
本文旨在使用PyTorch构建并训练一个最简单的神经网络,无需添加任何花哨的层或依赖包。
该模型将足够简单,大家都能使用CPU或GPU来构建和训练。
这个模型虽然简单,但包含了当前诸如LLM和Stable Diffusions等大型模型所拥有的所有基本元素。
构建一个模型,帮助我们彻底理解训练AI模型的过程,开始前请确保已安装并配置好PyTorch。
另外为了让大家可以更系统的学习人工智能(机器学习、深度学习、神经网络),小墨学长还为大家整理了一份60天入门人工智能机器学习、深度学习、神经网络)的学习路线,从基础到进阶都包含在内,希望可以帮助到大家。
学习路线的资料都下载打包好了
大家可以添加小助手让她把学习路线的思维导图和相关资料一起发给你
准备数据
假设我们要训练一个具有四个权重并能输出一个数字结果的模型,如下所示:
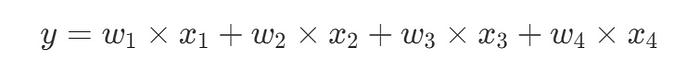
由于我们需要生成一些训练数据,因此假设权重为[2,3,4,7]:
import numpy as npw_list = np.array([2,3,4,7])
我们的模型将用于预测权重列表,因此在使用它生成一些训练数据后,我们假装不知道这些权重。
让我们创建10组输入样本数据——x_sample,每组x_sample是一个包含4个元素的数组,与权重的长度相同。
import randomx_list = []for _ in range(10): x_sample = np.array([random.randint(1,100) for _ in range(len(w_list))]) x_list.append(x_sample)
这里,我们使用numpy,因为我们想利用numpy的点积函数轻松生成输出——y。
说到y,我们来生成一个包含10个元素的y_list:
y_list = []for x_sample in x_list: y_temp = x_sample@w_list y_list.append(y_temp)
我们的训练数据已准备就绪,无需下载任何内容,也无需使用DataLoader等,接下来,让我们定义模型。
定义模型
我们的模型可能是世界上最简单的模型,即以下代码中定义的一个简单的线性点积:
import torch import torch.nn as nnclass MyLinear(nn.Module): def __init__(self): super().__init__()
self.w = nn.Parameter(torch.randn(len(w_list))) def forward(self, x:torch.Tensor): return self.w @ x
在上述代码中,使用self.w = nn.Parameter(torch.randn(len(w_list)))初始化了权重张量。
无需其他代码,我们的神经网络模型现已准备就绪,命名为——MyLinear。
准备训练模型
要训练模型,我们需要像LLM或Diffusion模型那样初始化其随机权重。
几乎所有神经网络模型的训练都遵循以下步骤:
前向传播以预测结果。
与真实值进行比较以获取损失值。
反向传播梯度损失值。
更新模型参数。
因此,在开始训练之前,我们需要定义一个损失函数和一个优化器。
损失函数loss_fn将根据预测结果和真实结果计算损失值,优化器将用于更新权重。
loss_fn = nn.MSELoss()optimizer = torch.optim.SGD(model.parameters(), lr = 0.00001)
lr代表学习率,这是最难设置的超参数之一,确定最佳学习率(lr)通常需要根据模型、数据集和问题的特性进行反复试验。然不过有一些策略和技术可以帮助估计一个合理的学习率。
另外别忘了将输入和输出转换为torch张量对象。
x_input = torch.tensor(x_list, dtype=torch.float32)y_output = torch.tensor(y_list, dtype=torch.float32)
一切准备就绪,让我们开始训练模型。
训练模型
我们将训练周期数设置为100,这意味着我们将遍历训练数据100次。
num_epochs = 100for epoch in range(num_epochs): for i, x in enumerate(x_input): y_pred = model(x)
loss = loss_fn(y_pred, y_output[i]) optimizer.zero_grad() loss.backward() optimizer.step() if (epoch+1) % 10 == 0: print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))print("训练完成")
在上述代码中,我们可以看到两层循环,外层循环用于训练周期,内层循环用于遍历10组样本数据。
我们有10组输入,每组输入有4个元素,即x_1, x_2, x_3, 和 x_4。
正如我们在准备阶段所讨论的,第一步是使用模型预测一个结果:y_pred,然后,调用loss_fn来计算损失值。
在将损失值反向传播之前,我们需要通过调用optimizer.zero_grad()来清除上一次的梯度值。
