因果推断是一种利用统计学和数学方法来确定一个变量对另一个变量的实际影响的技术。简而言之,它用于理解某种处理或干预是否与特定结果变量存在因果关系。因果推断已广泛应用于社会科学、经济学、政治学和市场营销等多个领域的研究中 ¹。在本文中,我将介绍一种因果推断方法——双重机器学习(Double Machine Learning, DML),这是一种结合了因果推断与机器学习算法的多功能且常用的因果推断模型。
1. 方法论
因果推断的第一步(也是任何因果推断中的重要一步)是发现变量之间的潜在因果关系,这一过程被称为因果发现。它使我们能够量化变量之间的因果效应和关系。在本节中,我将通过一个示例数据集演示如何发现变量之间的因果关系,并随后利用因果发现的结果应用 DML 来量化影响。
假设某公司有一款电子产品,包含多个功能。开发团队发布了五个新功能,并希望了解这些新功能的使用是否对产品的整体使用量有直接影响。除了产品及其功能的使用情况外,数据集中还包含设备的显示尺寸、内存大小以及设备是否连接到网络等其他维度。该数据集包含约 130 万行数据,每一行代表一台设备的参与情况。下表 1 显示了每个变量的类型及其度量内容。

2. 通过因果图进行因果发现
一种常用的因果发现方法是因果图。这里我使用了我同事在一篇文章 ² 中介绍的框架,该框架利用 Python 中的 lingam 包创建变量的邻接矩阵。
假设我们想知道处理变量 1 与结果变量之间是否存在因果关系。下图 1 显示了变量的邻接矩阵,其中数值表示一个变量对另一个变量的影响,箭头表示影响的方向。我们可以看到处理变量 FeatureIUsed 对结果变量有负面影响,数值 -3.55 可以解释为:使用功能 I 的用户整体上使用产品的频率较低,平均比未使用该功能的用户少 3.55 天。
 图1:治疗组1、结果变量和其他变量之间的因果关系。
图1:治疗组1、结果变量和其他变量之间的因果关系。在因果推断中,那些对结果变量有影响但并非研究重点的变量被称为协变量、混杂变量或混杂因素。它们可以被视为实验中的控制变量,但由于限制无法保持恒定。混杂因素的存在通常会使处理变量的效果与混杂因素的影响混合在一起,从而难以量化处理的真实影响。从图 1 中我们可以看到,诸如 IsCloudConnected、IsNewDevice 和 ScreenDisplaySize 等变量对结果变量有影响,但它们并非恒定,因此可以被视为混杂因素。
我们可以对其他四个处理变量重复相同的过程,以确定是否存在因果关系并分类混杂因素。例如,图 2 显示了处理变量 2 与其他变量的邻接矩阵。
 图 2:治疗组2、结果变量和其他变量之间的因果关系。
图 2:治疗组2、结果变量和其他变量之间的因果关系。另一种简单快速的方法是可视化每个处理组和对照组的结果变量分布,并检查是否可以观察到组间差异。图 3 展示了基于处理组与对照组的结果变量分布,从中我们可以估计处理变量对结果变量的影响。
 图 3:结果的分布与治疗变量的分布。
图 3:结果的分布与治疗变量的分布。在发现因果关系并识别混杂因素后,下一步是构建因果推断模型。
3. 通过双重机器学习进行因果推断
为了更好地理解 DML 背后的概念,让我们从简单的线性回归开始。在统计学中,线性回归用于估计因变量(X)与自变量(y)之间的线性关系。模型可以表示为公式 1:
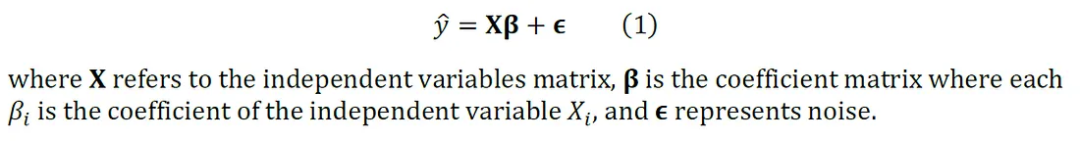
为了衡量处理的影响,我们引入了平均处理效应(Average Treatment Effect, ATE)。ATE 用于衡量处理组与对照组之间结果均值的差异。以下公式 2 展示了可用于估计 ATE 的线性回归模型:

然而,在以下情况下,使用线性回归估计 ATE 可能会面临挑战:(1) 数据集是高维的(即特征数量大于观测数量),(2) 控制变量过于复杂,无法通过线性模型估计,(3) 处理效应在人口的不同子组中不同(例如,非均匀性),(4) 数据集中存在混杂因素,或 (5) 处理效应是非线性的。正是在这些情况下,DML 方法可以改进因果效应或 ATE 的估计。
顾名思义,DML 包括构建两个机器学习(ML)模型——一个模型使用控制变量预测处理变量(称为处理模型),另一个模型使用相同的控制变量预测结果变量(称为结果模型³。处理模型用于估计处理分配的概率,而结果模型仅使用控制变量来估计结果 ⁴。在训练每个机器学习模型时,计算每个模型的残差或误差,并在 DML 的最后阶段使用这些残差,将结果模型的残差对处理模型的残差进行回归:
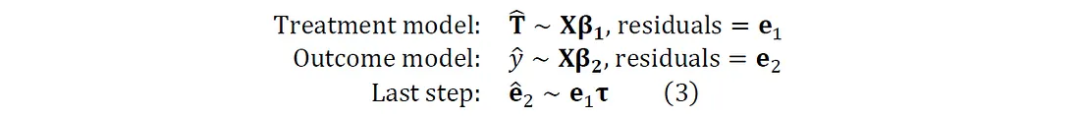
在最终估计步骤中使用的模型可以采用不同的形式——线性、非线性和核方法是常用的架构。在本例中,我使用线性模型,因为数据集不是高维的,并且可以假设线性异质性。接下来,我们将探讨如何使用 EconML 在 Python 中实现线性 DML 模型。
