
这两年,大家的目光几乎被“大模型”三个字牢牢吸住了,谁超越了谁、榜单排名第一,少有人关注模型之外的东西。
直到 Deepseek 用非常低的成本训练出能和 OpenAI 媲美的模型,这一下子“打醒”了很多人——
原来在大模型进化的路上,不是光靠“买卡堆料”、“卷模型参数”就能一路狂奔的。
再加上,前段时间 DeepSeek 还放出了一些技术杀手锏,开源了很多底层技术,让很多人回过神儿来——
除了模型本身,还有太多重要的拼图,比如训练推理的效率、高效的框架、适配的硬件等等,缺一不可。
终于,近期的关注点开始回归到深度学习领域的经典四层架构了——

大模型之下,是深度学习框架层。
在如今推理类模型横行的时代下,“Test-time Scaling Law”的红利显然还没有被压榨殆尽,如何让大模型“吐字”更快一点,就能有望让模型的智能程度再高一点。
至此,深度学习框架的重要性被放大了,亟需一场价值重估。
大模型动辄几千亿的参数,一个深度学习框架能否在同等的算力下,尽可能的缩短模型训练时间的同时保住训练效果?
推理时,能否在降低延迟、提升吞吐的情况下稳住计算精度?
部署时,能否轻松的适配公司的硬件设施,发挥出硬件最大性能?
这些问题,都是深度学习框架被日渐放大的价值。
因为,大模型的这些工程化难题,都藏在了深度学习框架里。
大模型时代,框架的使命感
最近,笔者发现了一组比较惊人的数字——
百度深度学习框架「飞桨」适配 DeepSeek-R1 后,据官方测试,其 FP8 推理的单机每秒输出 token 数,可以达到 1000+,如果是 INT4 比特部署的话,每秒输出 token 数甚至可达 2000 以上。
相比主流的方案 vLLM FP8 和 SGLang FP8,分别快了 37.2% 和 111.4% 。
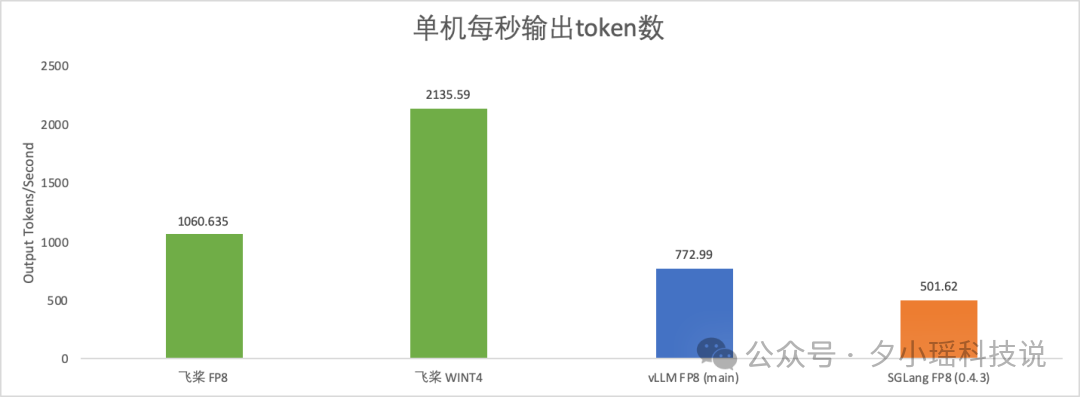
而在 WINT4 的极致性能下,比 vLLM FP8 快约 176.2%,比 SGLang FP8 快约 325.7%
还有一组来自飞桨官方公众号的数字——
“吞吐提升 144%”、“解码速度提升 42%”、“首 token 推理速度提升 37%”。

这里先简单解释一下解码速度和吞吐两个概念。
解码速度:指的是模型在推理时生成 Token 的速度,也是如今推理类模型实现推理阶段 scaling law 的重要关注指标。
吞吐:指单位时间内模型能处理的整体输出量,代表并发场景下的总处理能力。
举个例子。你在一家餐厅点餐,解码速度就像厨师炒一道菜的速度(比如每分钟炒 10 盘菜)。而吞吐则是餐厅一小时能服务多少盘菜(考虑所有厨师和订单)。
