【导读】大家好,我是泳鱼。一个乐于探索和分享AI知识的码农!
在众多机器学习分类算法中,本篇我们提到的朴素贝叶斯,它是机器学习重要的算法之一。
在机器学习中如KNN、逻辑回归、决策树等模型都是判别方法,也就是直接学习出特征输出和特征之间的关系(决策函数或者条件分布)。但朴素贝叶斯是生成方法,它直接找出特征输出和特征的联合分布,进而通过计算得出结果判定。
朴素贝叶斯是一个非常直观的模型,在很多领域有广泛的应用,比如早期的文本分类,很多时候会用它作为 baseline 模型,本篇内容我们对朴素贝叶斯算法原理做展开介绍。
1.朴素贝叶斯算法核心思想
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯(Naive Bayes)分类是贝叶斯分类中最简单,也是常见的一种分类方法。
朴素贝叶斯算法的核心思想是通过考虑特征概率来预测分类,即对于给出的待分类样本,求解在此样本出现的条件下各个类别出现的概率,哪个最大,就认为此待分类样本属于哪个类别。

举个例子:眼前有100个西瓜,好瓜和坏瓜个数差不多,现在要用这些西瓜来训练一个『坏瓜识别器』,我们要怎么办呢?
一般挑西瓜时通常要『敲一敲』,听听声音,是清脆声、浊响声、还是沉闷声。所以,我们先简单点考虑这个问题,只用敲击的声音来辨别西瓜的好坏。根据经验,敲击声『清脆』说明西瓜还不够熟,敲击声『沉闷』说明西瓜成熟度好,更甜更好吃。

所以,坏西瓜的敲击声是『清脆』的概率更大,好西瓜的敲击声是『沉闷』的概率更大。当然这并不绝对——我们千挑万选地『沉闷』瓜也可能并没熟,这就是噪声了。当然,在实际生活中,除了敲击声,我们还有其他可能特征来帮助判断,例如色泽、跟蒂、品类等。
朴素贝叶斯把类似『敲击声』这样的特征概率化,构成一个『西瓜的品质向量』以及对应的『好瓜/坏瓜标签』,训练出一个标准的『基于统计概率的好坏瓜模型』,这些模型都是各个特征概率构成的。

这样,在面对未知品质的西瓜时,我们迅速获取了特征,分别输入『好瓜模型』和『坏瓜模型』,得到两个概率值。如果『坏瓜模型』输出的概率值大一些,那这个瓜很有可能就是个坏瓜。
2.贝叶斯公式与条件独立假设
贝叶斯定理中很重要的概念是先验概率、后验概率和条件概率。(关于这部分依赖的数学知识,大家可以查看ShowMeAI的文章 图解AI数学基础 | 概率与统计,也可以下载我们的速查手册 AI知识技能速查 | 数学基础-概率统计知识)(链接见文末)。
1)先验概率与后验概率
先验概率:事件发生前的预判概率。可以是基于历史数据的统计,可以由背景常识得出,也可以是人的主观观点给出。一般都是单独事件概率。
举个例子:如果我们对西瓜的色泽、根蒂和纹理等特征一无所知,按照常理来说,西瓜是好瓜的概率是60%。那么这个概率P(好瓜)就被称为先验概率。
后验概率:事件发生后求的反向条件概率。或者说,基于先验概率求得的反向条件概率。概率形式与条件概率相同。
举个例子:假如我们了解到判断西瓜是否好瓜的一个指标是纹理。一般来说,纹理清晰的西瓜是好瓜的概率大一些,大概是75%。如果把纹理清晰当作一种结果,然后去推测好瓜的概率,那么这个概率P(好瓜|纹理清晰)就被称为后验概率。
条件概率:一个事件发生后另一个事件发生的概率。一般的形式为表示发生的条件下发生的概率。

