添加微信:CVer2233,助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪必备!
近年来,多模态大语言模型(MLLMs)主要聚焦在视觉和文本模态的融合上,对语音的关注较少。然而,语音在多模态对话系统中扮演着至关重要的角色。由于视觉和语音模态之间的差异,同时在视觉和语音任务上取得高性能表现仍然是一个显著的挑战。

VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction论文链接:
https://arxiv.org/pdf/2501.01957代码链接(Star数破千):
https://github.com/VITA-MLLM/VITA1. 增加语音模态:在视觉-语言多模态模型的基础上,增加语音输入和输出能力,使其能够高效处理视觉、文本和语音任务。2. 快速端到端交互:避免使用独立的自动语音识别(ASR)和语音合成(TTS)模块与 LLM 级联的方案,显著提升交互时端到端响应速度。
1. 多阶段训练方法:提出了一种精心设计的多阶段训练策略,逐步训练大语言模型 LLM 理解视觉和语音信息。这种策略使得模型在保留强大的视觉-语言能力的基础上,进一步获得了高效的语音对话能力。2. 端到端 Speech-to-Speech:采用端到端语音输入和语音输出方式,大幅提升了视觉-语音的性能表现。3. 实时交互能力:VITA-1.5 能够实现接近实时的视觉-语音交互,是目前开源领域最快的视觉-语音交互模型。4. 开源与社区支持:VITA-1.5 的训练和推理代码已开源,并在社区中获得了广泛关注(已取得 1.6K GitHub Star)。VITA-1.5 致力于推动多模态交互系统的发展,向 GPT-4o 水平的实时交互迈出了重要一步。

