图片中的所有像素的联合分布),维度极高。
意识先验试图用上述的动机迫使表征学习到一些好的特性:比如能够轻松提取特征的少数几个维度、能够利用少数几个维度作出动作或者对未来的预测等等。换言之,意识先验通过额外的压力与限制条件,来找到那些善于表达符号化的知识的表征。」Bengio 这样解释意识先验的工作。
如果你对先验(prior)这个词感到陌生,不妨将它替换为约束(constraint)或者正则化项(regularization term)。
学习本质是一个在所有可能性里进行挑选的过程,而先验告诉你挑选的偏好以及理由。文章开头的例子中,把数字表示成阿拉伯数字而非罗马数字的理由「方便计算」就是一种先验。而「意识先验」则是 Bengio 提出的一种新先验。
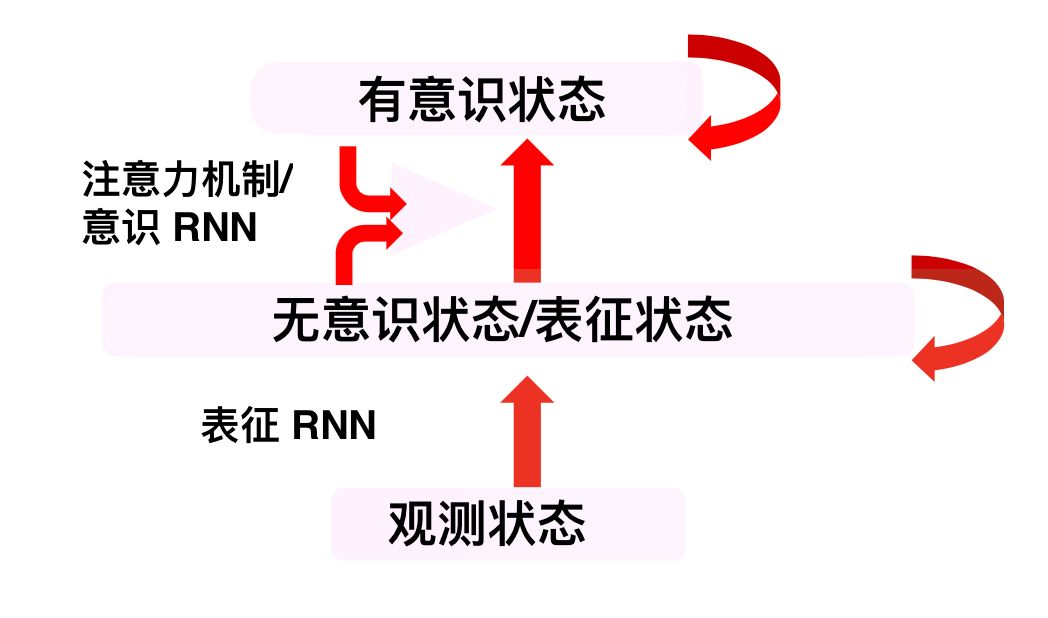
图:意识先验的网络示意图,来自 Bengio 演讲 Challenges for Deep Learning towards Human-Level AI,机器之心汉化
意识先验理论来自对人的观察。意识是某一时刻人脑中的想法,它的维度很低——不管我们的大脑里储存了多少知识,在某一时刻里,脑海中只能容纳少数几个要素构成一个想法。
Bengio 将这个类比想法的低维向量称为有意识状态(conscious stat),将大脑中的所有内容——一个非常高维、非常稀疏的向量,称为无意识状态(unconscious state, representation state),而来自外界的信息输入则称为观测状态(observed state)。
感知状态通过一个表征 RNN 得到无意识状态,无意识状态通过一个注意力机制,或称意识 RNN 得到有意识状态。获得好的表征 RNN,从而得到好的表征,是表征学习的目的。
意识先验对于「好」的定义是:「能够容易地从无意识状态中提取出少数几个要素,它们包含了足够多的知识,能够作出与真实世界有关的陈述、动作预测。」
这就是意识先验的理论框架。
理论骨骼的「血与肉」:目标函数与优化方法
框架搭好之后,问题就变成了:如何将这样的先验表达出来?
训练目标问题首当其冲。
标准的深度学习算法的目标函数通常基于最大似然,但是我们很难指望最大似然的信号能够一路经由反向传播穿过用于预测的网络,穿过意识 RNN,最终到达表征 RNN。不要说表征 RNN 了,当你尝试从大量信息中挑出非常少几个维度时,意识 RNN 会倾向于将注意力集中在那些高度可预测但是毫无意义的要素上。
更重要的是,最大似然与意识先验的思想天然存在冲突。「人类从不在像素空间进行想象与生成任务,人类只在高度抽象的语义空间使用想象力,生成一张像素级的图像并非人类需要完成的任务。」因此,在训练目标里引入基于表征空间的项目就变得顺理成章。
过去的机器学习中,是否有类似的不在原始数据空间内定义目标函数的案例?
有,Bengio 以 PCA 举例:「PCA 的训练可以发生在不同的空间:你可以在像素空间训练 PCA,用重构误差做目标函数,也可以在其表征空间构建目标:要求表征高方差、要求表征保留尽可能多的输入信息 、要求表征彼此独立……这些都是在表征空间定义的无监督训练目标。」
那么对于意识先验来说,有什么合适的无监督目标吗?