2)贝叶斯公式
简单来说,贝叶斯定理(Bayes Theorem,也称贝叶斯公式)是基于假设的先验概率、给定假设下观察到不同数据的概率,提供了一种计算后验概率的方法。在人工智能领域,有一些概率型模型会依托于贝叶斯定理,比如我们今天的主角『朴素贝叶斯模型』。
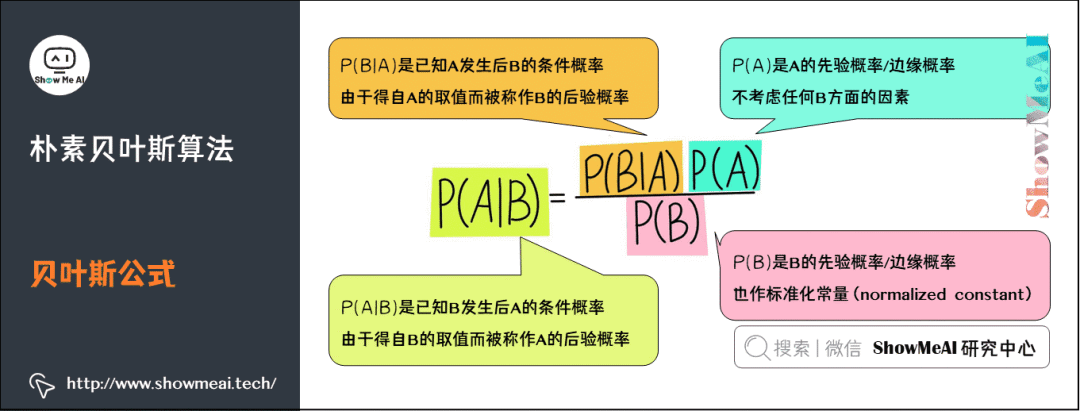
是先验概率,一般都是人主观给出的。贝叶斯中的先验概率一般特指它。
是先验概率,在贝叶斯的很多应用中不重要(因为只要最大后验不求绝对值),需要时往往用全概率公式计算得到。
是条件概率,又叫似然概率,一般是通过历史数据统计得到。
是后验概率,一般是我们求解的目标。
3)条件独立假设与朴素贝叶斯
基于贝叶斯定理的贝叶斯模型是一类简单常用的分类算法。在『假设待分类项的各个属性相互独立』的情况下,构造出来的分类算法就称为朴素的,即朴素贝叶斯算法。
所谓『朴素』,是假定所有输入事件之间是相互独立。进行这个假设是因为独立事件间的概率计算更简单。
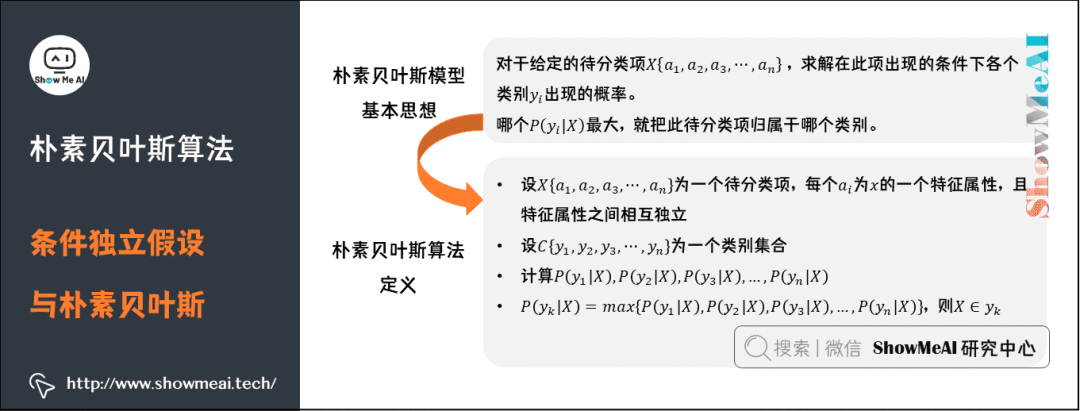
朴素贝叶斯模型的基本思想是:对于给定的待分类项 ,求解在此项出现的条件下各个类别出现的概率,哪个最大,就把此待分类项归属于哪个类别。
朴素贝叶斯算法的定义为:设 为一个待分类项,每个
为x的一个特征属性,且特征属性之间相互独立。设为一个类别集合,计算。
则
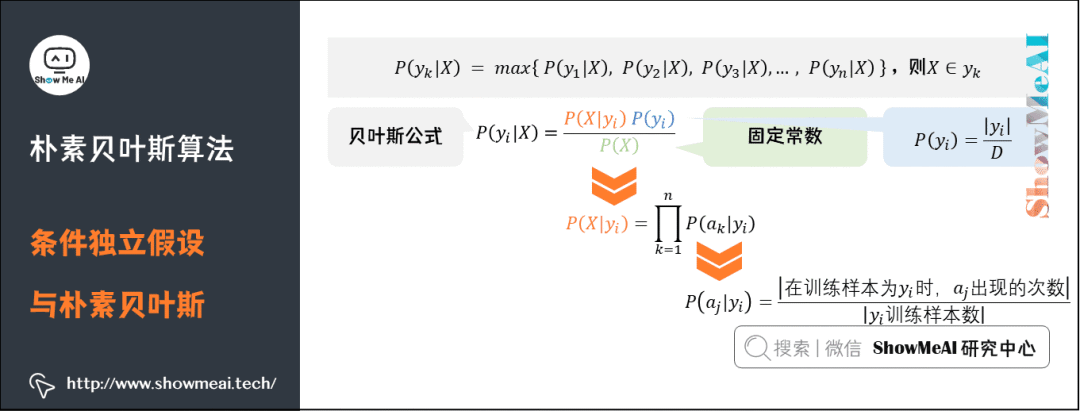
要求出第四项中的后验概率,就需要分别求出在第三项中的各个条件概率,其步骤是:
- 找到一个已知分类的待分类项集合,这个集合叫做训练样本集

