复旦团队 投稿
量子位 | 公众号 QbitAI
视频扩散模型新综述来了,覆盖300+文献的那种。
最近,复旦大学、上海市智能视觉计算协同创新中心联合微软等学术机构,在国际顶级期刊《ACM Computing Surveys》(CSUR)上发表了题为《A Survey on Video Diffusion Models》的综述论文。
不仅系统地梳理了扩散模型在视频生成、编辑及理解等前沿领域的进展,还深入探讨了近期的研究趋势与突破,涵盖了该领域近年来的重要成果。
该研究目前已在Github揽获2k+ Star。
本篇综述论文的第一作者为复旦大学博士生邢桢,通讯作者为复旦大学吴祖煊副教授和姜育刚教授。

基于扩散模型的视频生成
本文将目前基于扩散模型的主流视频生成模型分为三大类:基于文本的视频生成,基于其他条件的视频生成,以及无条件的视频生成。
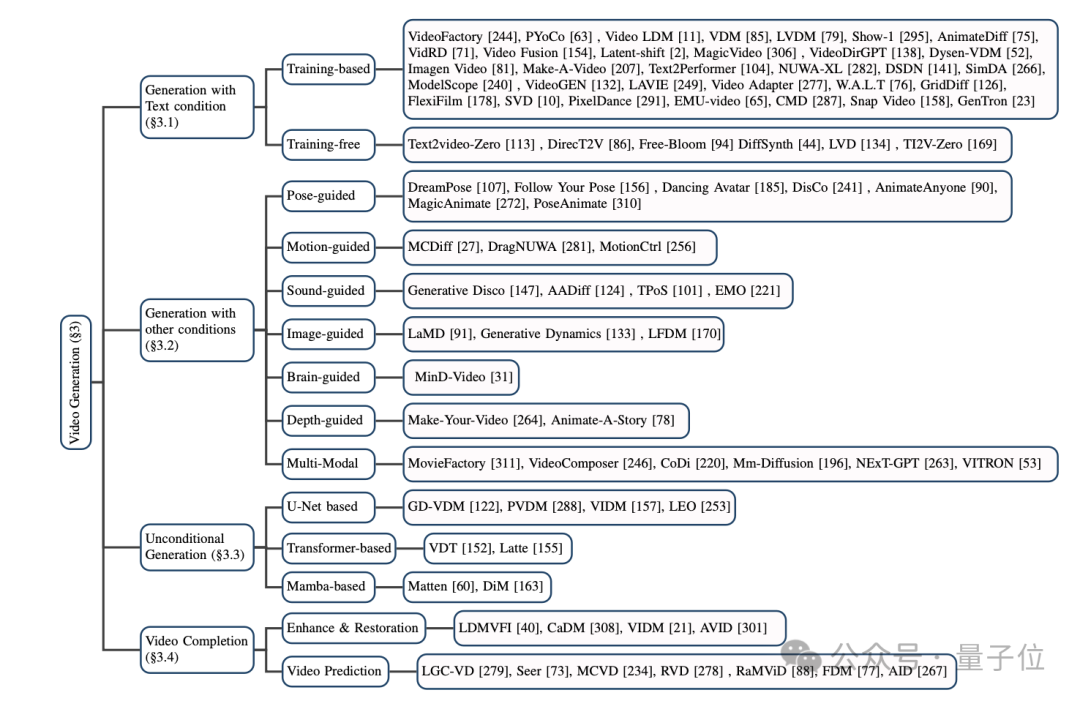
(1)基于文本的视频生成:
以自然语言为输入的视频生成是当前视频生成领域最重要的任务之一。
本文首先回顾了该领域在扩散模型提出之前的研究成果,随后分别介绍了基于训练和无需训练的两种扩散模型方法。
其中基于训练的方法通常依靠大规模数据集,通过优化模型性能实现高质量视频生成;而无训练的方法则主要借助文生图模型(T2I)和大语言模型(LLM)等技术实现视频生成。
(2)基于其他条件的视频生成:
该任务专注于细分领域的视频生成工作。本文将这些条件归类为以下几种:姿势引导(pose-guided)、动作引导(motion-guided)、声音引导(sound-guided)、图像引导(image-guided)、深度图引导(depth-guided)等。
这些工作不仅提供了比纯文本更为精准的控制条件,还将不同模态的信息融合到视频生成的过程中,极大地丰富了视频生成的技术手段和应用场景。
(3)无条件的视频生成:
该方向的研究主要围绕视频表征方式的设计与扩散模型网络架构设计展开,可以细分为基于U-Net的生成、基于Transformer的生成以及基于Mamba的生成。

基于扩散模型的视频编辑
对于基于扩散模型的视频编辑方法,本文同样将目前主流的模型分成了三大类:基于文本的视频编辑,基于其他条件的视频编辑,以及特定细分领域的视频编辑。
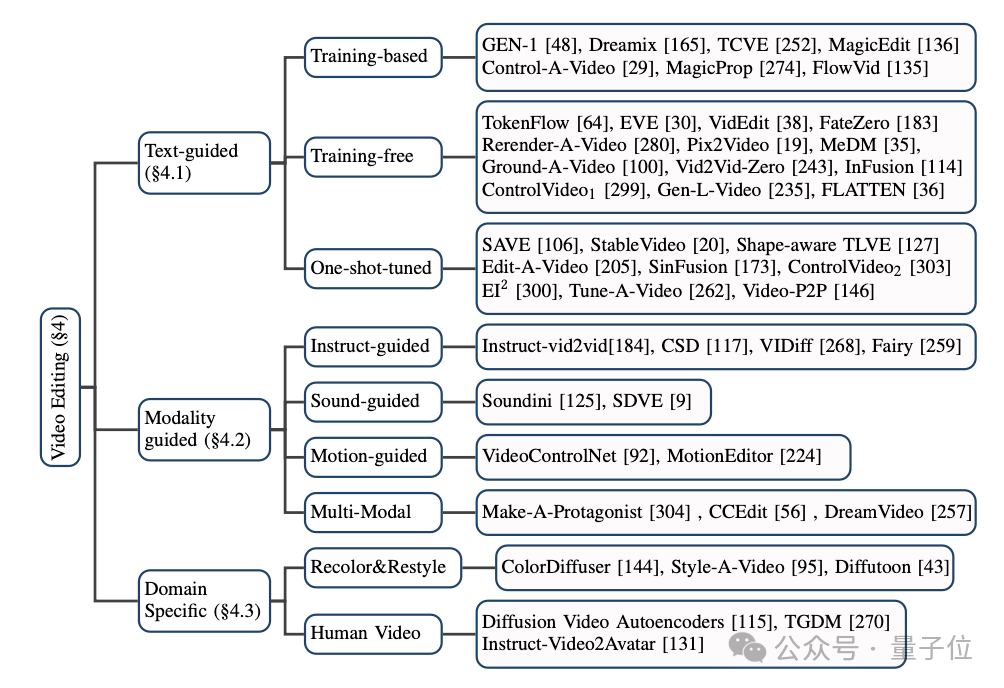
(1)基于文本的视频编辑:
由于目前文本-视频数据规模有限,大多数基于文本的视频编辑任务都倾向于利用预训练的T2I模型来解决视频帧之间的连贯性和语义不一致性等问题。
本文中,作者进一步将此类任务细分为基于训练的(training-based)、无需训练的(training-free)和一次性调优的(one-shot tuned)方法,并分别加以总结。
(2)基于其他条件的视频编辑:
随着大模型时代的到来,除了最为直接的自然语言信息作为条件的视频编辑,由指令、声音、动作、多模态等作为条件的视频编辑正受到越来越多的关注,作者也对相应的工作进行了分类梳理。
(3)特定细分领域的视频编辑:
在一些特定领域中,视频编辑任务往往具有独特的定制化需求。例如,视频着色和人像视频编辑等,这些任务针对特定场景提出了更加专门化的解决方案。
作者对相关研究成果进行了系统梳理,总结了这些领域的主要方法和实践经验。
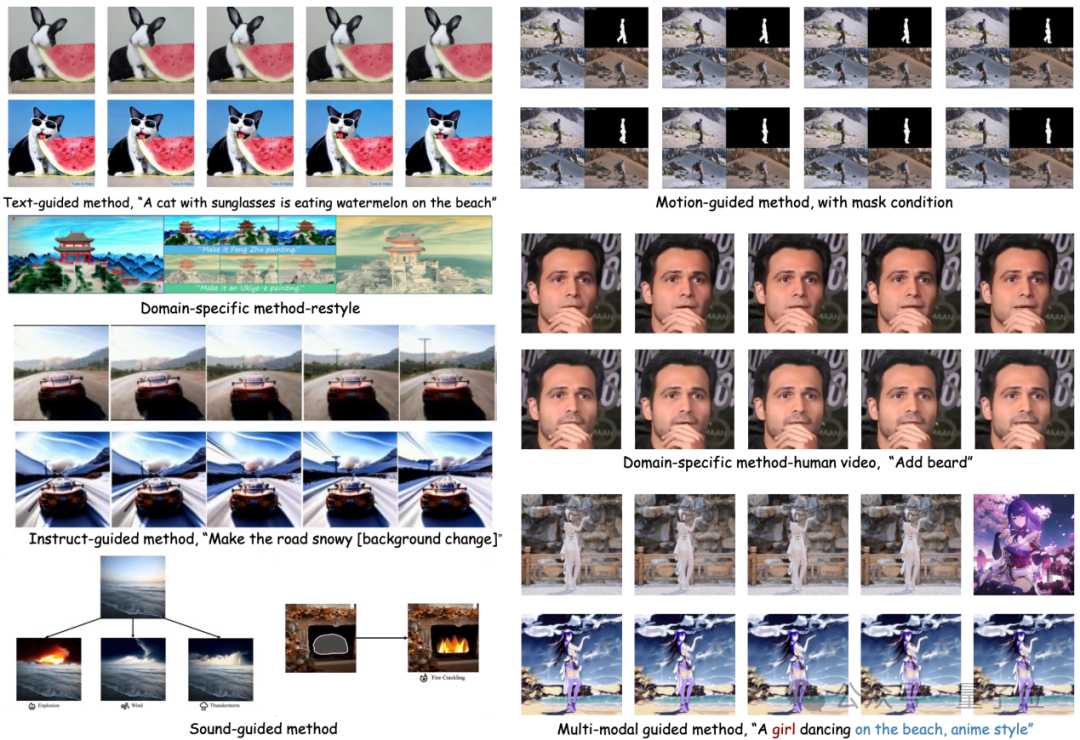
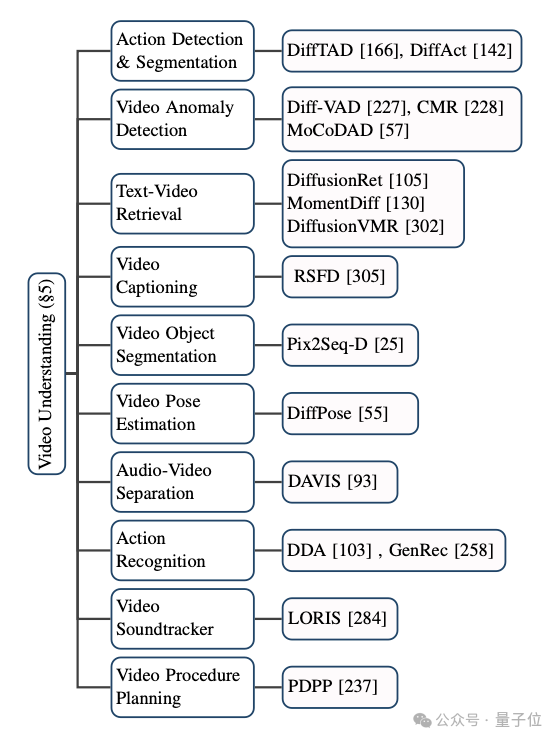
基于扩散模型的视频理解
扩散模型不仅在传统的视频生成和编辑任务中取得了广泛的应用,它在视频理解任务上也展现了出巨大的潜能。
通过对前沿论文的追踪,作者归纳了视频时序分割、视频异常检测、视频物体分割、文本视频检索、动作识别等多个现有的应用场景。