《意识先验》发布后不久,Bengio 就和他当时的博士后学生、现 DeepMind 研究员 Philemon Brakel 共同发表了论文 [5],讨论将互信息(mutual information)作为意识先验目标函数重要组成部分的可能性。
「『不在像素空间定义目标函数』的思想可以回溯到上世纪 90 年代初联结主义和神经网络刚刚兴起的时候,Hinton 的博士生 Suzanna Becker 在其毕业论文 [6] 里讨论了空间中的互信息:她认为,我们应该将『找到一种图像变换,让空间中相邻的特征具有高互信息』作为图像任务的无监督学习目标。」
「我认为这是一个没有得到足够重视的方向。」Bengio 说。他认为可以将这一思路从空间扩展到时间序列,寻找在不同时间步里拥有高互信息的特征。「一个合理的假设是,在好的表征空间里,当前的表征中会拥有很多关于未来的信息,从而获得跨时间的可预测性。」
这个概念还可以被扩展到增强学习里,在这里,「众望所归」的高互信息对象是「意图/策略/动作」与表征。Bengio 指了指手中的笔,「比如,我想要在移动这支笔(意图),那么在表征空间里有专门的维度负责描述这支笔的位置会让未来对笔的表征格外顺利。事实上我很希望我的大脑里有一个专门的神经元负责这件事。」
如果你对这个话题非常感兴趣,那么你可以顺着心理学中的「功能可见性」(affordance,看到一样物体就能知道如何与它交互)一词继续探索。
除了目标函数之外,意识先验的优化方式也会和经典深度学习有所不同。
即使是注意力机制,也需要「软化」这样的手段以便反向传播,更不用提意识先验的超高维表征和超长时间跨度了。人们在大量使用强化学习方法处理不能反向传播的情况,然而,这还远远不足。
「什么样的优化方式最适合意识先验?我仍然不知道这个问题的答案。」Bengio 说。在他看来,一类很有前景的研究是合成梯度(synthetic gradient)[7]。
「合成梯度是说,即使我们在不知道全部知识的情况下进行了无法反向传播的离散决策,我们仍然可以训练神经网络的一个部分,就像 GAN 中的判别器一样,它拥有一个损失函数,我们能够通过它获得近似梯度。」
有了合成梯度之后,每一层的梯度可以单独更新了。但是当时间步继续拉长,问题仍然存在。理论上反向传播可以处理相当长的序列,但是鉴于人类处理时间的方式并非反向传播,可以轻松跨越任意时长,等「理论上」遇到一千乃至一万步的情况,实际上就不奏效了。
换言之,我们对时间的信用分配(credit assignment)问题的理解仍然有待提高。
「比如你在开车的时候听到『卟』的一声,但是你没在意。三个小时之后你停下车,看到有一个轮胎漏气了,立刻,你的脑海里就会把瘪轮胎和三小时前的『卟』声联系起来——不需要逐个时间步回忆,直接跳到过去的某个时间,当场进行信用分配。」
受人脑的信用分配方式启发,Bengio 的团队尝试了一种稀疏注意回溯(Sparse Attentive Backtracking)方法。「我们有一篇关于时间信用分配的工作,是 NIPS 2018 的论文 [8],能够跳过成千上万个时间步,利用对记忆的访问直接回到过去——就像人脑在获得一个提醒时所作的那样——直接对一件事进行信用分配。」
意识先验理论只是一个思维框架、一个研究计划,它撑起了一个研究方向的骨骼,衍生出一堆亟待探索的问题。目标函数的构建、优化方法的选择,最后,还有模型结构的设计,这些则是研究方向的血肉。这些问题中,有的问题存在几个前景可观的方向,还有一些仍然处于设想阶段。
