1. 引言
股票价格预测一直是金融领域的核心挑战之一,其复杂性源于宏观经济状况、投资者情绪等多种因素。尽管如此,专业交易员和研究人员通常通过理解市场关键属性(如波动性和流动性)以及识别模式来预测未来市场趋势。近年来,人工智能的兴起推动了机器学习算法在预测未来市场趋势方面的应用,特别是深度学习(DL)模型在模拟环境中使用历史数据预测市场趋势方面取得了超过88%的F1分数。然而,在现实市场中复制这些性能极具挑战性,这表明模拟与现实之间可能存在差距。
本文旨在对基于限价订单簿(LOB)数据的最新且最先进的深度学习(DL)股票价格趋势预测(SPTP)方法进行全面测试,以评估其鲁棒性和泛化能力。LOB数据是交易员在股票市场上可获取的最有价值的信息来源之一,因为它提供了关于股票交易的原始且细粒度的信息。
2. 主要贡献
本文的主要贡献可以概括如下:
现有LOB基股票市场趋势预测器的评估:我们评估了现有的基于LOB的股票市场趋势预测器,结果表明,大多数模型在FI-2010数据集上过拟合,在未见过的股票数据上表现明显下降。
不同市场场景下现有方法的财务表现调查与讨论:我们调查并讨论了现有方法在不同市场场景下的财务表现,旨在为现实应用中的模型选择提供指导。
现有方法的优缺点讨论:我们讨论了现有方法的优点和局限性,并确定了未来研究的方向,以实现更可靠、更稳健、更可重复的股票市场预测方法。
3. 股票价格趋势预测
本文研究的模型有一个共同的目标,即通过在LOB数据上训练的深度神经网络(DNN)来解决SPTP问题。LOB数据之所以具有启发性,是因为它们提供了关于股票交易的原始和细粒度的信息。通过在固定时间段内观察LOB,SPTP模型可以返回关于未来可能的市场走势的分布。
3.1 限价订单簿(LOB)
股票交易所采用匹配引擎来存储和匹配交易代理发出的订单,这是通过更新所谓的限价订单簿(LOB)数据结构来实现的。每个证券(可交易资产)都有一个LOB,记录了当前在交易所或交易平台上所有未执行的买卖订单。订单簿的形状为交易员提供了市场供需的同步视图。
订单主要有三种类型:
- 限价订单:指定目标价格,只有当其与价格大于或等于目标价格的买[卖]订单匹配时才会执行。
3.2 趋势定义
我们使用三元分类法来定义趋势:
由于中点价格的信息量丰富,因此非常适合驱动这种分类。然而,由于市场固有的波动性和冲击,它们可能会表现出高度波动的趋势。因此,直接比较连续的中点价格(即 和 )进行股票价格标注会导致标注数据集出现噪声。因此,标注策略通常采用平滑的中点价格函数,而不是原始的中点价格。这些函数考虑了任意长时间间隔(称为时间范围)内的中点价格。
我们所采用的标注策略将当前中点价格与未来 个时间单位的平均中点价格 进行比较,公式如下:
平均中点价格用于定义一个静态阈值 ,用于识别当前中点价格周围的区间,并定义时间 的趋势类别如下:
通过这种标注方法,我们通过考虑所需时间范围 内中点价格的平均值来消除中点价格波动的影响,并在平均中点价格变化不显著时认为趋势是稳定的,从而避免了过拟。
4. 实验
我们进行了广泛的评估,以评估 15 个 DL 模型解决 SPTP 任务的鲁棒性和泛化能力。在这些模型中,有 13 个是最先进的模型,另外两个是文献中常用的 DL 基线模型。
4.1 数据集
LOB 数据通常不公开且价格昂贵:股票交易所(例如,纳斯达克)仅以高额费用提供细粒度的数据。高成本和低可用性限制了 DL 算法在研究社区的应用和发展。
