
今天这篇文章将带大家在不用任何库,和使用numpy两种方式从零构建一个神经网络,从零构建神经网络不仅能加深大家对神经网络的理解,还能提升编程能力。
在这个过程大家会遇到许多问题,解决这些问题并成功创建出一个神经网络基本就算是入门了。
为了让大家可以更系统的学习人工智能(机器学习、深度学习、神经网络),小墨学长还为大家整理了一份60天入门人工智能机器学习、深度学习、神经网络)的学习路线,从基础到进阶都包含在内,希望可以帮助到大家。
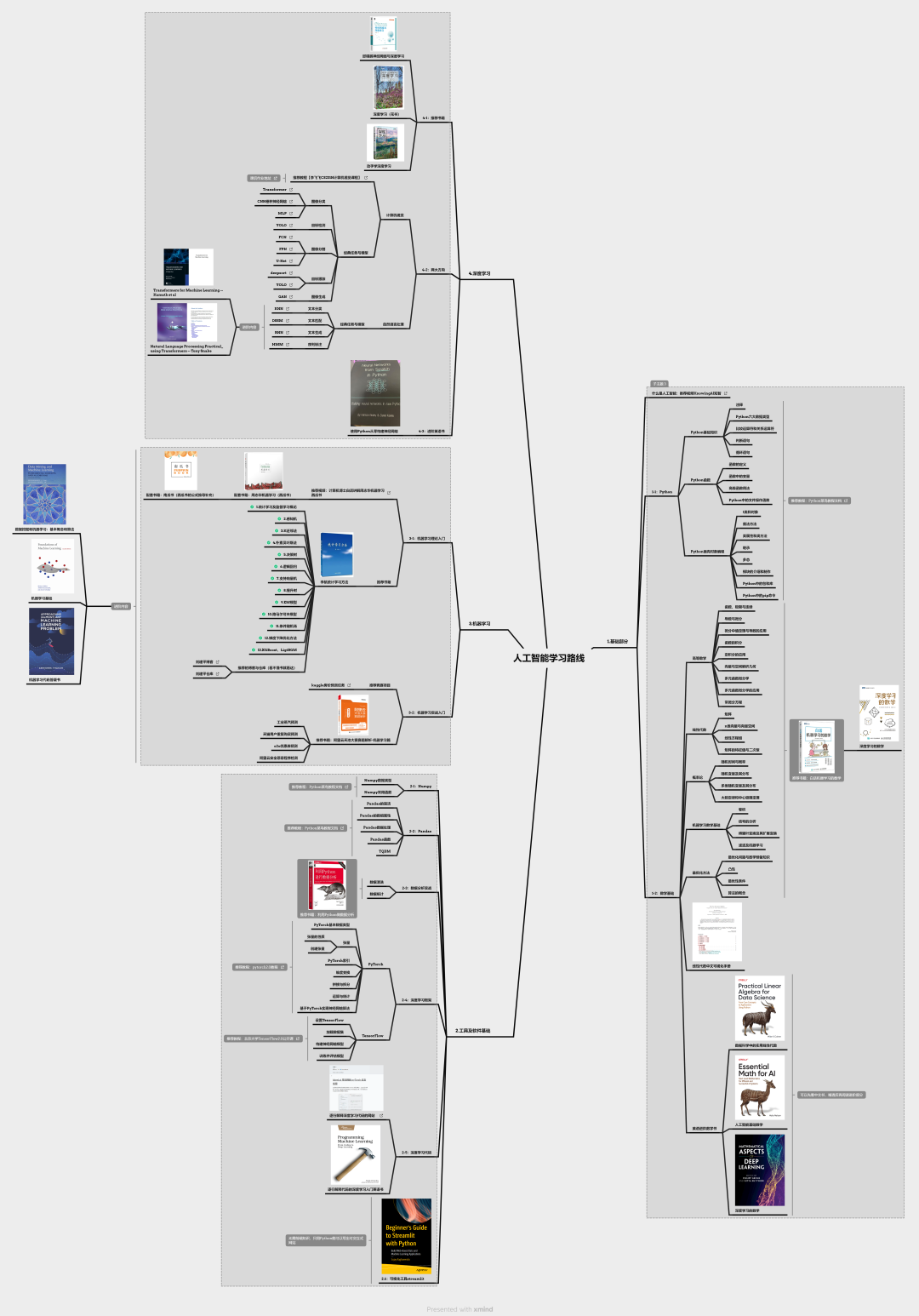
学习路线的资料都下载打包好了
大家可以添加小助手让她把学习路线的思维导图和相关资料一起发给你


不借助外部库构建神经网络
我们将在不借助外部库(如numpy、PyTorch或Tensorflow)的情况下从零构建一个神经网络。
首先,我们来定义两个函数,分别是sigmoid激活函数及其导数,这两个函数将在整个练习过程中重复使用。
from math import exp
def sigmoid(x: float) -> float: """ Sigmoid激活函数 :param x: 输入值,类型为float :return: Sigmoid函数的输出值,范围在(0, 1)之间 """ return 1.0 / (1.0 + exp(-x))
def sigmoid_derivative(z: float) -> float: """ Sigmoid函数的导数 :param z: Sigmoid函数的输出值,类型为float :return: Sigmoid函数的导数值 """ return z * (1.0 - z)
接下来,我们为神经元构建一个类:
权重(weights):神经元接收输入信号,每个信号都关联一个权重。这些权重决定了每个输入的重要性。
偏置(bias):类似于线性方程中的截距,偏置允许神经元独立于输入调整其输出。
误差项(delta):在反向传播过程中用于调整权重(你会发现之前教程中的知识已经融入我们的代码中)。它表示相对于加权和的误差导数。
输出(output):神经元激活函数的结果。
sigmoid函数为模型引入了非线性,使其能够学习复杂的模式。
from dataclasses import dataclass from typing import List, Optional
from
math_utils import sigmoid, sigmoid_derivative
@dataclassclass Neuron: """ 神经元类,表示神经网络中的一个神经元 """ weights: List[float] bias: float delta: Optional[float] = 0.0 output: Optional[float] = 0.0
def _set_output(self, output: float) -> None: """ 设置神经元的输出值 :param output: 神经元的输出值 """ self.output = output
def set_delta(self, error: float) -> None: """ 设置神经元的误差项(delta) :param error: 误差值 """ self.delta = error * sigmoid_derivative(self.output)
def weighted_sum(self, inputs: List[float]) -> float: """ 计算加权和(即输入信号与权重的点积,加上偏置) :param inputs: 输入信号列表 :return: 加权和结果 """ ws = self.bias for i in range(len(self.weights)): ws += self.weights[i] * inputs[i] return ws
def activate(self, inputs: List[float]) -> float: """ 激活神经元,计算神经元的输出值 :param inputs: 输入信号列表 :return: 神经元的输出值(经过Sigmoid激活函数处理) """ output = sigmoid(self.weighted_sum(inputs)) self._set_output(output) return output
神经元随后被组织成层——这就是层类。
层将神经元组织成有意义的组,同一层中的神经元具有相同的输入和输出维度。
from dataclasses import dataclass from typing import List, Optional
@dataclassclass Layer: """ 神经网络层类,表示神经网络中的一层 """ neurons: List[Neuron]
@property def all_outputs(self) -> List[float]: """ 获取该层所有神经元的输出值 :return: 所有神经元的输出值列表 """ return [neuron.output for neuron in self.neurons]
