
大家可能没有注意过,人类一直在不自觉地对各种事物进行预测——哪怕是最微小或看似无关紧要的事物。
例如,装水的时候我们会预测什么时候能装满杯子。
在过马路时,我们会本能地预判车辆的位置,以确保自己能够安全通过。
在执行这些日常任务时,我们并不需要精确了解车辆的速度或水流的速度,这些复杂的计算对我们来说似乎是自然而然、水到渠成的事情。
这些预测能力是通过多年的生活经验、学习和练习,在无数次的实践过程中逐渐培养起来的。
然而,当我们试图主动预测大规模现象(如天气变化或未来一年的经济走势)时,情况就变得复杂得多了。
由于这些现象涉及的因素众多且相互关联,我们往往会感到力不从心,难以做出准确的预测。
这时,计算机的强大功能便显得尤为重要——它能够弥补我们在处理看似随机的偶发事件并将其与未来事件相关联方面的不足。
计算机在多次重复执行特定任务方面表现出色——我们可以利用这一优势来预测未来。
为了让大家可以更系统的学习时间序列,小墨学长还为大家准备了神经网络和时间序列的相关学习资料。

本文的数据集和时间序列、神经网络学习资料大家可以任意添加一位小助手获取(记得发送文章标题哦)


什么是“时间序列”?
时间序列是指任何在一段时间内发生的可量化指标或事件,几乎任何事物都可以被视为时间序列。
例如,你一个月内每小时的平均心率、一只股票一年内每天的收盘价,或某个城市一年内每周的车辆事故数量。
只要是在任何统一时间段内记录的信息,都可视为时间序列,
大家可能会注意到,上述每个示例中的事件都有一个频率(如每日、每周、每小时等)和一个持续时间(如一个月、一年、一天等)。
对于时间序列,我们会在整个观察期间以统一的频率记录该指标,换句话说,每条记录之间的时间间隔应该是相同的。
在本教程中,我们将探讨如何使用时间序列形式的过去数据来预测未来可能发生的情况。
目标
算法的目标是接收一系列数值,并预测序列中的下一个数值。
最简单的方法是使用自回归模型,但今天我们将使用循环神经网络(RNN)的深度学习方法来解决这个问题。
数据准备
让我们先来看一个时间序列样本,下面的图表显示了2013年至2018年油价的一些数据。
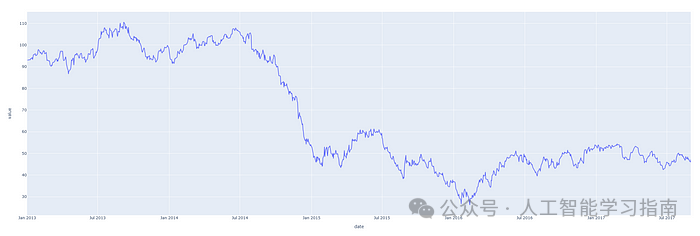
这只是一个在日期轴上绘制的单一数字序列的图,下面的表格显示了该时间序列的前10条记录。
仅查看日期列,就可以明显看出我们拥有每日频率的价格数据。
date dcoilwtico2013-01-01 NaN2013-01-02 93.142013-01-03 92.972013-01-04 93.122013-01-07 93.202013-01-08 93.212013-01-09 93.082013-01-10 93.812013-01-11 93.602013-01-14 94.27
许多机器学习模型在归一化数据上表现更佳,归一化数据的标准方法是将数据转换,使得每列的均值为0,标准差为1。
下面的代码使用scikit-learn库提供了实现这一操作的方法。
from sklearn.preprocessing import StandardScaler
scalers = {}
for x in df.columns: scalers[x] = StandardScaler().fit(df[x].values.reshape(-1, 1))
norm_df = df.copy()
for i, key in enumerate(scalers.keys()): norm = scalers[key].transform(norm_df.iloc[:, i].values.reshape(-1, 1)) norm_df.iloc[:, i] = norm
我们还需确保数据具有统一的频率——在本例中,我们拥有这5年来每天的油价数据,因此这一点得到了很好的满足。
如果你的数据并非如此,Pandas提供了几种不同的方法来重新采样数据以适应统一的频率。
序列化
实现这一点后,我们将使用时间序列生成固定长度的片段或序列。
在记录这些序列时,我们还将记录紧跟在该序列之后出现的值。例如:假设我们有一个序列:[1, 2, 3, 4, 5, 6]。
选择序列长度为3时,我们可以生成以下序列及其关联的目标值:
[序列]:目标值
[1, 2, 3] → 4
[2, 3, 4] → 5
[3, 4, 5] → 6
另一种看待这个问题的方式是,我们定义了要回溯多少步来预测下一个值。
我们将这个值称为训练窗口,将要预测的值数称为预测窗口。
在本例中,它们分别为3和1,下面的函数详细说明了如何实现这一点。
def generate_sequences(df: pd.DataFrame, tw: int, pw: int, target_columns, drop_targets=False): ''' 参数说明: df: Pandas DataFrame,表示单变量或多变量的时间序列数据 tw: Training Window,整数,表示输入序列的时间步数(向后看多少步) pw: Prediction Window,整数,表示目标预测的时间步数(向前预测多少步) target_columns: 目标列的名称列表,表示要预测的列 drop_targets: 布尔值,可选,是否从数据集中删除目标列
返回值: 一个字典,包含所有生成的输入序列和目标值,每个序列和目标值用键值对存储 '''
data = dict() L = len(df)
for i in range(L - tw): if drop_targets: df.drop(target_columns, axis=1, inplace=True)
sequence = df[i:i + tw].values target = df[i + tw:i + tw + pw][target_columns].values data[i] = {'sequence': sequence, 'target': target} return data
PyTorch要求我们按照以下方式将数据存储在Dataset类中:
class SequenceDataset(Dataset):
def __init__(self, df): self.data = df
def __getitem__(self, idx): sample = self.data[idx] return torch.Tensor(sample['sequence']), torch.Tensor(sample['target']) def __len__(self): return len(self.data)