最后,调用backward和optimizer.step()来更新模型参数。
运行代码,我们将看到程序输出类似于以下内容:
Epoch [10/100], Loss: 218.3843Epoch [20/100], Loss: 283.2002Epoch [30/100], Loss: 116.5593Epoch [40/100], Loss: 43.8340Epoch [50/100], Loss: 16.3244Epoch [60/100], Loss: 6.0721Epoch [70/100], Loss: 2.2586Epoch [80/100], Loss: 0.8400Epoch [90/100], Loss: 0.3124Epoch [100/100], Loss: 0.1162train done
随着时间的推移,损失值在下降,这看起来很不错,让我们检查模型中当前的权重。
得到的结果是:
Parameter containing:tensor([2.0027, 2.9958, 4.0009, 7.0017], requires_grad=True)
这非常接近[2,3,4,7]!模型已成功训练并找到了正确的权重值。
扩展模型规模
在上述示例中,我们只使用4个权重构建了模型,现在我们可以增加权重的数量,如下所示:
w_list = np.array([2,3,4,7,11,5,13])
并再次运行代码,通过增加训练周期数和更新学习率——lr,你将始终看到模型成功预测你给出的任何权重。
使用CUDA进行训练
要使用CUDA训练模型,我们需要将1)模型和2)训练数据移动到CUDA,以下是完整代码。
import numpy as npw_list = np.array([2,3,4,7,11,5,13])import randomx_list = []for _ in range(10): x_sample = np.array([random.randint(1,100) for _ in range(len(w_list))]) x_list.append(x_sample)y_list = []for x_sample in x_list: y_temp = x_sample @ w_list y_list.append(y_temp)import torch import torch.nn as nnclass MyLinear(nn.Module): def __init__(self): super().__init__() self.w = nn.Parameter(torch.randn(len(w_list), dtype=torch.float32)) print("初始权重:", self.w) def forward(self, x:torch.Tensor): return self.w @ x model = MyLinear().to("cuda")loss_fn = nn.MSELoss()optimizer = torch.optim.SGD(model.parameters(), lr = 0.00001)x_input = torch.tensor(x_list, dtype=torch.float32).to("cuda") y_output = torch.tensor(y_list, dtype=torch.float32).to("cuda") num_epochs = 200 for epoch in range(num_epochs): for i, x in enumerate(x_input): y_pred = model(x) loss = loss_fn(y_pred, y_output[i]) optimizer.zero_grad() loss.backward() optimizer.step() if (epoch+1) % 10 == 0: print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))print("训练完成")
总结
PyTorch简化了整个模型构建和训练过程,准备数据、准备训练和训练过程仅用几行代码即可完成,排除了不必要的复杂性。
另外我们精心打磨了一套基于数据与模型方法的 AI科研入门学习方案(已经迭代过5次),对于人工智能来说,任何专业,要处理的都只是实验数据,所以我们根据实验数据将课程分为了三种方向的针对性课程,包含时序、图结构、影像三大实验室,我们会根据你的数据类型来帮助你选择合适的实验室,根据规划好的路线学习 只需 4 个月左右(很多同学通过学习已经发表了 sci 一区及以下、ei会议等级别论文)学习形式为 直播+ 录播,多位老师为你的论文保驾护航,如果需要发高区也有其他形式。
还有图结构、影像两个实验室(根据你的数据类型来选择)
大家感兴趣可以直接添加小助手微信:ai0808q 通过后回复咨询既可!
AI for science
大家想自学的我还给大家准备了一些机器学习、深度学习、神经网络资料大家可以看看以下文章(文章中提到的资料都打包好了,都可以直接添加小助手获取)
大家觉得这篇文章有帮助的话记得分享给你的
死党、闺蜜、同学、朋友、老师、敌蜜!