模型架构
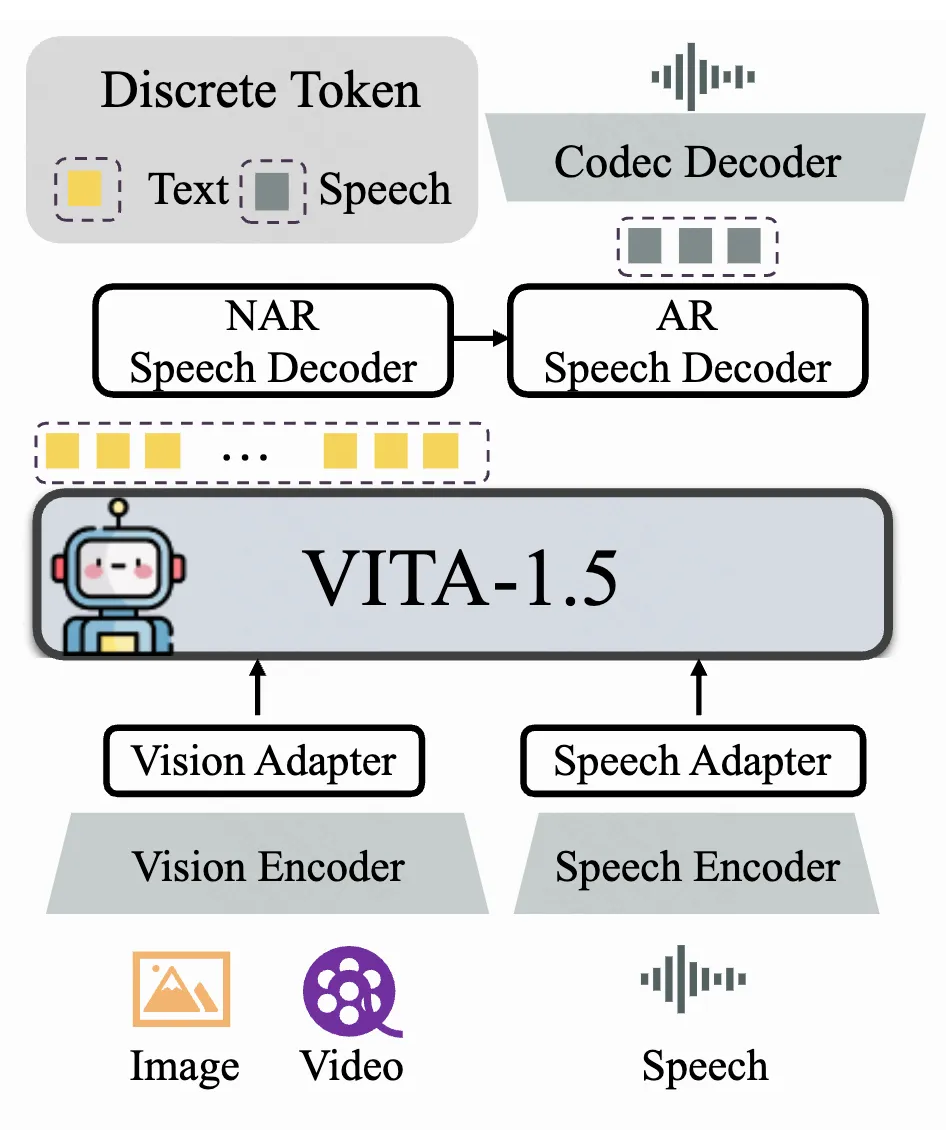
VITA-1.5 的整体架构包括输入侧的视觉编码器和音频编码器,以及输出侧的端到端语音生成模块。与上一版的 VITA-1.0 不同,VITA-1.5 不再级联外部独立的 TTS 模块,而是实现了端到端的语音生成能力。模型采用“多模态编码器-适配器-LLM” 的配置,旨在通过联合训练提升视觉、语言和语音的统一理解能力。
1.1 视觉模态
VITA-1.5 使用 InternViT-300M 作为视觉编码器,输入图像大小为 448×448 像素,每张图像生成 256 个视觉 token。对于高分辨率图像,采用动态分块策略以捕获局部细节,从而提升图像理解的精度。
视频处理
视觉适配器
通过一个两层 MLP 将视觉特征映射为适合 LLM 理解的视觉 token。
音频编码器由多个降采样卷积层(4 倍降采样)和 24 层 Transformer 块组成,隐藏层维度为 1024。降采样层降低了音频特征的帧率,从而提高了处理速度。编码器参数量约为 350M,输出帧率为 12.5Hz。音频输入采用 Mel-filter bank features。
由多个 2 倍降采样的卷积层组成,用于进一步处理音频特征。
语音解码模块采用 TiCodec 作为 Codec 模型,使用一个大小为 1024 的单一码本。这种设计简化了推理阶段的解码过程。编解码器负责将连续的语音信号编码为离散语音 token,并能解码回 24,000Hz 的语音信号。为了让 LLM 能够输出语音 token,VITA-1.5 在文本 token 的基础上增加了两个语音解码器:
