
对机器学习深度学习来说每个算法就像工匠工具箱里的工具——我们需要知道何时以及如何使用它,所以有一份算法速查表是非常有必要的。
算法及其故事
每个算法都有其优势、劣势和独特之处,让我们深入了解一些基本算法:
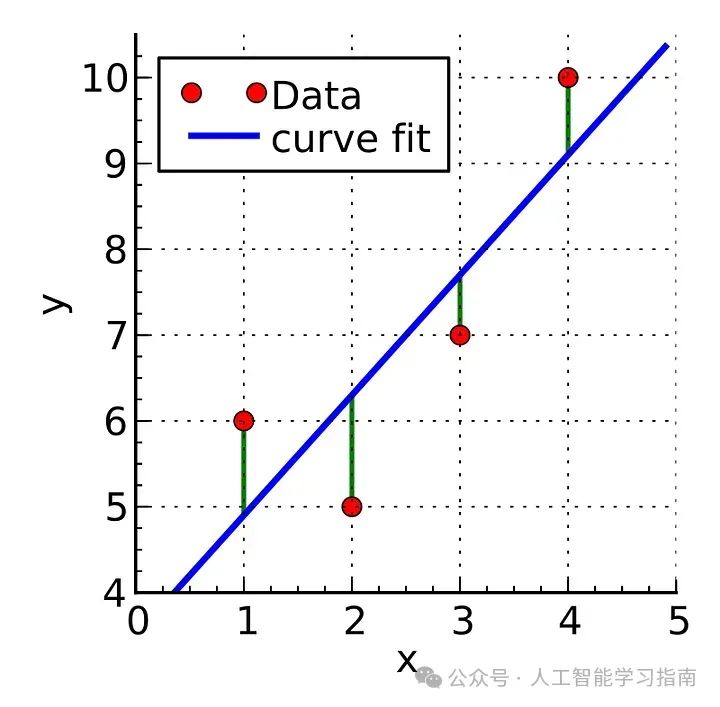
线性回归:入门工具
线性回归就像你学会骑的第一辆自行车,非常适合处理具有线性关系的数据。
适用场景:目标变量是连续的,且关系看似线性。
避免场景:存在非线性关系或多重共线性。
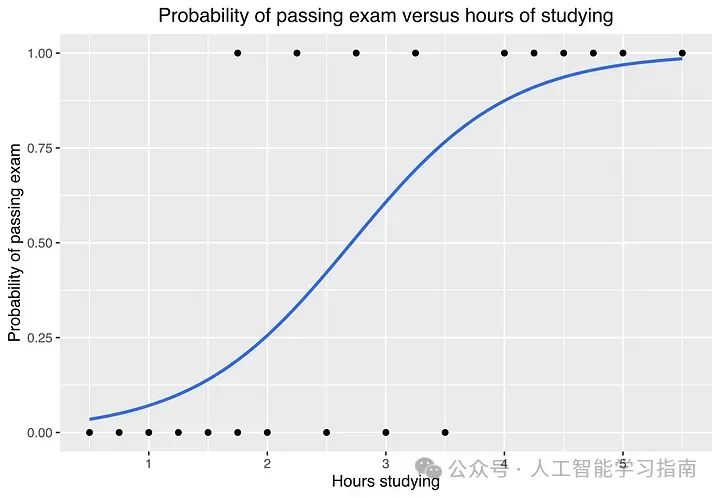
逻辑回归:守门人
当需要将电子邮件分类为垃圾邮件或非垃圾邮件时,逻辑回归就派上了用场。它就像友好的守卫,决定谁可以进入。
适用场景:处理二分类问题。
避免场景:数据具有复杂、非线性的模式。