从实验场出发:发现优秀的算法,而不是搭一个 AI
想要对意识先验理论进行实验存在一个问题:无论想要找到合适的目标函数、还是优化方法,都要和表征 RNN 以及无意识状态打交道。虽然有意识状态的大小只是和一句话、一条规则差不多,但与无意识状态的规模对应的,是大脑存储的全部内容。
「学习整个世界是非常困难的。刻画现实世界的复杂性是我们的最终目的,最终我们会实现这一点的,但是作为第一步,我们应该减小问题的范围,在一个有限的环境内学习『学习』本身。要记住,机器学习研究的目的不是搭一个 AI,而是发现优秀的学习算法。学习算法是通用的,所以我们可以在一个有限的环境里测试自己的算法,如果它在有限环境中都无法学到东西,那么无疑它无法走入真实世界。」
因此,我们搭建一个如同视频游戏一样的虚拟环境。一个如同果蝇之于生物学、MNIST 之于传统机器学习框架的环境。
1971 年,Winograd 在试图用符号主义方法建立一个能够用自然语言执行任务的系统时,也建立了一个环境:一个叫 SHRDLU 的砖块世界,计算机可以在其中和人的指令进行简单的互动。
虽然 Winograd 的方法并没有成功,但合成环境的思想流传了下来:与其被动地观察巨量的要素相互作用产生的结果,不如与少一些的要素直接进行交互。
基于这一思想,Mila 实验室的一个团队创建了 BabyAI 平台 [9],构建了一个 2D 网格世界,有一些房间,有渐进的难度系数,有一位虚拟的「老师」,希望像老师教婴儿学习一样,教会还是个「宝宝」的 AI,至于教学的任务,则以自然语言的形式出现:希望 AI 同时学会关于这个世界的知识,以及语言与这个世界中的要素的关系。
那么,为什么是语言?
连接自然语言,连接符号主义
其实这个问题应该换一个问法:为什么是表征+语言?
Bengio 仍然从脑科学入手解释这个问题。
人类的认知任务可以分为系统 1 认知(System 1 cognition)和系统 2 认知(System 2 cognition)。系统 1 认知任务是那些你可以在不到 1 秒时间内无意识完成的任务。例如你可以很快认出手上拿着的物体是一个瓶子,但是无法向其他人解释如何完成这项任务。这也是当前深度学习擅长的事情,「感知」。
系统 2 认知任务与系统 1 任务的方式完全相反,它们很「慢」且有意识。例如计算「23+56」,大多数人需要有意识地遵循一定的规则、按照步骤完成计算。完成的方法可以用语言解释,而另一个人可以理解并重现。这是算法,是计算机科学的本意,符号主义 AI 的目标,也属于此类。
人类联合完成系统 1 与系统 2 任务,人工智能也理应这样。
「这种联合并非将符号化知识与联结主义知识合并,而是将符号主义 AI 的目标视为联结主义优化的最终目标,同时让联结主义表征习得的关于世界的知识作为符号主义任务的基础。」
就像把一支只会砌砖的施工队,和一位只会画图的建筑师组合在一起:原本只会砌平房的施工队按照图纸能盖摩天楼了,而原本只能设想空中楼阁的建筑师也接了地气。
回到表征和语言的例子里。
「下雨了,人们撑起了伞。」是单独存在的语言,寥寥数字里有两个明确的
要素:「是否下雨」和「是否撑伞」,你可以很容易地把它们从句子里摘出来,然后用它们建立规则进行推理。但是这种推理是与真实世界隔离的。