非自回归(NAR)语音解码器:对文本token进行整体处理,建模语义特征,用于生成初始的语音 token 分布。
自回归(AR)语音解码器:基于 NAR 解码器生成的语音信息,逐步生成高质量的语音 token。
最终生成的语音 token 序列通过 Codec 模型解码为连续的语音信号流。

训练数据
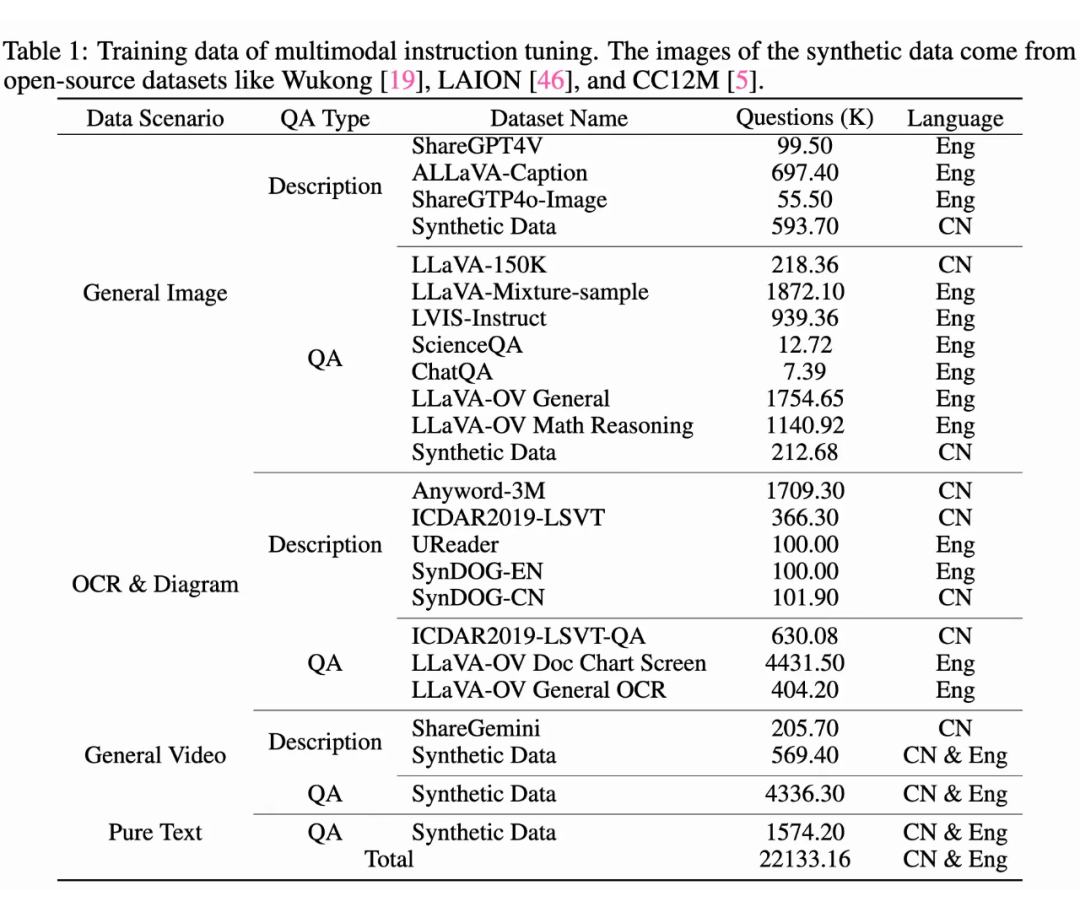
VITA-1.5 的多模态指令微调数据涵盖了多种类别,包括图像描述、问答数据,以及中英文数据。在不同训练阶段,选择性地使用数据子集以实现不同目标。主要数据类别如下:
1. 图像描述数据:包括 ShareGPT4V、ALLaVA-Caption、SharedGPT4o-Image 和合成数据,用于训练模型生成图像的描述性语言。
2.图像问答数据:包括 LLaVA-150K、LLaVA-Mixture-sample、LVIS-Instruct、ScienceQA、ChatQA,以及从LLaVA-OV 中采样的子集(如一般图像问答和数学推理数据),用于训练模型回答基于图像的问题,并执行视觉推理任务。3. OCR 与图表数据:包括 Anyword-3M、ICDAR2019-LSVT、UReader、SynDOG、ICDAR2019-LSVT-QA,以及从 LLaVA-OV 中采样的相关数据,用于支持模型理解 OCR 和图表内容。4. 视频数据:包括 ShareGemini 和合成数据,用于训练模型处理视频输入,并执行视频描述和基于视频的问答任务。5. 纯文本数据:增强模型的语言理解和生成能力,支持文本问答任务。此外,还引入了以下语音数据:

为了确保 VITA-1.5 在视觉、语言和语音任务中表现出色,需要解决不同模态之间的训练冲突。例如,添加语音数据可能会对视觉内容的理解产生负面影响,因为语音特征与视觉特征差异显著,会在学习过程中造成干扰。为了解决这个问题,设计了一个三阶段的训练策略。核心思想是逐步将不同模态引入模型,使其在增强新模态能力的同时,保持现有模态的能力。
3.1 阶段1:视觉-语言训练
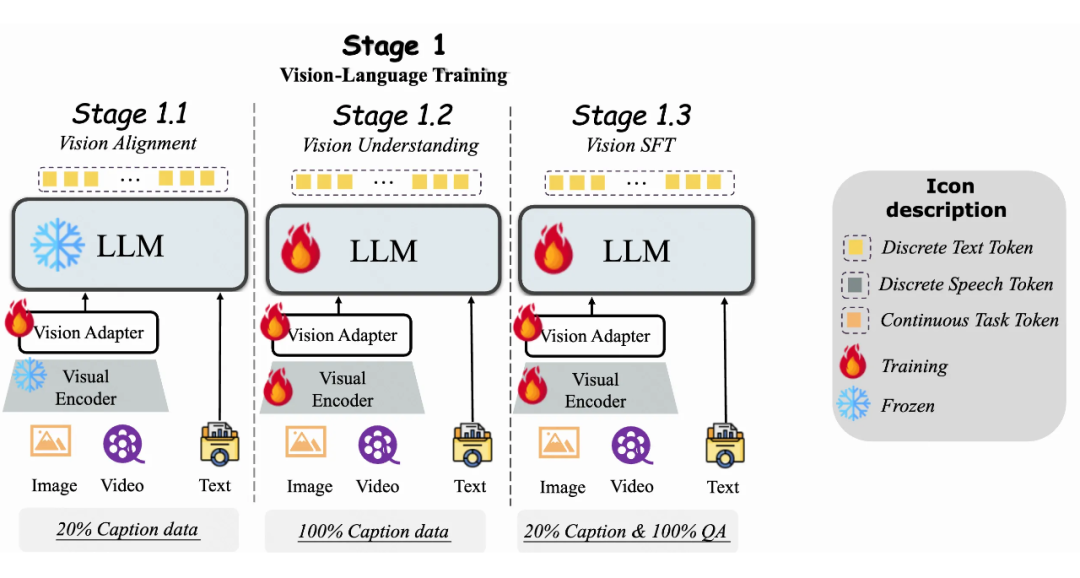
目标是弥合视觉和语言之间的差距。视觉特征通过预训练的视觉编码器 InternViT-300M 提取,语言通过 LLM 引入。使用 20% 的描述性 Caption 数据进行训练,仅训练视觉适配器,其他模块冻结。这种方法使得 LLM 初步对齐视觉模态。
阶段1.2 视觉理解
目标是教会 LLM 转录视觉内容。使用全部描述性 Caption 数据,训练过程中视觉模块的编码器和适配器以及 LLM 都是可训练的。重点是通过学习关于视觉的描述性文本,使模型能够通过生成对应的自然语言描述。
阶段1.3 视觉指令微调
在阶段 1.2 之后,模型已获得对图像和视频的基本理解,但指令跟随能力仍有限,难以应对视觉问答任务。在这一阶段使用所有问答数据,同时保留 20% 的描述性 Caption 数据,以增加数据集的多样性和任务的复杂性。训练期间,视觉模块的编码器和适配器以及 LLM 都是可训练的,目标是使模型不仅能够理解视觉内容,还能够根据指令回答问题。
3.2 阶段2:音频输入微调
阶段2.1 音频对齐