最广泛传播的公共 LOB 数据集是 FI-2010,该数据集于 2017 年由 Ntakaris 等人提出,旨在评估机器学习模型在 SPTP 任务上的表现。该数据集由来自纳斯达克北欧股票市场的五家芬兰公司的 LOB 数据组成:Kesko Oyj、Outokumpu Oyj、Sampo、Rautaruukki 和 Wartsila Oyj。数据跨度为 2010 年 6 月 1 日至 6 月 14 日,对应于 10 个交易日(交易日仅在营业日进行)。大约有 400 万条限价订单消息存储在 LOB 的 10 个级别中。该数据集具有基于事件的粒度,这意味着时间序列记录在时间上不是均匀间隔的。LOB 观察值每 10 个事件采样一次,总共产生 394,337 个事件。该数据集的固有局限性在于它已经被预处理(过滤、归一化并标注),因此无法回溯原始的 LOB,从而阻碍了彻底的实验。此外,所采用的标注方法被发现容易出现不稳定现象。此外,该数据集在不同预测时间范围上不平衡。随着时间范围 的变化,静止类 S 逐渐不如上升和下降类占优势。
为了在更现实的场景中测试模型的泛化能力,我们使用了从 LOBSTER 提取的数据,LOBSTER 是一个在线 LOB 数据提供商,提供订单簿数据。与健康和金融等关键应用一样,这些数据不是免费的。该数据是从纳斯达克交易的股票中重建的,并且每年支付费用后可供研究社区公开使用。为了比较算法在各种场景下的性能,我们创建了一个大型 LOB 数据集,包括几只股票和几个时间段。所选股票池包括纳斯达克流动性最高的 50% 的股票。为了创建一个具有挑战性的评估场景,我们选择了六只股票,分别是:SoFi Technologies (SOFI)、Netflix (NFLX)、Cisco Systems (CSCO)、Wing Stop (WING)、Shoals Technologies Group (SHLS) 和 Landstar System (LSTR)。所考虑的时间段为 2021 年 7 月(2021-07-01 至 2021-07-15,共 10 个交易日),构成 LOB-2021,以及 2022 年 2 月(2022-02-01 至 2022-02-15,共 10 个交易日),构成 LOB-2022。这两个时间段的选择旨在捕捉不同市场波动水平的数据。2022 年 2 月的波动性高于 2021 年 7 月,主要是受乌克兰危机的影响。这允许评估模型在不同市场条件下的表现。
4.2 模型
我们选择了 13 个基于 DL 的 SPTP 任务的最先进模型。这些模型发表在 2017 年至 2022 年间的论文中,并利用 LOB 数据进行训练和测试。除了所选论文中提出的模型外,我们还包括了两个经典的 DL 算法,即多层感知器(MLP)和卷积神经网络(CNN),它们分别在 [27] 和 [31] 中用作基准。所有提出的模型都基于 DNN,并且最初是在 FI-2010 数据集上训练和测试的。
4.3 LOBCAST 框架用于 SPTP
我们介绍了 LOBCAST,这是一个基于 Python 的框架,用于使用 LOB 数据进行股票市场趋势预测。LOBCAST 是一个开源框架,使用户能够测试用于 SPTP 任务的 DL 模型。该框架提供数据预处理功能,包括归一化、拆分和标注。LOBCAST 还为 PyTorch Lightning 中实现的 DL 模型提供了一个全面的训练环境。它集成了与流行的超参数调整框架 WANDB 的接口,使用户能够高效地调整和优化模型性能。该框架为训练好的模型生成详细的报告,包括有关学习任务的性能指标(F1、准确率、召回率等)。LOBCAST 支持回测以进行利润分析,利用 Backtesting.py 外部库。此功能使用户能够在模拟交易场景中评估其模型的盈利能力。我们计划添加新功能,例如 (i) 使用不同的 LOB 表示进行训练和测试,以及 (ii) 对对抗性扰动进行测试以评估表示的鲁棒性。我们相信,LOBCAST 以及 DL 模型和 LOB 数据的使用方面的进步,有潜力提高金融领域趋势预测的最新水平。