def activate_neurons(self, inputs: List[float]) -> List[float]: """ 激活该层中的所有神经元,计算每个神经元的输出值 :param inputs: 输入信号列表 :return: 所有神经元的输出值列表 """ return [neuron.activate(inputs) for
neuron in self.neurons]
def total_delta(self, previous_layer_neuron_idx: int) -> float: """ 计算该层神经元对前一层的某个神经元的误差贡献总和 :param previous_layer_neuron_idx: 前一层中某个神经元的索引 :return: 该层神经元对前一层某个神经元的误差贡献总和 """ return sum( neuron.weights[previous_layer_neuron_idx] * neuron.delta for neuron in self.neurons )
现在,大部分逻辑都在网络类中。它代表神经网络本身,并协调其训练和预测过程。
关键属性:
隐藏层(hidden_layers):包含隐藏层的列表,每个隐藏层由层类表示。
输出层(output_layer):网络的输出层,也由层类表示。
学习率(learning_rate):一个超参数,确定训练过程中每次迭代的步长。
关键函数:
前向传播(feed_forward):执行前向传播,按顺序激活每个神经元,从接收输入开始,通过隐藏层到达输出层。
反向传播(back_propagate):执行反向传播算法,计算并更新每层神经元的误差项。然后调用update_weights_for_all_layers函数在误差项计算完成后更新权重。
训练(train):使用提供的训练集和期望输出对神经网络进行指定次数的迭代训练。期望输出列表使用独热编码来表示期望输出。
from dataclasses import dataclass from typing import List, Optional
@dataclassclass Network: """ 神经网络类,表示一个完整的神经网络 """ hidden_layers: List[Layer] output_layer: Layer learning_rate: float
@property def layers(self) -> List[Layer]: """ 获取所有层(隐藏层 + 输出层) :return: 所有层的列表 """ return self.hidden_layers + [self.output_layer]
def feed_forward(self, inputs: List[float]) -> List[float]: """ 前向传播:计算神经网络的输出 :param inputs: 输入信号列表 :return: 输出层的输出值列表 """ for layer in self.hidden_layers: inputs = layer.activate_neurons(inputs) return self.output_layer.activate_neurons(inputs)
def derivative_error_to_output( self, actual: List[float], expected: List[float] ) -> List[float]: """ 计算误差函数对输出的导数(即误差值)
:param actual: 实际输出值列表 :param expected: 期望输出值列表 :return: 误差值列表 """ return [actual[i] - expected[i] for i in range(len(actual))]
def back_propagate(self, inputs: List[float], errors: List[float]) -> None: """ 反向传播:计算梯度并更新权重 :param inputs: 输入信号列表 :param errors: 误差值列表 """ for index, neuron in enumerate(self.output_layer.neurons): neuron.set_delta(errors[index])
for layer_idx in reversed(range(len(self.hidden_layers))): layer = self.hidden_layers[layer_idx] next_layer = ( self.output_layer if layer_idx == len(self.hidden_layers) - 1 else self.hidden_layers[layer_idx + 1] ) for neuron_idx, neuron in enumerate(layer.neurons): error_from_next_layer = next_layer.total_delta(neuron_idx) neuron.set_delta(error_from_next_layer)
self.update_weights_for_all_layers(inputs)