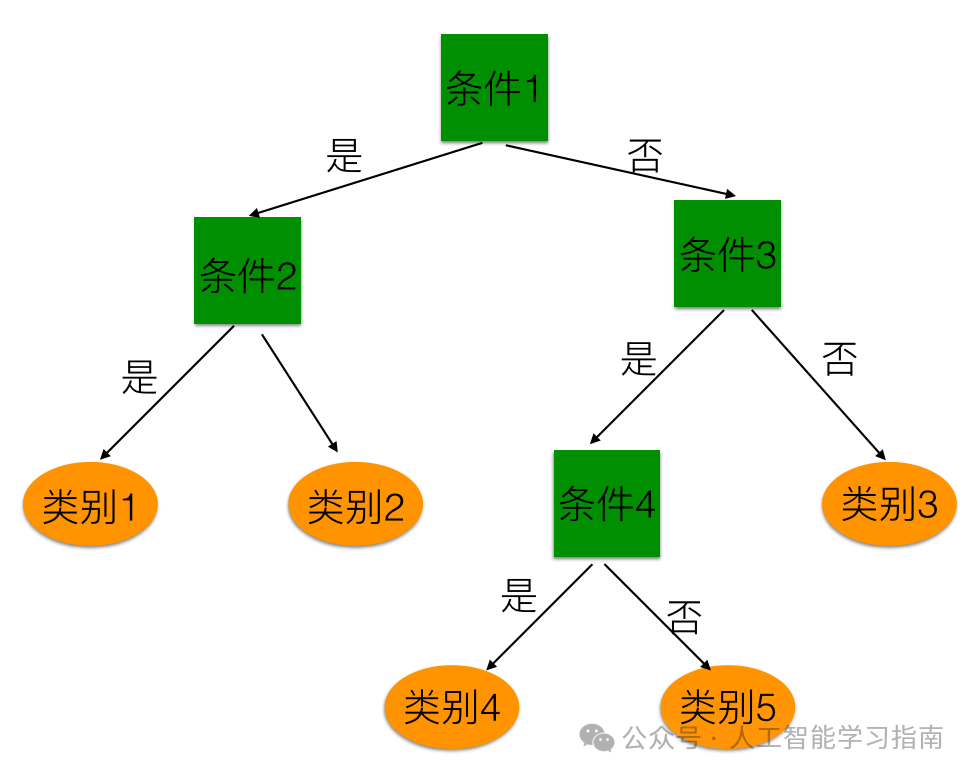
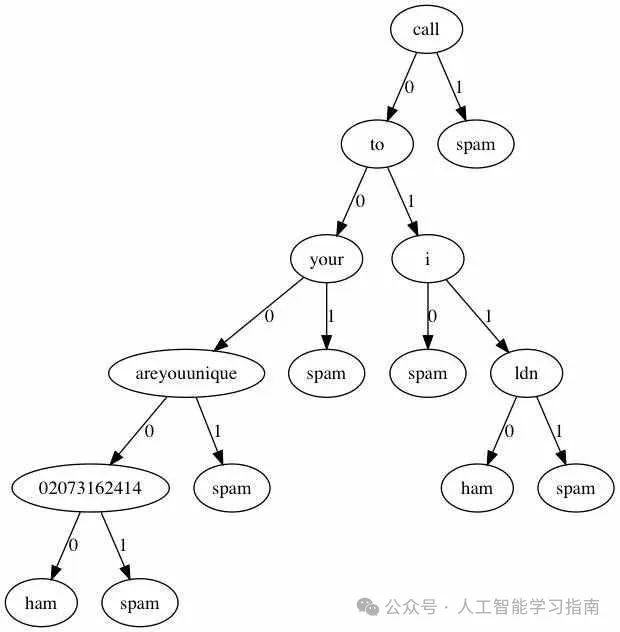
决策树:流程图大师
决策树就像是一位数据侦探,通过一系列线索来解开数据的谜团。
适用场景:需要一个易于解释的模型。
避免场景:出现过拟合问题(尽管剪枝有助于缓解)。
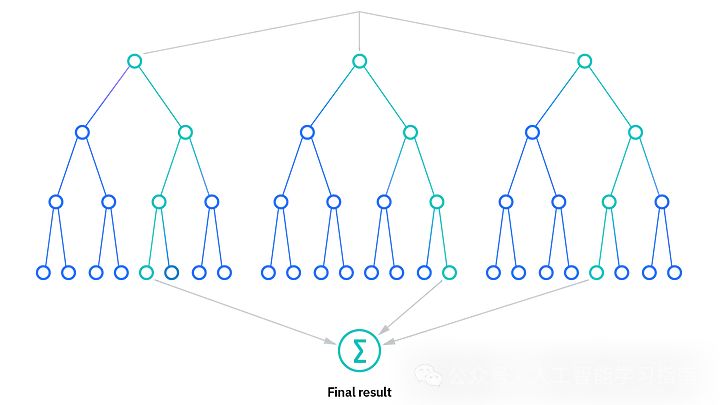
随机森林:可靠的集成方法
当决策树开始过于激进时,随机森林的作用就体现出来了。它就像咨询多位专家,而不是依赖一个人。
适用场景:在分类和回归任务上都需要稳健的性能。
避免场景:计算资源有限。
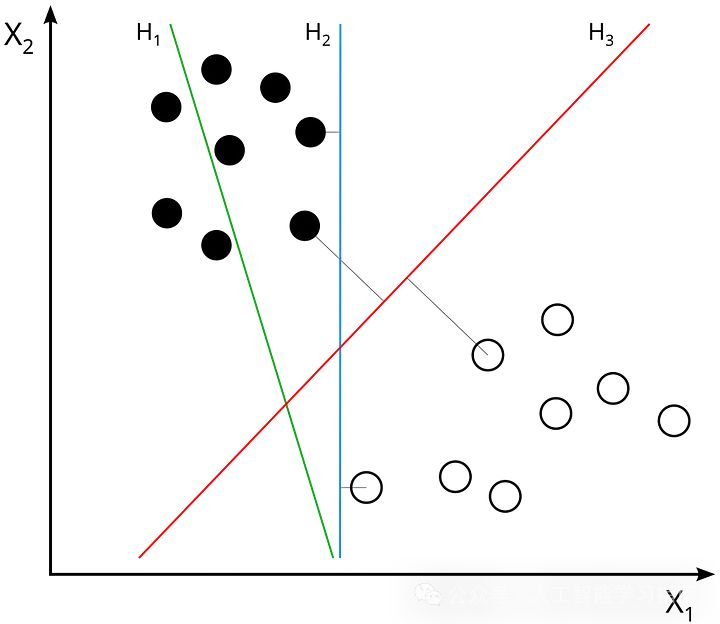
支持向量机(SVM):边界设定者
SVM作为一种较为复杂的机器学习算法,初学者可能会因为其背后的数学原理和参数调整而感到困惑。