完成阶段 1 的训练后,模型在图像和视频理解方面已打下坚实基础。本阶段目标是在阶段 1 的基础上减少语音和语言之间的差异,使 LLM 能够理解音频输入。训练数据包括 11,000 小时的语音-转录对。采用两步法:(a)语音编码器训练:使用 CTC 损失函数训练语音编码器,目标是让编码器从语音输入中预测转录文本。确保音频编码器能够提取语音特征并将其映射到文本表示空间。(b)语音适配器训练:训练语音编码器后,将其与 LLM 集成,使用音频适配器将音频特征引入 LLM 的输入层。本阶段的训练目标是使 LLM 输出语音数据的转录文本。此外,在步骤(b)中引入特殊的可训练输入 token,以引导语音理解过程,这些 token 提供额外的上下文信息,引导 LLM 执行 ASR 任务。
阶段2.2 音频指令微调
本阶段重点是引入语音问题和文本答案的问答功能。为此,从数据集中抽取 4% 的 Caption 数据和 20% 的问答数据。数据处理方面,大约一半的基于文本的问题被随机替换为其对应的语音版本,由外部的 TTS 系统生成。本阶段视觉编码器和适配器、音频编码器和适配器以及 LLM 均是可训练的,旨在提高模型对多模态输入的适应性。此外,在 LLM 的输出中添加一个分类头,用于区分输入是来自语音还是文本,从而使模型能够更高效灵活地处理不同模态。
3.3 阶段3:音频输出微调
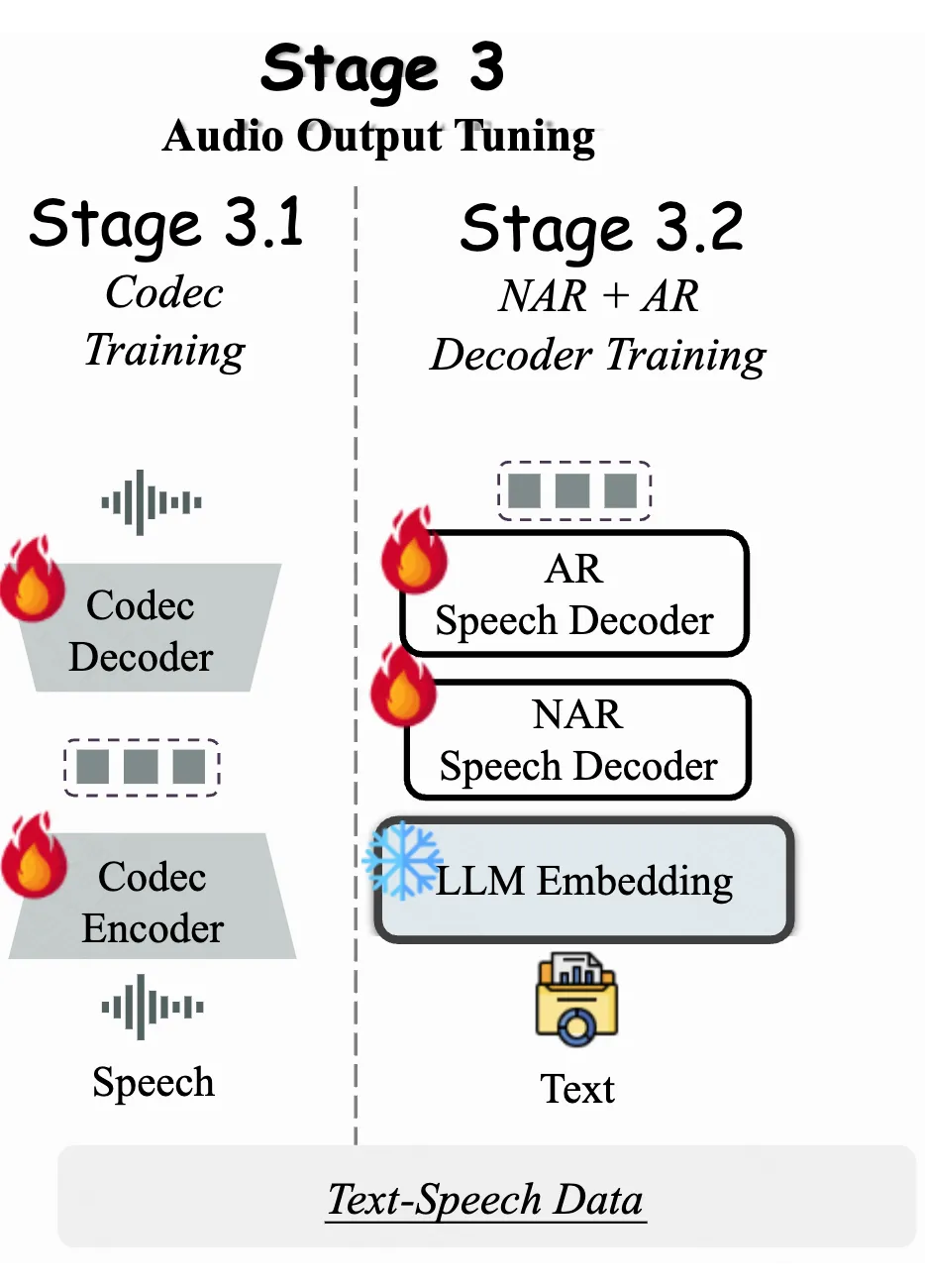
在前两个训练阶段,VITA-1.5 模型已经获得了多模态理解能力。然而,作为一个交互助手,语音输出是必不可少的功能。为了在不影响模型基本能力的情况下引入语音输出功能,采用了 3,000 小时的文本-语音数据,并使用两步训练方法:
阶段3.1 Codec 模型训练
目标是使用语音数据训练一个单一码本的 Codec 模型。Codec 的编码器能够将语音映射为离散 token,其解码器可以将离散 token 映射回语音信号。在 VITA-1.5 的推理阶段,仅使用 Codec 的解码器。