def update_weights_for_all_layers(self, inputs: List[float]): """ 更新所有层的权重 :param inputs: 输入信号列表 """ for layer_idx in range(len(self.hidden_layers)): layer = self.hidden_layers[layer_idx] previous_layer_outputs: List[float] = ( inputs if layer_idx == 0 else self.hidden_layers[layer_idx - 1].all_outputs ) for neuron in layer.neurons: self.update_weights_in_a_layer(previous_layer_outputs, neuron)
for index, neuron in enumerate(self.output_layer.neurons): self.update_weights_in_a_layer(self.hidden_layers[-1].all_outputs, neuron)
def update_weights_in_a_layer( self, previous_layer_outputs: List[float], neuron: Neuron ) -> None: """ 更新某一层中神经元的权重 :param previous_layer_outputs: 前一层的输出值列表 :param neuron: 当前神经元 """ for idx in range(len(previous_layer_outputs)): neuron.weights[idx] -= ( self.learning_rate * neuron.delta * previous_layer_outputs[idx] ) neuron.bias -= self.learning_rate * neuron.delta
def train( self, num_epoch: int, num_outputs: int, training_set: List[List[float]], training_output: List[float], ) -> None: """ 训练神经网络 :param num_epoch: 训练轮数 :param num_outputs: 输出层神经元数量 :param training_set: 训练数据集 :param training_output: 训练集的期望输出 """ for epoch in range(num_epoch): sum_error = 0.0 for idx, row in enumerate(training_set):
expected = [0 for _ in range(num_outputs)] expected[training_output[idx]] = 1 actual = self.feed_forward(row) errors = self.derivative_error_to_output(actual, expected) self.back_propagate(row, errors) sum_error += self.mse(actual, training_output) print(f"Mean squared error: {sum_error}") print(f"epoch={epoch}")
def predict(self, inputs: List[float]) -> int: """ 预测输入数据的类别 :param inputs: 输入信号列表 :return: 预测的类别索引 """ outputs = self.feed_forward(inputs) return outputs.index(max(outputs))
def mse(self, actual: List[float], expected: List[float]) -> float: """ 计算均方误差(Mean Squared Error) :param actual: 实际输出值列表 :param expected: 期望输出值列表 :return: 均方误差值 """ return sum((actual[i] - expected[i]) ** 2 for i in range(len(actual))) / len( actual )
现在,让我们尝试在一些示例数据上运行这段代码,我复用了下面教程中的数据。
https://machinelearningmastery.com/implement-backpropagation-algorithm-scratch-python/
这个函数创建了一个示例数据集,并用1个隐藏层(包含2个神经元)和1个输出层(包含2个神经元)初始化网络。
然后,以0.5的学习率进行40次迭代训练,神经元的权重最初是随机的,并在训练过程中更新。
from random import random