- 在解码速度不变(单次生成效率没变)的情况下,吞吐提升 144%,说明系统整体效率大幅提高,这对高并发场景特别重要,能服务更多用户。
- 吞吐接近,说明系统整体处理能力没怎么变,但解码速度提升 42%,意味着单次生成任务的响应更快了。这对实时性要求高的场景很关键,用户会明显感觉到“模型反应更快了”。
- Prefill 是大模型推理的初始阶段,长序列的 Prefill 阶段通常很耗时,因为注意力计算量随序列长度平方增长。首 Token 推理速度提升 37%,用户等待时间更短。这对长文本处理(比如总结长文章、处理法律文档)特别有帮助。
这背后,是最新的飞桨框架3.0。
可以这么理解,飞桨框架3.0 就是
为大模型量身定制的深度学习框架。
前段时间 DeepSeek 开源周,第一天炸场的就是 FlashMLA,被认为是目前业内最优的大模型推理方案之一。
飞桨为了把 DeepSeek R1 的推理性能压榨到极致,对 MLA 算子进行了多级流水线编排、精细的寄存器及共享内存分配优化。
通过深度调优 MLA 算子,性能比 FlashMLA 领先 4%~23%。
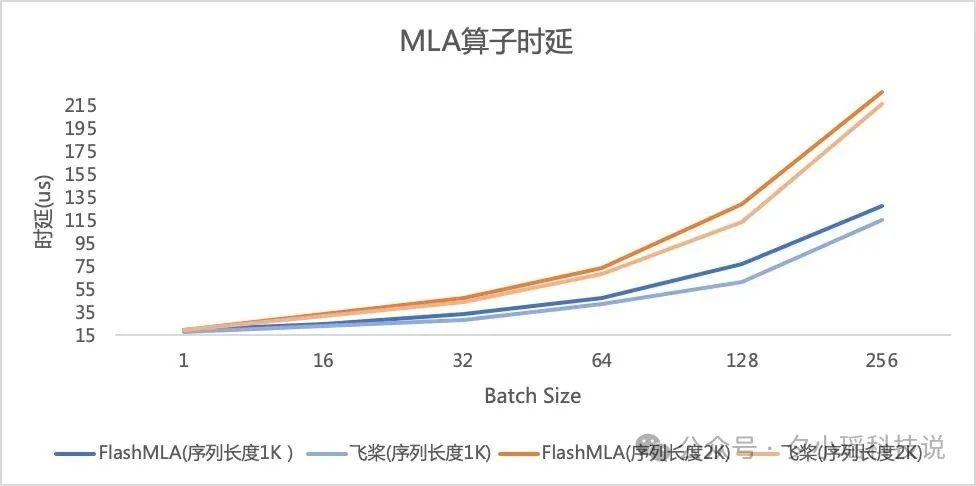
不仅仅是为 DeepSeek R1 这样的开源模型量身定制了一套高效推理方案,飞桨框架3.0更可以让模型性能“更上一层楼”。
要说以前的大模型项目如何落地,我只能说什么花样都有。
过去,闭源模型时代,大模型的效果和落地方案往往被捆绑销售,企业很难自由选择最优组合。
但现在,一切都不一样了,大模型终于重回开源生态主导。
DeepSeek 开源技术搭配飞桨框架3.0 的“王炸组合”,让开发者既能用上顶尖模型,又能享受极致推理效率,还能轻松适配 A800 等非 Hopper 架构硬件。
灵活性和普适性,正是深度学习框架的使命所在。
承载这个使命的国货之光,我觉得「百度飞桨」是当仁不让的。这里有必要展开科普。
模型要“追新求变”,框架得“厚积求稳”
作为一个从 2016 年就开源的国产老牌框架,飞桨可以说是国内寥寥无几的能经受的住 AI 发展史严苛检验的深度学习框架。
模型要“追新求变”,但框架一定要“厚积求稳”。
飞桨框架3.0 正式版刚刚正式发布。
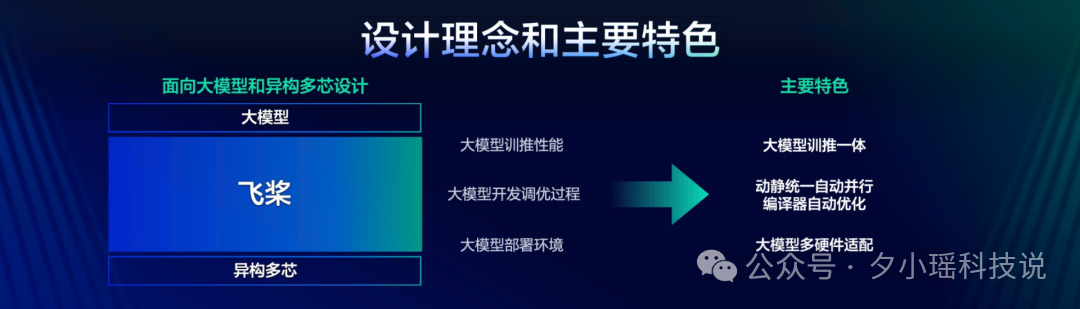
从它的设计理念图就能看出来——
充分考虑大模型分布式训练和推理性能。
比如,动静统一自动并行便是为了支撑大模型分布式训练而生。
你可以这样理解,在飞桨框架中,开发者只需要写单机代码,做一些简单的“张量切分标注”,飞桨就能自动帮开发者切分数据、安排通信,优化显存和调度,找到最省力的分布式并行策略。
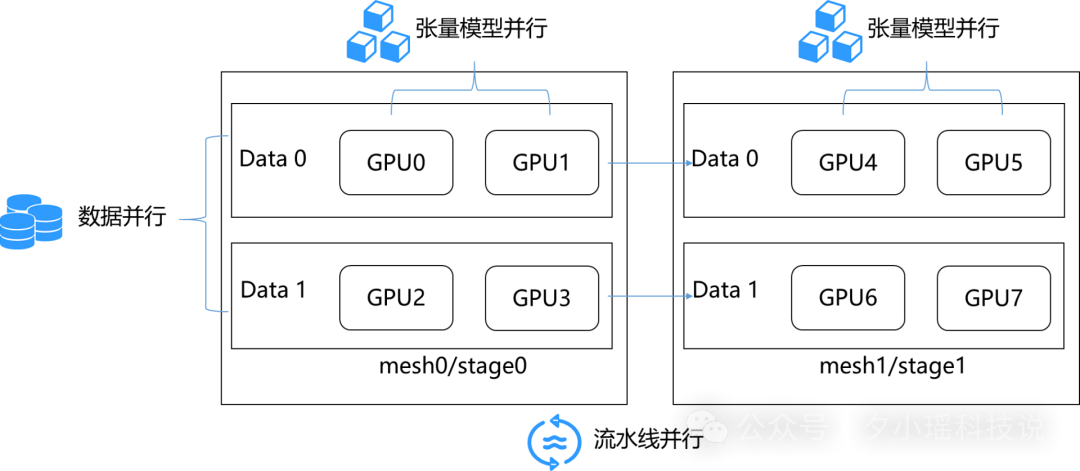