4. 使用 EconML 包实现 DML
EconML 是一个 Python 包,用于通过机器学习从观测数据中估计异质性处理效应。该包是微软研究院 ALICE 项目的一部分,旨在将最先进的机器学习技术与计量经济学相结合,以自动化解决复杂的因果推断问题 ⁵。线性 DML 是 DML 类中的一种方法,它使用无正则化的线性模型作为最后一步。
首先,从 EconML 中导入 LinearDML 方法:
from econml.dml import LinearDML
根据上一节的因果发现结果,定义处理变量、混杂因素和结果变量:
# 处理变量
T = "FeatureIUsed"
# 混杂因素
W = ["IsCloudConnected", "IsNewDevice", "CanHaveLoginExperience", "ScreenDislaySize"]
# 结果变量
y = "NumberOfDaysUsedProduct"
接下来是构建线性 DML 模型。由于处理变量是二分类变量(0 或 1),处理模型使用随机森林分类器;而结果变量是整数值,因此结果模型使用随机森林回归器:
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
# 处理模型
treatment_model = RandomForestClassifier()
# 结果模型
outcome_model = RandomForestRegressor()
# 线性 DML
model = LinearDML(model_y=outcome_model, model_t=treatment_model, discrete_treatment=True, categories=[0, 1], random_state=0)
model.fit(Y, T, W=W, X=None)
由于最终步骤的模型是线性模型,因此可以轻松找到估计的系数(ATE)、p 值和置信区间:
ate = model.intercept_
p_val = model.intercept__inference().pvalue()
ci = model.intercept__interval()
最后,为每个处理变量重复创建 LinearDML 模型的步骤,并收集每个模型的统计结果。结果如表 2 所示。
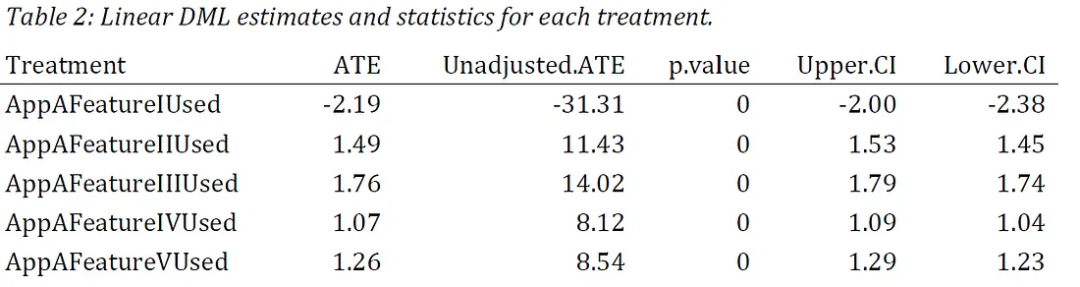
表 2 显示,在显著性水平 α = 0.05 下,所有五个处理变量对结果变量均具有统计显著的因果效应(即 p 值 < 0.05)。此外,只有处理变量 1 对结果变量有负面影响,其估计的 ATE 表明,使用功能 I 的用户平均比未使用该功能的用户少使用产品 2.19 天。通过比较 ATE 的绝对值,可以清楚地看出处理变量 1 对结果变量的影响最大,其次是处理变量 III。
5. 结论
本文探讨了一种常用的因果推断模型——DML 的方法论,并通过一个具体示例演示了其实现过程。需要注意的是,DML 有许多变体,处理模型和结果模型可以采用随机森林以外的形式,而最终阶段的估计模型也可以根据数据集的特征选择非线性或非参数模型。DML 是一种简单而强大的方法,可用于解决许多估计问题。因此,下次当你想探究两个变量之间是否存在因果关系时,不妨考虑使用 DML!
References
- Holland, P. W. Statistics and causal inference. Journal of the American Statistical Association 81, 945–960 (1986).
- Meghanath, G. Beginner’s guide to causal discovery: The what, the why, and the how. (2024).
- Chernozhukov, V. et al. Double/debiased machine learning for treatment and causal parameters. (2024).
- O’Sullivan, R. De-biasing treatment effects with double machine learning. (2024).
- Keith Battocchi, M. H., Eleanor Dillon. EconML: A Python Package for ML-Based Heterogeneous Treatment Effects Estimation. (2019).
转自:我得学诚