在朴素贝叶斯算法中,待分类项的每个特征属性都是条件独立的,由贝叶斯公式
因为分母相当于在数据库中存在的概率,所以对于任何一个待分类项来说都是常数固定的。再求后验概率的时候只用考虑分子即可。
因为各特征值是独立的所以有:
可以推出:

对于是指在训练样本中出现的概率,可以近似的求解为:
对于先验概率,是指在类别中,特征元素出现的概率,可以求解为:
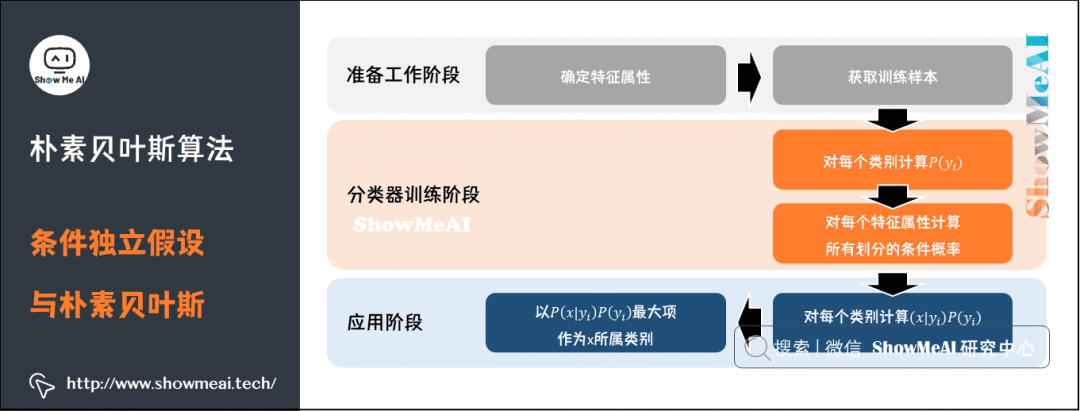
总结一下,朴素贝叶斯模型的分类过程如下流程图所示:
3.伯努利与多项式朴素贝叶斯
1)多项式vs伯努利朴素贝叶斯
大家在一些资料中,会看到『多项式朴素贝叶斯』和『伯努利朴素贝叶斯』这样的细分名称,我们在这里基于文本分类来给大家解释一下:
在文本分类的场景下使用朴素贝叶斯,那对应的特征就是单词,对应的类别标签就是,这里有一个问题:每个单词会出现很多次,我们对于频次有哪些处理方法呢?
- 如果直接以单词的频次参与统计计算,那就是多项式朴素贝叶斯的形态。
- 如果以是否出现(0和1)参与统计计算,就是伯努利朴素贝叶斯的形态。