def test_make_prediction_with_network(): """ 测试神经网络的预测功能 测试数据来自:https://machinelearningmastery.com/implement-backpropagation-algorithm-scratch-python/ """ dataset = [ [2.7810836, 2.550537003], [1.465489372, 2.362125076], [3.396561688, 4.400293529], [1.38807019, 1.850220317], [3.06407232, 3.005305973], [7.627531214, 2.759262235], [5.332441248, 2.088626775], [6.922596716, 1.77106367], [8.675418651, -0.242068655], [7.673756466, 3.508563011], ] expected = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
n_inputs = len(dataset[0]) n_outputs = len(set(expected))
hidden_layers = [ Layer( neurons=[ Neuron(weights=[random() for _ in range(n_inputs)], bias=random()), Neuron(weights=[random() for _ in range(n_inputs)], bias=random()), ], ) ]
output_layer = Layer( neurons=[ Neuron(weights=[random() for _ in range(n_outputs)], bias=random()), Neuron(weights=[random() for _ in range(n_outputs)], bias=random()), ], )
network = Network( hidden_layers=hidden_layers, output_layer=output_layer, learning_rate=0.5 )
network.train(40, n_outputs, dataset, expected)
print(f"Hidden layer: {network.layers[0].neurons}") print(f"Output layer: {network.layers[1].neurons}")
for i in range(len(dataset)): prediction = network.predict(dataset[i]) print("Expected=%d, Got=%d" % (expected[i], prediction))
if __name__ == "__main__": test_make_prediction_with_network()
如果你运行代码,应该会得到类似这样的结果:
Mean squared error: 3.694643563407745epoch=35Mean squared error: 3.715320273531503epoch=36Mean squared error: 3.7351519986813067epoch=37Mean squared error: 3.7541891932363085epoch=38Mean squared error: 3.7724787370507626epoch=39Hidden layer: [Neuron(weights=[-1.7955933584377923, 2.220092841757106], bias=1.8524769105456214, delta=0.002182774980130993, output=0.017002472895501414), Neuron(weights=[0.5655470895183494, 0.8333988388792425], bias=0.5754237549378755, delta=-9.918560351822408e-06, output=0.9996060780350633)]Output layer: [Neuron(weights=[3.8411067437736643, -0.4041378519239978], bias=-1.5094301066916858, delta=0.01664824516519805, output=0.1390584545931915), Neuron(weights=[-3.720465278381908, 1.0472187398270083], bias=0.8199129397405343, delta=-0.01791378414621278, output=0.855276011536201)]Expected=0, Got=0Expected=0, Got=0Expected=0, Got=0Expected=0, Got=0Expected=0, Got=0Expected=1, Got=1Expected=1, Got=1Expected=1, Got=1Expected=1, Got=1Expected=1, Got=1
以上就是不借助外部库构建神经网络的过程,但是这个代码显然既冗长又复杂——让我们尝试使用numpy来简化它!