上面这幅照片则是单独存在的表征,虽然用一团像素表达了和语言同样的意思,可是我们无法把代表「下雨」和「撑伞」的像素挑出来,更无法推理说一些像素是另一些像素的原因。我们能做的只是以标签的形式告诉机器,这张图里有一个很重要的概念,叫做「下雨」,而这样形式习得的表征也无法完成推理任务。
「意识先验是将联结主义与符号主义结合的粘合剂。符号主义 AI 向联结主义表征 RNN 表达诉求:我想要完成『下雨的时候人们会打伞。』这样的推理,请给我合适的变量,而表征 RNN 需要自己发现,『下雨』是一个能够从图像中提取出的、帮助推理的特征,然后学习它。」
这才是意识先验最终的目的,这张显著不同于现有深度学习框架的蓝图所规划的方向。
「五年前我们关心的问题是,如何设计不依赖蒙特卡洛链的生成模型,所以我们有了变分自编码器(VAE),有了生成对抗网络(GAN),自那以后我们在生成方面获得了巨大的进步,但是生成并不是最终目的。」
五年前人们仍然认为通过学习文本本身能够解决自然语言处理问题,现在谷歌的 BERT 大规模预训练语言模型已经在 33 亿规模的词库上进行训练了。「BERT 还是会和其他现有模型一样,犯一些人类根本不会犯的『愚蠢』错误。BERT 在推动单纯基于文本的自然语言处理模型的极限,这是件很好的事,但是它能够获得的终究是不完整的语言模型,」
在 Bengio 眼中,生成模型和 BERT 都没有触及本质问题:「大概十年前,我提出了一个非常基本的问题:『如何将潜在的变差因素解纠缠?』(the disentangling the underlying factors of variation)十年过去了,这仍然是一个未解之谜。」
那些「基本的问题」好像是 AI 之路通关前的最后一道门,解开了问题仿佛就能获得开门的钥匙,门后面就是如 Yoshua Bengio 一样走在最前列的研究者们从数十年前就梦寐以求的「通用的、人类水平的人工智能」。他们尝试了各种技巧,每一条路都让我们离这扇门更近,但似乎又没有一条能够真正通向这扇门。
「如果说十年前的我和现在的我在观点上有什么不同的话,那就是五年或者十年前,我仍然天真地希望我们所掌握的技巧能奇迹般地通过尝试学会做正确的事。」
Bengio 花了十年时间,相信这个奇迹不会发生。
「现在我不这么认为了。我们要引导机器去做正确的事,通过那些能够推动机器朝正确的方向前行的先验。」
References:
[1] Goodfellow, I., Bengio, Y., Courville, A., & Bengio, Y. (2016). Deep learning (Vol. 1). Cambridge: MIT press.
[2] Bengio, Y., & LeCun, Y. (2007). Scaling learning algorithms towards AI. Large-scale kernel machines, 34(5), 1-41.
[3] Bengio, Y. (2013, July). Deep learning of representations: Looking forward. In International Conference on Statistical Language and Speech Processing (pp. 1-37). Springer, Berlin, Heidelberg.
[4] Bengio, Y. (2017). The consciousness prior. arXiv preprint arXiv:1709.08568.
[5] Brakel, P., & Bengio, Y. (2017). Learning Independent Features with Adversarial Nets for Non-linear ICA. arXiv preprint arXiv:1710.05050.
[6] Becker, S., & Hinton, G. E. (1992). Learning to make coherent predictions in domains with discontinuities. In Advances in Neural Information Processing Systems (pp. 372-379).
[7] Jaderberg, M., Czarnecki, W. M., Osindero, S., Vinyals, O., Graves, A., Silver, D., & Kavukcuoglu, K. (2016). Decoupled neural interfaces using synthetic gradients. arXiv preprint arXiv:1608.05343.
[8] Ke, N. R., Goyal, A., Bilaniuk, O., Binas, J., Mozer, M. C., Pal, C., & Bengio, Y. (2018). Sparse Attentive Backtracking: Temporal CreditAssignment Through Reminding. arXiv preprint arXiv:1809.03702.
[9] Chevalier-Boisvert, M., Bahdanau, D., Lahlou, S., Willems, L., Saharia, C., Nguyen, T. H., & Bengio, Y. (2018). BabyAI: First Steps Towards Grounded Language Learning With a Human In the Loop. arXiv preprint arXiv:1810.08272.
深度学习 AI 圣经
Yoshua Bengio 著
长按二维码购买
2018年11月7日晚,被称为“深度学习三巨头”之一的蒙特利尔大学计算机科学与运算研究系教授Yoshua Bengio在清华大学做了《深度学习抵达人类水平人工智能所面临的挑战(Challenges for Deep Learning towards Human-Level AI》的学术报告。Yoshua Bengio教授客观的说,目前人工智能距离人类水平还仍然十分遥远,人工智能在工业应用的成功主要得益于监督学习方法,人工智能仍然面临巨大挑战,尤其在人类智能机理方面的研究还亟需加强。在报告中,Yoshua Bengio深度探讨了深度学习模型的具体内容,如何实现对抽象特征的多层次学习,如何更好地进行表示学习,使用判别器优化信息间的独立性、相关性和熵,Baby AI框架等话题。