(1)多项式朴素贝叶斯
以文本分类为例,多项式模型如下。在多项式模型中,设某文档,是该文档中出现过的单词,允许重复,则:
先验概率
类条件概率
- 是训练样本的单词表(即抽取单词,单词出现多次,只算一个),则表示训练样本包含多少种单词。
- 可以看作是单词在证明属于类上提供了多大的证据,而则可以认为是类别
在整体上占多大比例(有多大可能性)。
(2)伯努利朴素贝叶斯
对应的,在伯努利朴素贝叶斯里,我们假设各个特征在各个类别下是服从n重伯努利分布(二项分布)的,因为伯努利试验仅有两个结果,因此,算法会首先对特征值进行二值化处理(假设二值化的结果为1与0)。
对应的和计算方式如下(注意到分子分母的变化):
2)朴素贝叶斯与连续值特征
我们发现在之前的概率统计方式,都是基于离散值的。如果遇到连续型变量特征,怎么办呢?
以人的身高,物体的长度为例。一种处理方式是:把它转换成离散型的值。比如:
当然有不同的转换方法,比如还可以:
- 如果身高是160cm以下,这三个特征的值分别是1、0、0;
- 若身高在170cm之上,这三个特征的值分别是0、0、1。
但是,以上的划分方式,都比较粗糙,划分的规则也是人为拟定的,且在同一区间内的样本(比如第1套变换规则下,身高150和155)难以区分,我们有高斯朴素贝叶斯模型可以解决这个问题。
如果特征是连续变量,如何去估计似然度呢?高斯模型是这样做的:我们假设在的条件下,服从高斯分布(正态分布)。根据正态分布的概率密度函数即可计算出,公式如下:

回到上述例子,如果身高是我们判定人性别(男/女)的特征之一,我们可以假设男性和女性的身高服从正态分布,通过样本计算出身高均值和方差,对应上图中公式就得到正态分布的密度函数。有了密度函数,遇到新的身高值就可以直接代入,算出密度函数的值。
4.平滑处理
1)为什么需要平滑处理
使用朴素贝叶斯,有时候会面临零概率问题。零概率问题,指的是在计算实例的概率时,如果某个量,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。
在文本分类的问题中,当『一个词语没有在训练样本中出现』时,这个词基于公式统计计算得到的条件概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
2)拉普拉斯平滑及依据
为了解决零概率的问题,法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率,所以加法平滑也叫做拉普拉斯平滑。
假定训练样本很大时,每个分量x的计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。
对应到文本分类的场景中,如果使用多项式朴素贝叶斯,假定特征表示某个词在样本中出现的次数(当然用TF-IDF表示也可以)。拉普拉斯平滑处理后的条件概率计算公式为:

- 表示平滑值(,主要为了防止训练样本中某个特征没出现而导致,从而导致条件概率
的情况,如果不加入平滑值,则计算联合概率时由于某一项为0导致后验概率为0的异常情况出现。
教程地址:https://www.showmeai.tech/tutorials/34本文地址:https://www.showmeai.tech/article-detail/189