阶段3.2 NAR+AR 语音解码器训练
这一步使用文本-语音配对数据进行训练。其中,文本输入到 LLM 的 tokenizer 和 Embedding 层以获取其 Embedding 向量,而语音输入到 Codec 的编码器以获取其语音 token。文本 Embedding 被送入非自回归语音解码器(NAR)以获得全局语义特征,然后这些特征被送入自回归语音解码器(AR),以预测相应的语音 token。LLM 在此阶段是完全冻结的,因此此前的多模态性能不受影响。

实验发现
4.1 视觉-语言评估
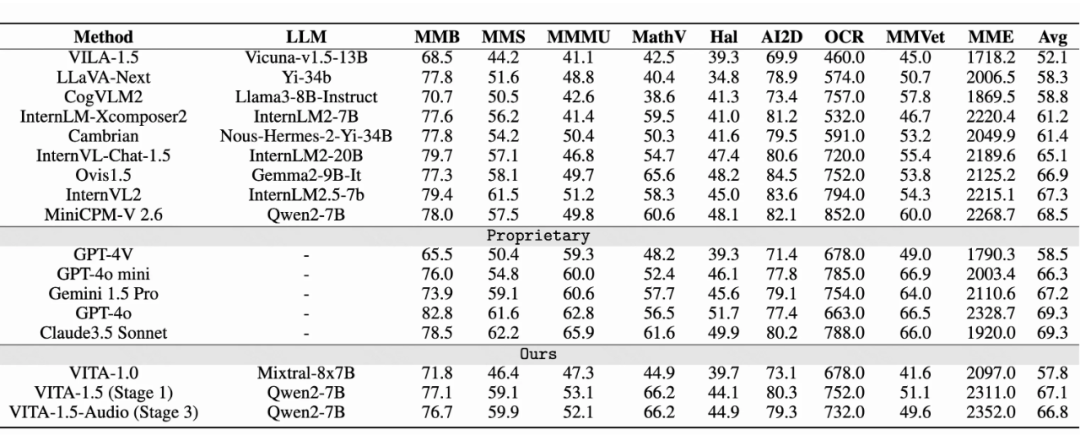
▲ 图像理解能力评测
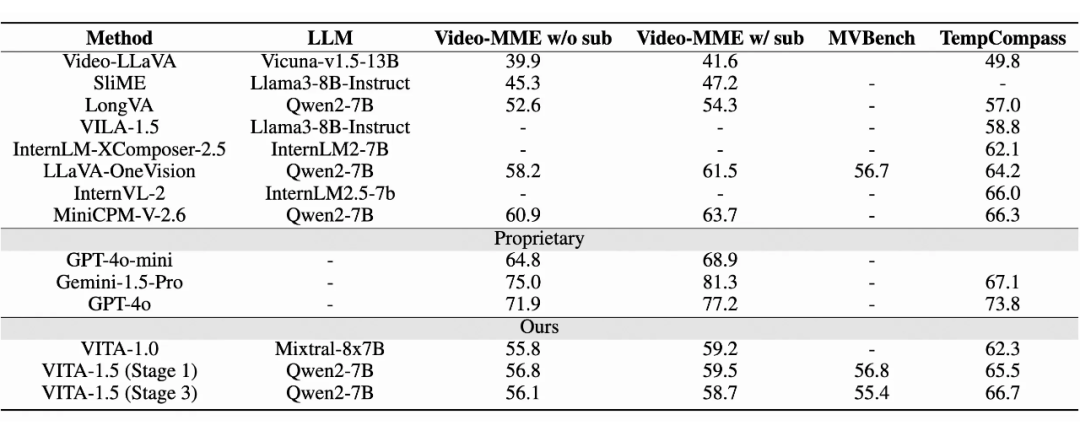
上表展示了 VITA-1.5 在图像理解性能上的对比。经过三阶段训练后,VITA-1.5 的表现可与最先进的开源图像-语言模型媲美,显示了 VITA-1.5 在图像-语言任务中的强大能力。在视频理解评估中,VITA-1.5 的表现与顶尖开源模型相当。但与私有模型仍有较大差距,这表明 VITA-1.5 在视频理解方面仍有较大的改进空间和潜力。
VITA-1.5 的一个亮点在于,在第二阶段(音频输入微调)和第三阶段(音频输出微调)训练后,VITA-1.5 几乎保留了其在第一阶段(视觉-语言训练)中的视觉-语言能力,尽量避免了因为引入语音信息导致多模态能力下降。4.2 语音识别能力评估
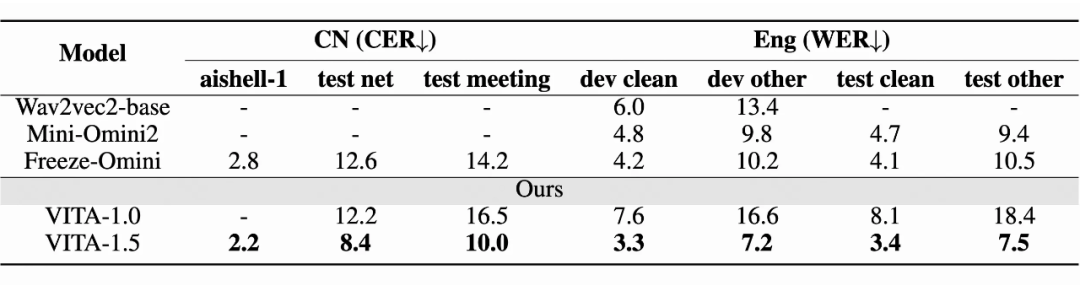
基准模型
使用了以下三个基准模型进行比较:Wav2vec2-base、Mini-Omini2、Freeze-Omini 和 VITA-1.0。