Yoshua Bengio教授是蒙特利尔大学计算机系教授和加拿大科学院院士,被称为神经网络三巨头之一。著有《Deep Learning》、《Learning Deep Architectures for AI》、《A neural probabilistic language model》等多部畅销书/课本。

在他的倡导下,加拿大成立了Mila研究院,专注研究人工智能和深度学习。也正是因为在深度学习方面的重要贡献,Yoshua Bengio教授获得了加拿大总督功勋奖,该奖项主要为了纪念做出了卓越成就或者对国家做出了重大贡献的各领域人士,是加拿大公民的最高荣誉之一。

演讲报告

人工智能的目标是让计算机能够进行人与动物所擅长的「决策」,为此,计算机需要掌握知识——这是几乎全体 AI 研究者都同意的观点。他们持有不同意见的部分是,我们应当如何把知识传授给计算机。经典 AI(符号主义)试图将我们能够用语言表达的那部分知识放入计算机中。但是除此之外,我们还有大量直观的(intuitive)、 无法用语言描述的、不能通过「意识」获得的知识,它们很难应用于计算机中,而这就是机器学习的用武之地——我们可以训练机器去获取那些我们无法以编程形式给予它们的知识。

深度学习和 AI 领域有很大进步、大量行业应用。但是它们使用的都是监督学习,然而这些模型非常脆弱,极易受到外界干扰。
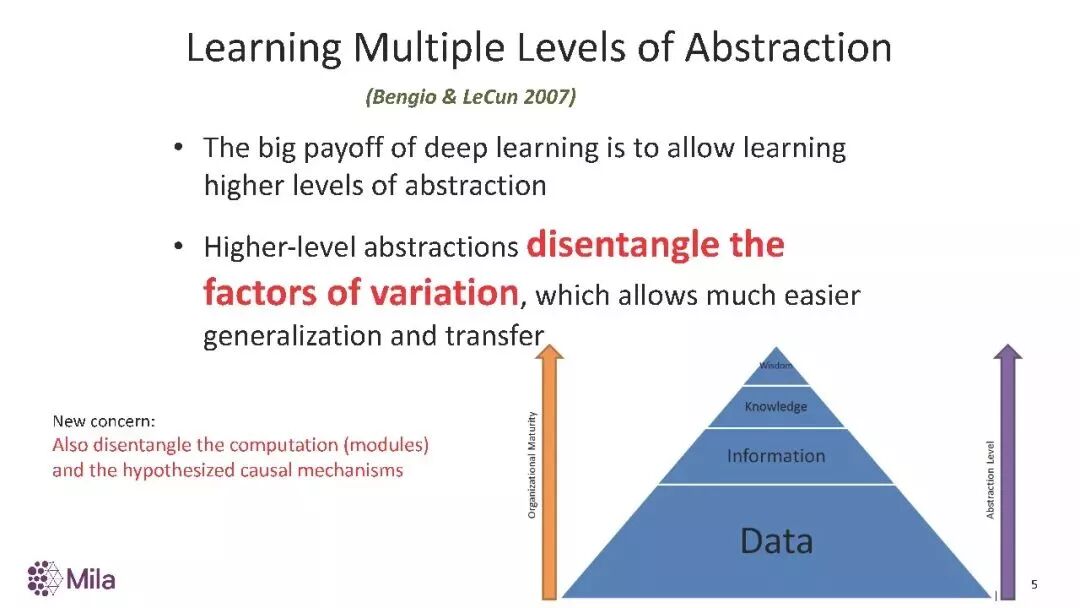
现在的系统的失败之处在于,它们无法捕捉我们真正想让机器捕捉到的高级抽象(high level abstraction)。而这样的表征可以捕捉构成数据的根本因素。

如何发现好的纠缠表征?一个好的表征空间中,不同要素的变化应该可以彼此分离。除了解纠缠变量,我们还希望系统能解纠缠计算。解纠缠和因果的概念相关,而因果正是机器学习界需要重点关注的领域。

人类的认知任务可以分为系统 1 认知和系统 2 认知。系统 1 认知任务是那些你可以在不到 1 秒时间内无意识完成的任务。例如你可以很快认出手上拿着的物体是一个瓶子,但是无法向其他人解释如何完成这项任务。这也是当前深度学习擅长的事情,「感知」。系统 2 认知任务与系统 1 任务的方式完全相反,它们很「慢」。大多数人需要遵循一定的规则、按照步骤完成计算。这是有意识的行为,你可以向别人解释你的做法,而那个人可以重现你的做法——这就是算法。计算机科学正是关于这项任务的学科。而我对此的观点是,AI 系统需要同时完成这两类任务。