但是一旦理解了SVM用清晰边界分隔类别的能力,即其通过找到能够将不同类别数据点最大化分隔的超平面(或决策边界),就会被其强大的分类能力所吸引。
适用场景:处理小到中型数据集。
避免场景:数据集庞大或噪声点过多。
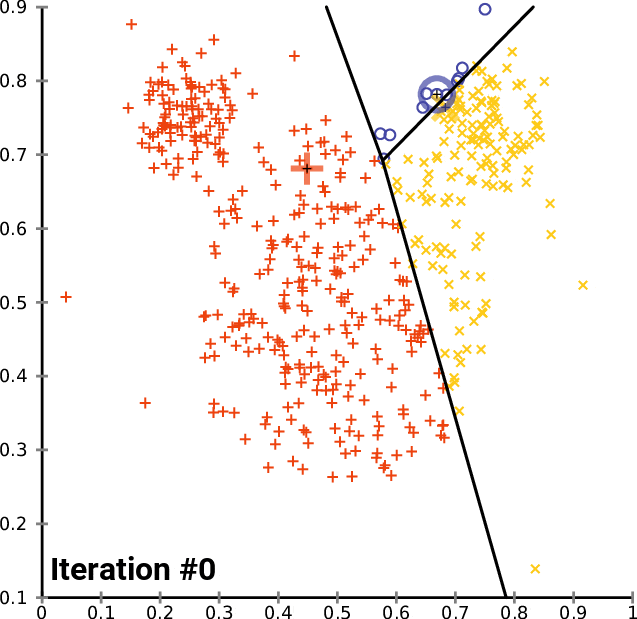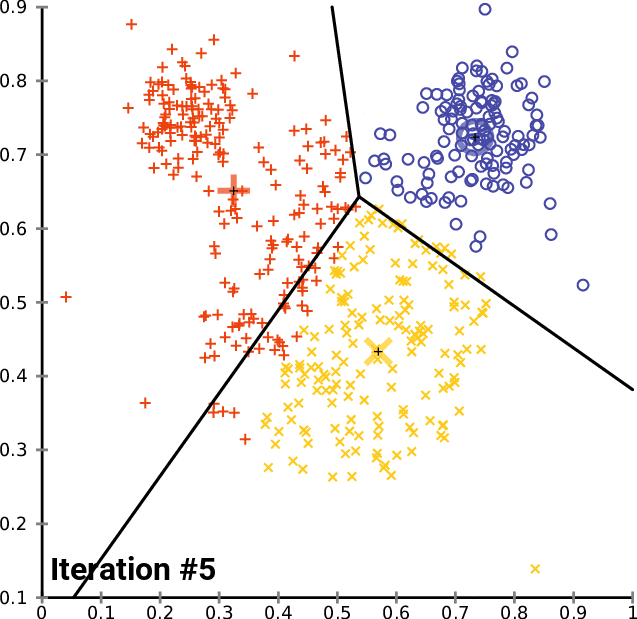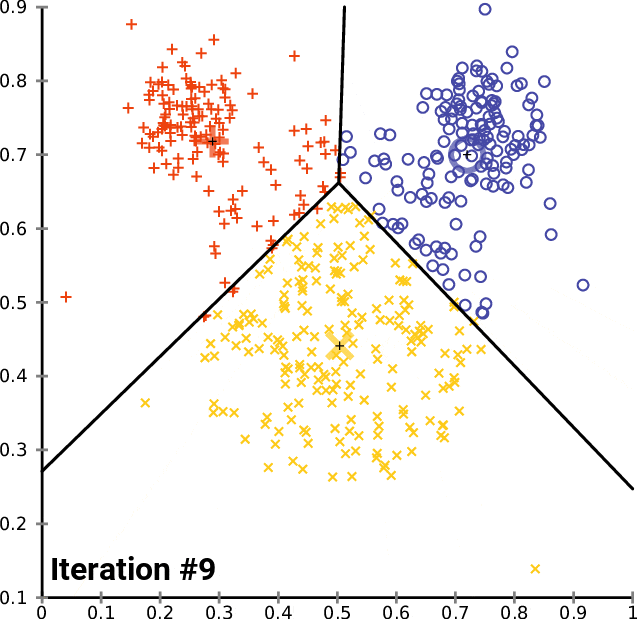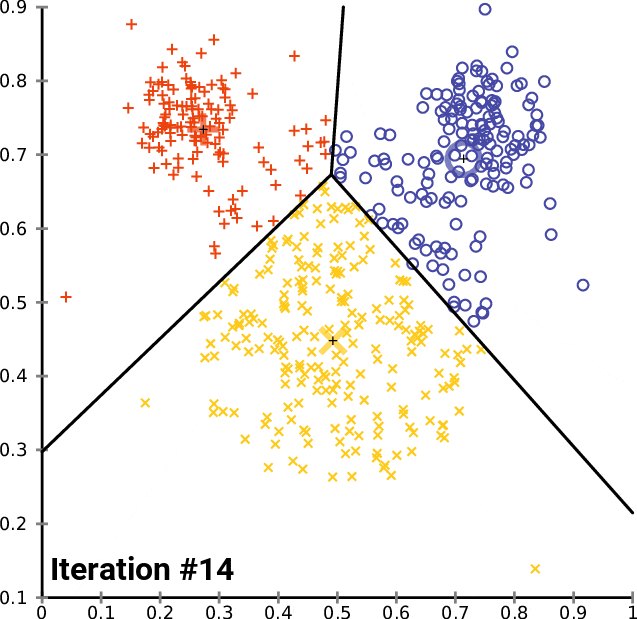
K均值聚类:模式发现者
像K均值这样的聚类算法能够在事先不知道客户是谁的情况下将他们分组。这就是聚类的魅力。
适用场景:在未标记数据中寻找模式。
避免场景:聚类不是球形或大小不均匀。