总结与展望

该综述全面细致地总结了AIGC时代下扩散模型在视频任务上的最新研究。
根据研究对象和技术特点,本文作者将百余份前沿工作进行了分类和概述,并在一些经典的基准(benchmark)上对这些模型进行比较。
然而,扩散模型在视频任务领域仍面临一些新的研究方向和挑战,具体包括:
(1)大规模文本-视频数据集的缺乏:
T2I模型的成功很大程度上得益于数以亿计的高质量文本-图像数据集,例如LAION-5B;该数据集包含了数十亿个图像-文本对,极大提升了模型的泛化能力。
相比之下,在T2V任务中,当前的数据集无论从规模上还是质量上都显得远远不足。例如常用的WebVid数据集,该数据集的视频不仅分辨率低(仅有360P),还常带有水印。
因此,未来的研究重点应该放在构建大规模、无水印、高分辨率的公开数据集上,同时提升数据集的标注质量和多样性,以更好地支持视频生成模型的训练。
(2)物理世界的真实性:
尽管现有的视频生成模型在许多场景中取得了令人瞩目的成果,但在复杂场景的物理世界描述上仍存在较大的局限性。
例如,Sora模型在生成涉及物理交互的视频时,仍不能很好地生成完全符合物理规律的视频。
作者指出,这些问题的根源在于当前模型对物理场景的理解仍较为浅显,缺乏对物体刚性、重力、摩擦力等物理属性的精确建模。
因此,未来的研究可以探索如何将物理学的规律嵌入到生成模型中,提升生成视频中的物理属性的合理性,从而使生成的视频更真实。
(3)长视频生成:
当前视频生成模型面临的一个显著挑战是视频长度的限制。大多数模型只能生成时长不超过10秒的视频内容。
这主要是因为长视频生成不仅对计算资源提出了更高要求,还要求模型能够有效建模时空连贯性。而现有的自回归模型中,时序误差累积问题尤为突出。
此外,尽管现有的分阶段生成方法(如粗到细的多阶段生成)能够在一定程度上改善生成效果,但却往往带来更复杂的训练和推理过程,导致生成速度变慢。