评估基准
中文评估集包括三个数据集:aishell-1、test net 和 test meeting。这些数据集用于评估模型在中文语音上的表现,评估指标是字符错误率(CER)。英文评估集包括四个数据集:dev-clean、dev-other、test-clean 和 test-other,用于评估模型在英语语音上的表现,评估指标是词错误率(WER)。
ASR性能
评估结果表明,VITA-1.5 在中文和英文 ASR 任务中均达到了领先的准确性。这表明 VITA-1.5 成功整合了先进的语音能力,用以支持多模态交互。

未来工作
VITA-1.5 通过精心设计的三阶段训练策略整合视觉和语音。通过缓解模态之间的固有冲突,VITA-1.5 在视觉和语音理解方面实现了强大的能力,能够在不依赖于独立的 ASR 和 TTS 模块的情况下实现高效的 Speech-to-Speech 能力。不过其实验和文章内容也指出了一些可能的未来改进工作:增强语音生成质量:虽然 VITA-1.5 已实现内置语音生成能力,但进一步提升生成语音的自然度和清晰度,尤其是带情绪的输出,仍是一个重要的研究方向。多模态数据扩展:引入更多样化的多模态数据集,尤其是涵盖更多场景和语言的语音数据,将有助于进一步提升模型的泛化能力和适应性。实时性和效率优化:在保持高性能的同时,进一步优化模型的计算效率和实时响应能力,以便在资源受限的环境中也能有效运行。在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集
Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看