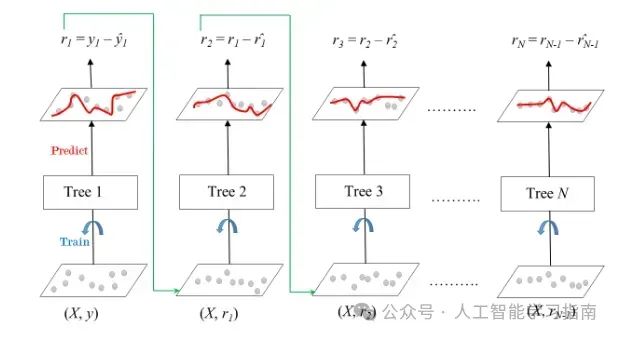
梯度提升(XGBoost、LightGBM):竞赛之王
在Kaggle竞赛里,这是你想要获胜时会选择的算法。
适用场景:需要高精度。
避免场景:时间紧迫,无法调整超参数。
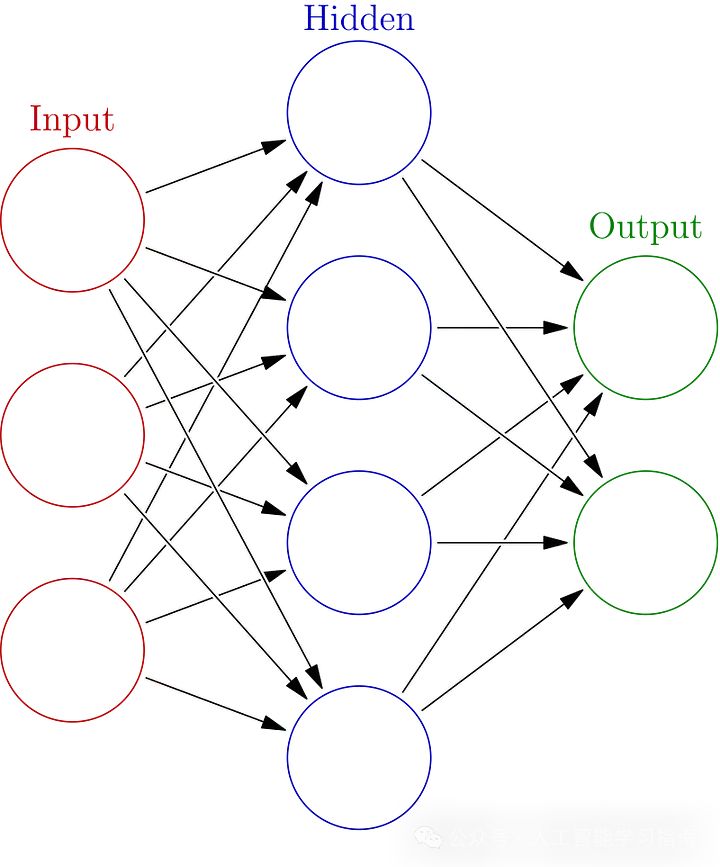
神经网络:深度思考者
适用场景:处理图像识别、自然语言处理或其他复杂任务。
避免场景:数据集较小或缺乏计算能力。
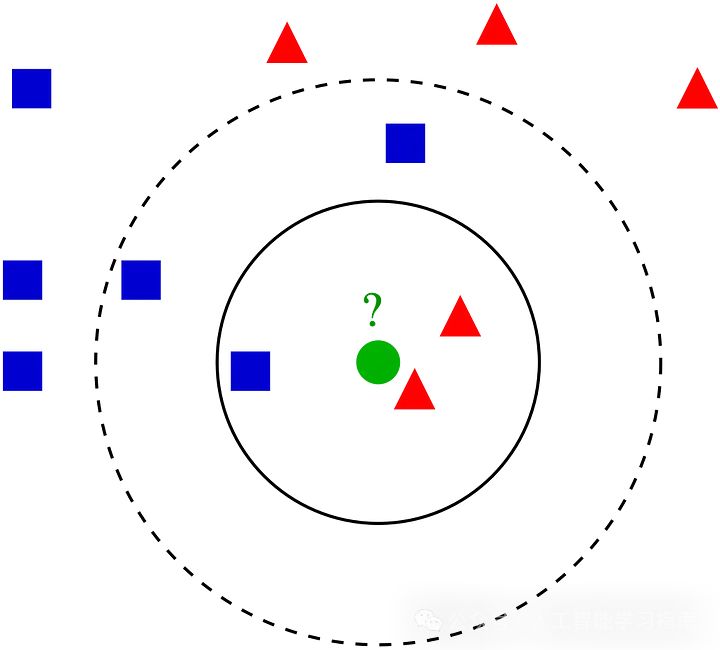
K最近邻(KNN):懒惰学习者
适用场景:简单性和可解释性是关键。
避免场景:数据集庞大或高维。
朴素贝叶斯:假设制造者
朴素贝叶斯可能会假设你的特征是独立的,但它在文本分类任务中仍然表现出色。
适用场景:处理高维数据,如文本或电子邮件。