4.4 性能、鲁棒性和泛化能力
为了测试鲁棒性和泛化能力,我们使用五个不同的种子对每个模型进行了实验,以确保结果可靠并减少网络权重随机初始化和训练数据集打乱的影响。训练过程涉及在每个预测时间范围 上对所有 15 个模型进行训练。对于所有 5 次运行的平均值,所有模型的训练过程在 FI-2010 上平均花费了大约 155 小时,在 LOB-2021/2022 上平均花费了 258 小时,利用了一个由 8 个 GPU 组成的集群(1 个 NVIDIA GeForce RTX 2060、2 个 NVIDIA GeForce RTX 3070 和 5 个 NVIDIA Quadro RTX 6000)。
结果以F1分数为主要指标,辅以鲁棒性和泛化性得分,其中鲁棒性得分定义为 ( 100 - (|A| + S) ),( A ) 表示原始论文F1分数与实验复现F1分数的平均差,( S ) 为差异的标准差。实验数据表明,BINCTABL模型在FI-2010数据集上表现最佳,平均F1分数达到82.6% ± 7.0,鲁棒性得分高达99.7,排名第一,但其预测倾向于稳定类(S),反映出数据集的不平衡性(例如 ( k=1 ) 时稳定类占比63%)。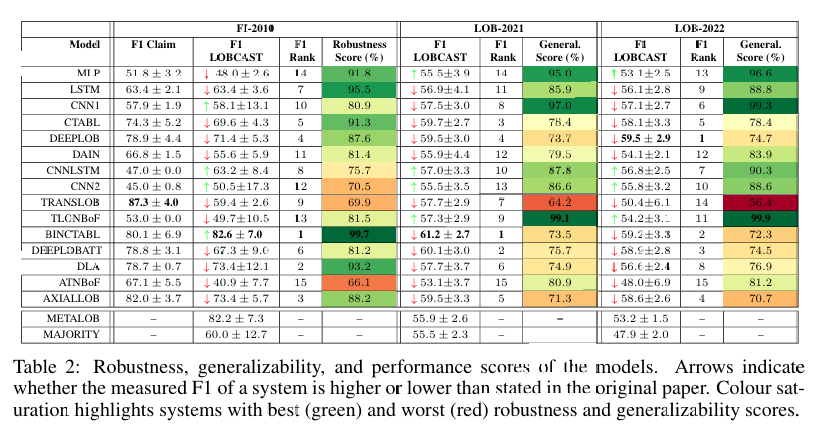
在鲁棒性测试中,部分模型未能达到其原始论文声称的性能水平。例如,TRANSLOB和ATNBOF的复现F1分数与声明值差距最大,分别位列鲁棒性排名的倒数第二和倒数第一,ATNBOF整体表现最差,这可能源于原始代码和超参数的缺失。CNN1、CNN2、CNNLSTM、TLONBOF和DLA模型对网络权重初始化和数据集洗牌高度敏感,标准差超过5个百分点,显示出性能的不稳定性。值得注意的是,排名前三的模型并未使用常见的 ( h=100 ) 长市场观察窗口,而是依赖较短时间框架内的动态,表明关键预测信息可能集中在近期数据中。混淆矩阵分析进一步证实,BINCTABL在 ( k=1 ) 和 ( k=10 ) 窗口下对稳定类的偏好,这与FI-2010数据集的类分布一致。
泛化能力测试显示,所有模型在LOB-2021和LOB-2022数据集上的F1分数显著下降,范围在48%至61%之间,相较于FI-2010上的表现普遍降低。BINCTABL的F1分数平均下降19.6%,泛化得分仅为73.5%,表明其对新数据的适应性有限。LOB-2022的性能低于LOB-2021,可能因股票波动性更高,且LOBSTER数据集复杂度远超FI-2010(事件量约为FI-2010的三倍)。在具体股票中,CSCO因高稳定性(训练集类分布为18-65-17%)表现最佳,混淆矩阵显示模型在稳定类预测上最优。交易模拟结果进一步验证了任务的挑战性,使用LOB-2021数据的盈利性不稳定,凸显当前模型在真实市场场景中的局限性。
5. 讨论与结论
我们的研究结果表明,基于 LOB 数据使用 DNN 的价格趋势预测器并不可靠,因为它们通常表现出非鲁棒和非泛化的性能。我们的实验表明,现有的模型容易受到超参数选择、随机化和实验环境(股票、波动性)的影响。此外,数据集的选择和实验设置未能捕捉到现实世界的复杂性。这种缺乏泛化能力使它们不适合在现实环境中进行实际应用。