因此,未来的研究方向应致力于开发更高效、更稳定的长视频生成方法,确保视频在较长时间段内既保持物理合理性又不失质量稳定性。
(4)高效的训练和推理:
T2V模型的训练和推理过程涉及到海量的视频数据,在训练和推理阶段所需要的算力也呈几何倍数增加,成本极高。
因此,未来的研究应当致力于通过改进模型架构,例如采用更高效的时空建模方法,或通过知识蒸馏等技术来压缩模型的大小,减少训练和推理过程中的计算复杂度,从而降低视频生成的总体成本。
(5)可靠的基准和评价指标:
现有视频领域的评价指标主要集中在衡量生成视频与原视频之间的分布差异,但未能全面评估生成视频的整体质量。
同时,用户测试作为重要的评估方式之一,既耗时费力又具有较强的主观性。
因此,未来的研究需要致力于研发更加客观、全面的自动化评价指标,既能衡量生成视频的视觉质量,也能捕捉到其物理真实性和时空一致性。
(6)高可控性的视频编辑:
目前大多数的视频生成模型主要依赖文本描述来进行视频编辑。然而,文本描述往往较为抽象,难以提供精确的控制。
例如,在涉及生成特定物体的移动轨迹、控制多个物体之间的交互等动态编辑任务时,现有方法仍然存在较大的局限性。
此外,对于复杂场景中的多物体编辑,生成模型也难以保持多个物体的时空一致性。
因此,未来的研究方向应当着力于提高视频编辑的可控性,例如通过结合视频分割、目标检测等技术,使得模型能够在视频的局部区域中执行更加精细的编辑操作,并提升在多物体场景下的动态编辑能力,从而实现更为灵活和精确的生成与编辑。
论文链接:https://arxiv.org/abs/2310.10647
论文主页:https://github.com/ChenHsing/Awesome-Video-Diffusion-Models
投稿请工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!