为开发者省掉了大量的分布式性能优化工作,而且自动支持 MoE(混合专家模型)、Dense 等多种模型架构。
比如用飞桨训练 Llama 模型,通过这个黑科技,核心代码量直接砍掉 50%。
“编译器自动优化”技术,可以将多个算子融合成一个大算子,通过减少访存量和算子数量,能够大幅提升模型性能。
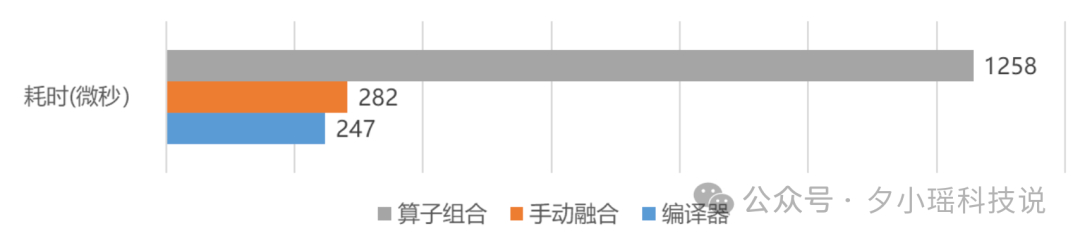
比如,Llama 2 和 Stable Diffusion 模型,仅通过编译器自动优化技术,就得到了超过 30% 的推理性能提升。
通过神经网络编译器优化、算子深度调优这些黑科技,可以说,飞桨框架把硬件性能榨得干干净净。对 MLA 算子的调优后,甚至比 DeepSeek 的 FlashMLA 还要快 4%~23%。
要知道,DeepSeek 这次开源的很多技术都只是针对 H 卡做的,做了很多专用优化。而飞桨,作为一个通用的深度学习框架,却能在垂直问题上,做到比专用框架更强的性能表现,我只能说——
牛逼。
再比如训推一体,简单理解就是训练和推理用同一套“剧本”,不用分开写两套代码。
既可以在训练阶段使用动态计算图来实现模型高效调试迭代,又可以在部署阶段自动将其转换至静态图,实现训练和推理的能力复用。
深度学习框架最大的魅力就是通用性。
保持通用性的同时,还能有超越专用设计的性能表现,是一件极其困难的事情。没有充分硬核的技术积淀,是很难做到的。
飞桨不仅做到了,还联合 24 家伙伴发布飞桨生态发行版,并且进一步将昆仑芯、海光、寒武纪、昇腾、燧原 5 家国产硬件纳入飞桨例行发版体系。
甚至,联合芯片企业制定了国家标准,设计了近 90 个接口,各家的芯片都可以直接用这个标准化的方式接进来,不会再受制于硬件差异
大模型,不是孤立的“模型之争”,而是系统化的“能力之战”。这种“够老够稳”的底蕴,我觉得正是大模型落地所需的坚实后盾。
在这场综合的
效率、实用、生态的变革中,飞桨的含金量在上升。

结语
当大模型竞赛进入下半场,文心 4.5、Qwen、DeepSeek 的这一大波开源浪潮,让大模型重回开源生态主导。
正如上文提到的飞桨框架3.0 带给 DeepSeek R1 的性能突破,提醒我们:参数只是表像,深耕底层的 Infra 建设,是可以真正让大模型转化为可持续的生产力。
框架真正的价值是通用性。既能灵活应对 Dense、MoE 等各类模型结构的优化迭代,也能屏蔽掉部署阶段繁杂的硬件优化适配细节。
而且在中国 AI 产业算力异构化(昆仑、海光、昇腾、寒武纪等等)、场景碎片化的背景下,国产框架正在进化出更顽强的技术韧性,其含金量在持续上升,成为 AI 生态的支撑性关键软件。
飞桨深度学习框架,是时候被重新审视、价值重估了。










