专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
自ChatGPT问世以来,在医学领域一直发挥非常出色。例如,在德国医学国家考试中的得分超过了人类学生,平均得分74.6%,正确回答了630个问题中的88.1%。
在实际医疗应用中,ChatGPT对284个跨17个专科的医疗查询生成了比较准确的信息,且随着时间推移通过强化学习不断改进;在骨科运动医学领域,其对样本问题的回答准确率高达65%。
为了进一步挖掘ChatGPT的应用潜力,德国路德维希港BG诊所的研究人员通过分析100个来自创伤外科、普通外科、耳鼻喉科、儿科和内科5大类的健康相关问题,比较了ChatGPT与经验丰富的专家(EP)的回答。结果显示,ChatGPT在同情心和实用性方面比专家更好。

为了全面评估患者对AI助手的感知,研究人员使用了多步骤的方法。首先,从一个面向患者的网络平台中收集了100个公开的健康相关问题,这些问题涵盖了5大不同的医学专业领域:创伤外科、普通外科、耳鼻喉科、儿科和内科。每个专业领域各选取了20个问题,以确保样本的多样性和代表性。
然后,研究人员使用ChatGPT-4.0生成了针对这100个问题的回答,并将这些回答与来自同一网络平台的专家的回答进行了对比。
为了保证评估的客观性,所有问题和回答都被匿名化处理,并打包成10个每组包含10个问题的数据集。这些数据集随后被分发给患者和医生进行评估。
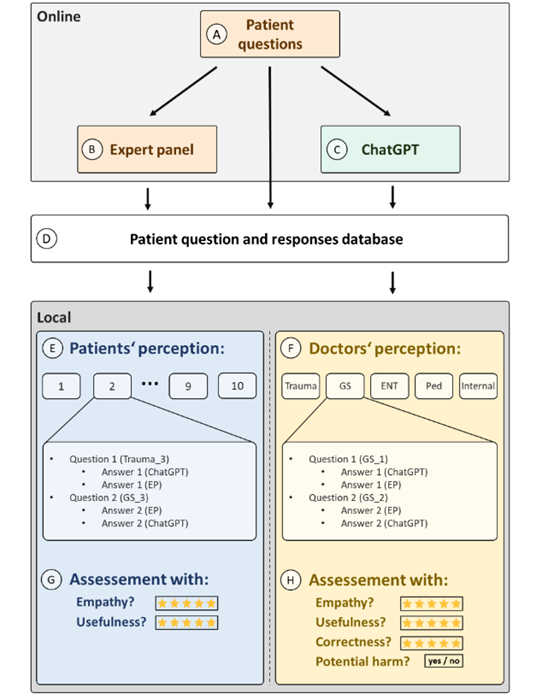
患者和医生分别对ChatGPT和专家的回答进行了评价。患者主要关注的是回答的同理心和实用性,具体通过一个问题:“这个回答对你有帮助吗?”来进行评分,评分范围从1到5。
医生则除了评估同理心和实用性外,还需要评价回答的正确性和潜在危害。所有评分均采用5分制,其中1表示非常不满意或不正确,5表示非常满意或完全正确。
为了确保评估的公正性,所有参与者在评估过程中均不知道回答是由ChatGPT还是专家提供的。此外,研究团队还要求患者提供年龄、性别等基本信息,以便进一步分析这些因素对评估结果的影响。医生则需要提供他们的从业年限,以评估经验对评估结果的影响。

患者对ChatGPT的回答普遍给予了较高的评价。在同理心方面,ChatGPT的平均评分为4.2(标准误0.15),而专家的平均评分为3.8(标准误0.18)。在实用性方面,ChatGPT的平均评分为4.1,而专家的平均评分为3.7。这些结果表明,患者认为ChatGPT的回答比专家的回答更具同理心和实用性。
进一步的分析显示,患者的年龄和性别对评估结果没有显著影响。然而,患者的教育水平和社会经济地位可能会影响他们对ChatGPT的接受程度,但由于本研究未收集这些数据,因此无法进行详细的分析。
医生对ChatGPT的回答也给予了较高的评价。在同理心方面,ChatGPT的平均评分为4.3,而专家的平均评分为3.9(。在实用性方面,ChatGPT的平均评分为4.2(标准误0.15),而专家的平均评分为3.8(标准误0.17)。
在正确性方面,ChatGPT的平均评分为4.5(标准误0.13),而专家的平均评分为4.1(标准误0.15)。这些结果进一步证实了患者对ChatGPT的积极评价。
值得一提的是,医生对ChatGPT的回答在潜在危害方面的评分也较低。ChatGPT的平均潜在危害评分为1.2(标准误0.08),而专家的平均潜在危害评分为1.5(标准误0.10)。这表明,ChatGPT的回答不仅在同理心、实用性和正确性方面表现优异,而且在避免潜在危害方面同样出色。
本文素材来源德国BG论文,如有侵权请联系删除
END