意识空间里的事物维度很低,因而可以在这样的空间里进行推理。意识先验就是假设有很多只包含很少变量但为真的事情,因此,好的表示的一个性质,就是当我们把数据映射到表示空间之后,变量之间只有少数相关。
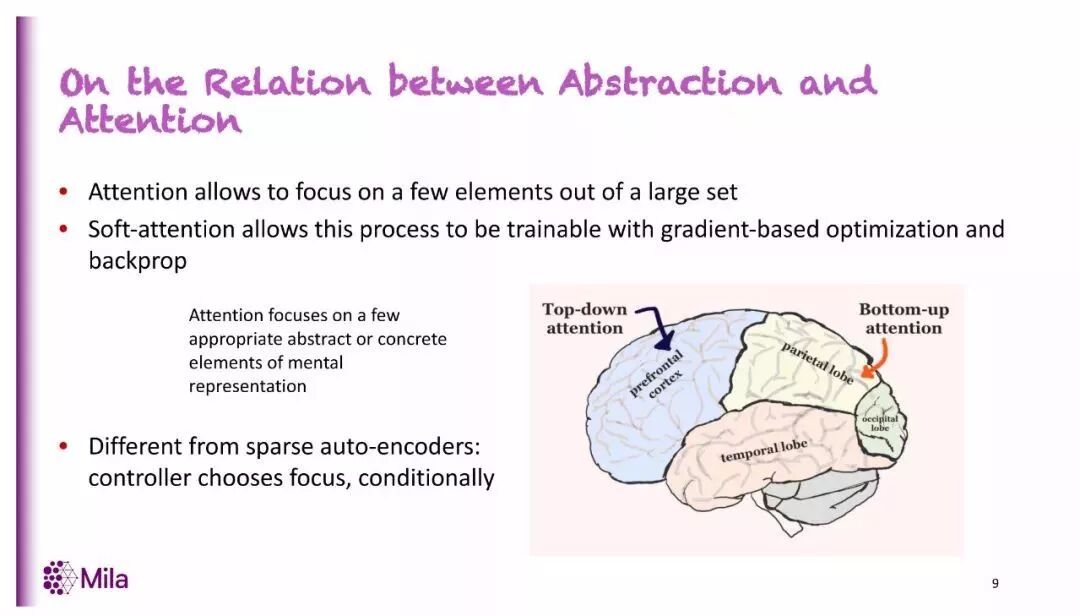
那么要如何实现这种表征呢?对此,注意力机制是一种很重要的工具。注意力机制可以按顺序选取重点关注的信息,来实现整个系统的端到端训练。我们不需要设计一个独立的系统来做这种选择。你可以将注意力机制作为在某些全局目标下端到端训练的更大系统的一部分。而这正是深度学习擅长的地方。
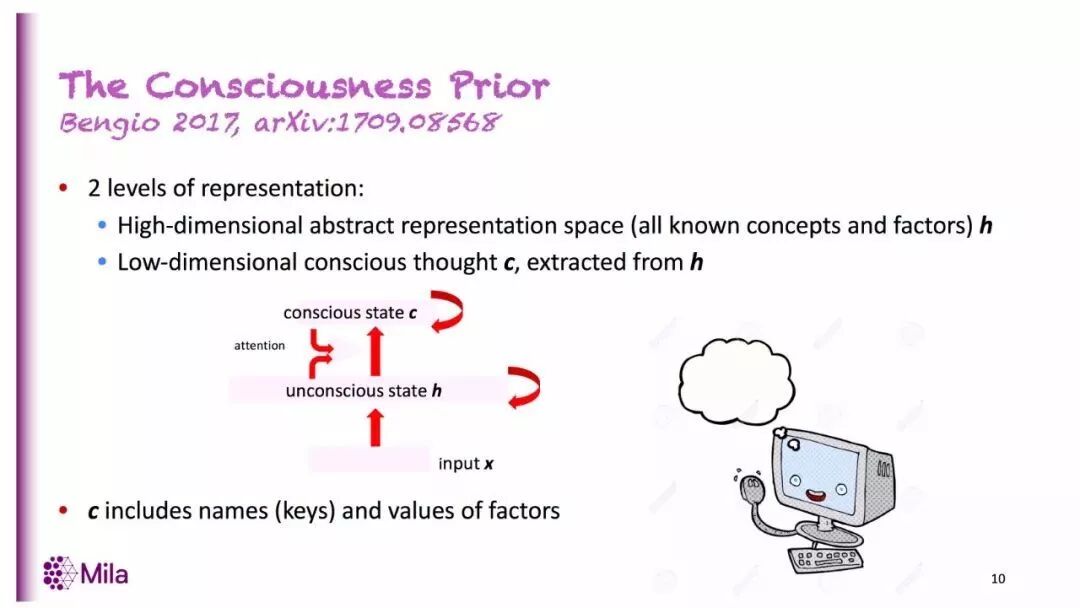
在架构方面,意识先验在「原始输入」和「某些更高级的表征」之外,还引入了第三个层次:这也就是有意识状态(conscious state)。
 这个理论框架还有非常多的细节需要完善,去年我们主要关注其中的一个方面:目标函数。机器学习和深度学习中的标准训练目标函数都基于最大似然估计,而即使与最大似然无关的目标函数,例如 GAN 的一些目标函数,也是在像素级别进行构建的。然而,我们实际上想要在隐藏空间中表现出可预测性。
这个理论框架还有非常多的细节需要完善,去年我们主要关注其中的一个方面:目标函数。机器学习和深度学习中的标准训练目标函数都基于最大似然估计,而即使与最大似然无关的目标函数,例如 GAN 的一些目标函数,也是在像素级别进行构建的。然而,我们实际上想要在隐藏空间中表现出可预测性。