使用numpy构建神经网络
上面我们已经熟悉了网络的流程,所以我将一次性给出所有代码:
from __future__ import annotations from dataclasses import dataclass from typing import Optional, List import numpy as np
def sigmoid(x): """ Sigmoid激活函数 :param x: 输入值 :return: Sigmoid函数的输出值,范围在(0, 1)之间 """ return 1 / (1 + np.exp(-x))
def sigmoid_derivative(z: float) -> float: """ Sigmoid函数的导数 :param z: Sigmoid函数的输出值 :return: Sigmoid函数的导数值 """ return z * (1.0 - z)
@dataclassclass Layer: """ 神经网络层类,表示神经网络中的一层 """ weights: np.array bias: np.array outputs: np.array deltas: np.array
@dataclassclass Network: """ 神经网络类,表示一个完整的神经网络 """ layers: List[Layer] learning_rate: Optional[int] = 0.5
@property def length(self) -> int: """ 获取神经网络的层数 :return: 层数 """ return len(self.layers)
@property def outputs(self) -> np.array: """ 获取输出层的输出值 :return: 输出层的输出值 """ return self.layers[-1].outputs
@staticmethod def create(layers: List[int]) -> Network: """ 创建一个神经网络,随机初始化权重和偏置 :param layers: 每层的神经元数量列表,例如[2, 3, 2]表示输入层2个神经元,隐藏层3个神经元,输出层2个神经元 :return: 创建的神经网络 """ layers = [ Layer( weights=np.random.rand(layers[i], layers[i - 1]), bias=np.random.rand(layers[i]), outputs=np.zeros(layers[i]), deltas=np.zeros(layers[i]), ) for i in range(1, len(layers)) ]
return Network(layers=layers)
def feed_forward(self, inputs: np.array) -> np.array: """ 前向传播:计算神经网络的输出 :param inputs: 输入信号,形状为(输入层神经元数,) :return: 输出层的输出值 """ for layer in self.layers:
layer.outputs = sigmoid(layer.weights @ inputs + layer.bias) inputs = layer.outputs return self.layers[-1].outputs
def back_propagate(self, inputs: np.array, expected: np.array) -> None: """ 反向传播:计算误差并更新权重 :param inputs: 输入信号 :param expected: 期望输出值 """ for idx in reversed(range(self.length)): layer = self.layers[idx] if idx == len(self.layers) - 1: layer.deltas = (layer.outputs - expected) * sigmoid_derivative( layer.outputs ) else: next_layer = self.layers[idx + 1] layer.deltas = ( next_layer.weights.T @ next_layer.deltas * sigmoid_derivative(layer.outputs) ) * sigmoid_derivative(layer.outputs)
self.update_weights(inputs)
def update_weights(self, inputs: np.array) -> None: """ 更新权重和偏置 :param inputs: 输入信号 """ for idx in range(self.length): layer = self.layers[idx] previous_layer_outputs = self.layers[idx - 1].outputs if idx > 0 else inputs layer.weights -= ( layer.deltas[np.newaxis].T @ previous_layer_outputs[np.newaxis] * self.learning_rate ) layer.bias -= layer.deltas * self.learning_rate
def train(self, inputs: np.array, expected: np.array, epochs: int) -> None: """ 训练神经网络 :param inputs: 输入数据集 :param expected: 期望输出数据集 :param epochs: 训练轮数 """ for epoch in range(epochs): sum_error = 0.0 for idx, row in enumerate(inputs): actual = self.feed_forward(row) self.back_propagate(row, expected[idx]) sum_error += self.mse(actual, expected[idx]) print(f"Mean squared error: {sum_error}") print(f"epoch={epoch}")