避免场景:数据不满足独立性假设。
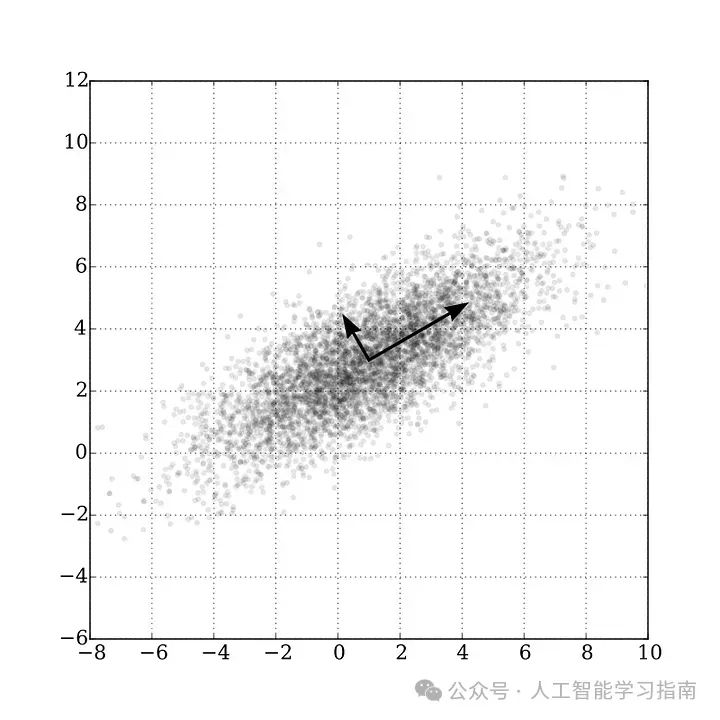
主成分分析(PCA):降维专家
当数据集变得过于庞大时,PCA在减少混乱的同时还保留了本质。
适用场景:简化高维数据。
避免场景:可解释性至关重要。
选择算法的秘诀
从简单开始:从线性回归或决策树等基本算法开始,复杂的并不总是最好的。
了解你的数据:越了解数据集的结构,就越能选择合适的工具。
实验:尝试多种算法,并使用交叉验证进行评估,让结果引导你。
不要跳过预处理:输入垃圾,输出垃圾,始终清理和预处理数据。
明智地使用库:Scikit-learn、TensorFlow和PyTorch等工具是必不可少的。
结语
算法不仅仅是数学——它们是数据科学的核心,每个算法都有其特色、优势和劣势,关键是知道何时以及使用哪个算法。
我们精心打磨了一套基于数据与模型方法的 AI科研入门学习方案(已经迭代过5次),对于人工智能来说,任何专业,要处理的都只是实验数据,所以我们根据实验数据将课程分为了三种方向的针对性课程,包含时序、图结构、影像三大实验室,我们会根据你的数据类型来帮助你选择合适的实验室,根据规划好的路线学习 只需 5 个月左右(很多同学通过学习已经发表了 sci 二区及以下、ei会议等级别论文)学习形式为 直播+ 录播,多位老师为你的论文保驾护航,如果需要发高区也有其他形式。

大家感兴趣可以直接添加小助手微信:ai0808q 通过后回复咨询既可!

大家想自学的我还给大家准备了一些机器学习、深度学习、神经网络资料大家可以看看以下文章(文章中提到的资料都打包好了,都可以直接添加小助手获取)
大家觉得这篇文章有帮助的话记得分享给你的死党、闺蜜、同学、朋友、老师、敌蜜!