现在的NLP任务只是在文本+标注上训练模型。

这样会出现很多常识性的错误,因为它并没有理解语言内在的含义。

要真正理解自然语言,不仅要对语言本身建模,还要对所处环境进行建模。要将语言学习和世界运转方式的学习相结合。

机器需要对事物之间的因果联系进行建模。

BabyAI通过19个由易到难的游戏关卡而不断学习,就像婴儿成长的过程一样。这很像课程学习(curriculum learning)。
参考链接:
https://www.tsinghua.edu.cn/publish/cs/4853/2018/20181109094211284258009/20181109094211284258009_.html
https://www.jiqizhixin.com/articles/2018-11-08-4

深度学习 AI 圣经
Yoshua Bengio 著
长按二维码购买
作者:闻菲 来源:新智元

【新智元导读】深度学习三巨头之一的Yoshua Bengio昨天在arXiv上传论文,署名只有他一人。Bengio在文中提出了一种
“意识先验”,认为在现有模型和表征的基础上,还需要增加一个预测未来的因素,也即对“意识”的表征。Bengio认为这种全新的理论有很多展开方式,而且大幅偏离现有的数据建模方法和对未来的假设(即未来状态基于智能体的行动),或将为我们研究学习打开全新的局面。
关于自由意志是否存在,人类已经争论了几千年。越来越多的神经科学家通过实验,得出结论认为人类对于自由,或者说“自我掌控”的主观体验,可能只是一种错觉。
等等,为什么我们要在这里说自由意志?
深度学习三巨头之一的Yoshua Bengio,昨天在arXiv上传了一篇论文,不长,只有4页,而且署名只有他一人。作为伟大(出名)科学家的好处(往往也是坏处),可能就是你的一举一动都随时有人关注。所以,我们今天将介绍这篇论文。
Reddit网友评论称,谁没有过这样的体验——晚上喝高了狂书4页纸宣泄完一个让自己感觉好到爆的概念,然后上传到arXiv?还有人说,这篇论文有着很多上世纪80年代论文那样模糊、大胆和明晰的语言,那时候的人还无所畏惧,毫不担心自己会因为研究AGI(通用人工智能)而出丑。
总之,让我们来看这篇论文。但在此之前,还是先把自由意志的话题说完,因为这确实与Bengio的论文有关。
20世纪60年代中期,德国科学家Hans Helmut Kornhuber和Lüder Deecke发现,大脑在产生意识知觉前的瞬间会进入一种特殊的状态,他们将其称为“bereitschaftspotential”(BP),也即“准备电位”。
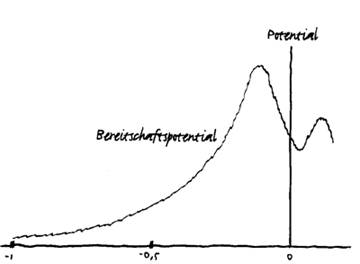
实验中,Kornhuber和Deecke要求参与者动一下手指(自发行为),但脑电图(EEG)扫描却显示,在这个动作发生前,大脑运动皮层出现了一个缓慢的负电位变化。这个观察结果完全出乎意料而且违反直觉。他们不得不得出结论认为,潜意识会引起自发行为。
后来的神经科学家使用更先进的方法和工具,设计更完备的实验,也得出了类似的结果。
总之,在人行动前,还有一个存在于意识的阶段,能够影响乃至决定这些行动;甚至在意识形成前,还有一个无意识的阶段,能够影响人类的决策。但,这就说得太远了。
Bengio的论文与意识和行动有关。他在论文中提出了一个“意识先验”(Consciousness Prior),认为在实际行动之前的抽象空间里,也应该有一个低维向量来表征意识,这对之后在像素空间发生的行为有预测作用。
Bengio在论文中对他的意识先验理论做了介绍。假设在时间 t 观察到的状态是 st,ht则是从 st 推演得到的高级表征,那么 ht 可能是某种RNN的输出:
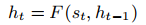
在这里函数F 被称为表征RNN(representation RNN),ht 为表征状态(representation state)。表征RNN可以被视为大脑在时间t的几乎全部内容,表征状态 ht 则是非常高维(并且稀疏)的向量,是智能体能够获取的所有信息的抽象表征。
然后,定义意识状态 ct,ct 是低维向量,使用注意力机制从 ht 推演而来, ct 与前一个时间点 ct-1 有关。这时,
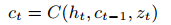
zt 是随机噪音源。
ct 的值对应思维的内容,也是我们在无意识中获取的信息的一个很小的子集,但在注意力机制的影响下被带入了意识中。函数C 是意识RNN(consciousness RNN),在随机噪音输入的影响下,随机在注意力作用下的几个要素中进行选择。意识RNN可用于探究对未来的规划或预测,还可以用来隔离出个别高级抽象,并从中抽取信息。
为了确保假设成立,即有意识的思想能够完整地包含对未来状态的陈述,论文引入了验证网络(verifier network),将过往意识状态 ct-k 与当前表征状态 ht 匹配:
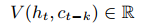
V(ht, ct-k) 表明在给定 ht 估计对应状态概率为真。
最后,鉴于语言是意识最佳也是最方便的一种载体,Bengio还用另一个RNN来描述意识状态到言语的映射:
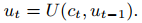
这样,使用语言的学习智能体就有了额外的信息。Bengio还写道,这项研究打开了将深度学习与经典符号AI和认知科学联系起来的大门,并将深度学习从感知转移到更高层次的认知和知识表征。
当然,这并不是说我们要回归到符号主义,而是“去考虑由深度学习智能体所捕获的那些表征的一种正则化形式,可以具有许多经典AI事实和规则的属性,同时也为在这个拥有各种不确定和非离散方面的世界中进行推理和规划提供更加丰富的表征”。
好,讲到这里,借用一位Reddit用户说的,我们缺的就是Pytorch的实现啦:-D
Bengio在论文中讨论了如何针对意识先验设计实验,像他常说的那样,要从toy experiment开始。但更多内容,你还是直接看论文吧~

摘要
本文提出了一种表征学习的新先验,可以与其他先验结合,相互辅助解开抽象因子。这种先验受意识现象的启发而来,意识被视为构成一种意识思维的几个概念形成低维组合的过程,即在特定时刻感知到的意识。这为表征(representation)提供了强大的约束,因为这样低维的思维向量可以对应于关于现实的陈述,这些陈述可以是真实的,也可以是极有可能的,还可以是对作出决定非常有用的。当前状态的几个要素可以组合成这样一个具有预测性或有用的陈述,无疑是一个强有力的约束,并在很大程度上偏离了数据建模的最大似然法以及未来状态基于智能体行动的认知。意识先验让智能体在抽象空间而不是在知觉(例如像素)空间中进行预测,每次预测时都只涉及抽象空间的几个维度。在将意识状态映射为自然语言表述,或用事实和规则的形式表达经典AI知识的时候,使用意识先验也让整个过程更加自然,尽管意识状态可能比那些能够用句子、事实或规则的形式表达出来的内容更加丰富。
论文地址:https://arxiv.org/pdf/1709.08568.pdf
深度学习 AI 圣经
Yoshua Bengio 著
长按二维码购买