def mse(self, actual: np.array, expected: np.array) -> float: """ 计算均方误差(Mean Squared Error) :param actual: 实际输出值 :param expected: 期望输出值 :return: 均方误差值 """ return np.power(actual - expected, 2).mean()
def predict(self, inputs: np.array) -> int: """ 预测输入数据的类别 :param inputs: 输入信号 :return: 预测的类别索引
""" outputs = self.feed_forward(inputs) return np.where(outputs == outputs.max())[0][0]
if __name__ == "__main__": network = Network.create([2, 3, 2]) inputs = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) expected = np.array([[1, 0], [0, 1], [0, 1], [1, 0]]) network.train(inputs, expected, epochs=100) for row in inputs: print(f"Input: {row}, Predicted: {network.predict(row)}")
使用numpy有助于我们稍微缩短代码——你可以想象它利用矩阵进行“批量”计算,而不是像之前的实现那样一次遍历一个神经元和一层。
然而,为了理解和编写正确的计算,你需要对每一步中矩阵的维度有很好的心理模型。
代码中添加了注释,说明了大多数计算所需的维度(基于测试用例)。
层类是一个数据类,封装了与神经网络中一层相关的参数和属性,我们不再需要神经元类,因为它将只是numpy数组/矩阵中的一个元素。
并且添加了一个静态方法create,该方法根据每层中指定的神经元数量创建具有随机权重和偏置的网络。
其余函数相同,只是计算是通过矩阵乘法而不是手动乘以每个神经元的数据来完成的。
当然,有很多方法可以实现这一点——有人可能会进一步简化并完全删除层类,用嵌套数组表示整个网络。
然而,这种方法在处理所有多个维度时有点难以理解,所以目前我们采用了这种方法。
让我们尝试使用相同的数据集运行代码:
def test_make_prediction_with_network(): """ 测试神经网络的预测功能 测试数据来自:https: """ # 测试数据集 dataset = np.array( [ [2.7810836, 2.550537003], [1.465489372, 2.362125076], [3.396561688, 4.400293529], [1.38807019, 1.850220317], [3.06407232, 3.005305973], [7.627531214, 2.759262235], [5.332441248, 2.088626775], [6.922596716, 1.77106367], [8.675418651, -0.242068655], [7.673756466, 3.508563011], ] ) # 期望输出(类别标签,使用one-hot编码) expected = np.array( [ [1, 0], # 类别0 [1, 0], # 类别0 [1, 0], # 类别0 [1, 0], # 类别0 [1, 0], # 类别0 [0, 1], # 类别1 [0, 1], # 类别1 [0, 1], # 类别1
[0, 1], # 类别1 [0, 1], # 类别1 ] )
# 创建神经网络:输入层2个神经元,隐藏层3个神经元,输出层2个神经元 network = Network.create([len(dataset[0]), 3, len(expected[0])])
# 训练神经网络,训练轮数为40 network.train(dataset, expected, 40)
# 对测试数据进行预测并打印结果 for i in range(len(dataset)): prediction = network.predict(dataset[i]) # 预测类别 print( f"{i} - Expected={np.where(expected[i] == expected[i].max())[0][0]}, Got={prediction}" ) # 打印期望类别和预测类别
if __name__ == "__main__": # 运行测试函数 test_make_prediction_with_network()
输入和期望输出的维度显然略有变化以适应numpy的n维数组,但数据保持不变。
这是一个示例输出:
Mean squared error: 1.1978125477947856epoch=36Mean squared error: 1.1020105642439684epoch=37Mean squared error: 1.013486082749448epoch=38Mean squared error: 0.9322033466403574epoch=390 - Expected=0, Got=01 - Expected=0, Got=02 - Expected=0, Got=03 - Expected=0, Got=04 - Expected=0, Got=05 - Expected=1, Got=16 - Expected=1, Got=17 - Expected=1, Got=18 - Expected=1, Got=19 - Expected=1, Got=1
另外我们打磨了一套基于数据与模型方法的 AI科研入门学习方案(已经迭代过5次),对于ai来说,任何专业,要处理的都只是实验数据,所以我们根据实验数据将课程分为了三种方向的针对性课程,包含时序、图结构、影像三大实验室,我们会根据你的数据类型来帮助你选择合适的实验室,根据规划好的路线学习 只需 5 个月左右(很多同学通过学习已经发表了 sci 二区及以下、ei会议等级别论文)如果需要发高区也有其他形式。
大家感兴趣可以直接添加小助手微信:ai0808q 通过后回复咨询既可!
大家觉得这篇文章有帮助的话记得分享给你的死党、闺蜜、同学、朋友、老师、敌蜜!