然后,我们可以使用PyTorch DataLoader来迭代数据,使用DataLoader的好处是,它内部处理批处理和混洗,因此我们无需自己实现这些功能。
执行以下代码后,训练批次便准备就绪:
BATCH_SIZE = 16 split = 0.8
sequences = generate_sequences(norm_df.dcoilwtico.to_frame(), sequence_len, nout, 'dcoilwtico')
dataset = SequenceDataset(sequences)
train_len = int(len(dataset) * split) lens = [train_len, len(dataset) - train_len] train_ds, test_ds = random_split(dataset, lens)
trainloader = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)testloader = DataLoader(test_ds, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
在每次迭代中,DataLoader将生成16个(批大小)序列及其关联的目标值,我们将这些值传递给模型。
模型架构
下面的类在PyTorch中定义了这种架构,我们将使用一个LSTM层,后面跟着一些用于模型回归部分的密集层,并在它们之间添加丢弃层,该模型将为每个训练输入输出一个单一值。
class LSTMForecaster(nn.Module): """ 定义一个用于时间序列预测的 LSTM 模型。 """
def __init__(self, n_features, n_hidden, n_outputs, sequence_len, n_lstm_layers=1, n_deep_layers=10, use_cuda=False, dropout=0.2): ''' 初始化 LSTM 模型参数: n_features: 输入特征的数量(对于单变量预测,通常为 1) n_hidden: 每个隐藏层中的神经元数量 n_outputs: 每个训练样本需要预测的输出数量 sequence_len: 预测时需要回顾的时间步长(时间序列长度) n_lstm_layers: LSTM 层的数量 n_deep_layers: LSTM 后的全连接层数量 use_cuda: 是否使用 GPU 进行计算 dropout: float (0 < dropout < 1),用于防止过拟合的 dropout 比例 ''' super().__init__()
self.n_lstm_layers = n_lstm_layers self.nhid = n_hidden self.use_cuda = use_cuda
self.lstm = nn.LSTM(n_features, n_hidden, num_layers=n_lstm_layers, batch_first=True)
self.fc1 = nn.Linear(n_hidden * sequence_len, n_hidden) self.dropout = nn.Dropout(p=dropout)
dnn_layers = [] for i in range(n_deep_layers): if i == n_deep_layers - 1: dnn_layers.append(nn.ReLU()) dnn_layers.append(nn.Linear(n_hidden, n_outputs)) else: dnn_layers.append(nn.ReLU()) dnn_layers.append(nn.Linear(n_hidden, n_hidden)) if dropout: dnn_layers.append(nn.Dropout(p=dropout))
self.dnn = nn.Sequential(*dnn_layers)
def forward(self, x): ''' 定义前向传播过程: x: 输入数据,形状为 (batch_size, seq_len, features) '''
hidden_state = torch.zeros(self.n_lstm_layers, x.shape[0], self.nhid) cell_state = torch.zeros(self.n_lstm_layers, x.shape[0], self.nhid)
if self.use_cuda: hidden_state = hidden_state.to(device) cell_state = cell_state.to(device)
self.hidden = (hidden_state, cell_state)
x, h = self.lstm(x, self.hidden) x = self.dropout(x.contiguous().view(x.shape[0], -1)) x = self.fc1(x) return self.dnn(x)
这个类是我构建的一个即插即用的Python类,能够基于我们选择的参数动态构建任何大小的这种类型神经网络——因此,你可以根据需要调整n_hidden和n_deep_players参数,为你的模型添加或删除参数。
参数越多,模型越复杂,训练时间越长,因此请根据你的用例选择最适合你数据的参数。
作为任意选择,让我们创建一个具有5个全连接层的长短期记忆(LSTM)模型,每个层有50个神经元,每个训练批次中的每个训练示例最终输出一个单一值。
在这里,sequence_len指的是训练窗口,nout定义了要预测的步骤数;
将sequence_len设置为180,nout设置为1,意味着模型将回顾180天(半年)的数据来预测明天会发生什么。
nhid = 50 n_dnn_layers = 5 nout = 1 sequence_len = 180
ninp = 1
USE_CUDA = torch.cuda.is_available() device = 'cuda' if USE_CUDA else 'cpu'
model = LSTMForecaster( ninp, nhid, nout, sequence_len, n_deep_layers=n_dnn_layers, use_cuda=USE_CUDA ).to(device)
模型训练
定义了模型后,我们可以选择损失函数和优化器,设置学习率和迭代次数,并开始训练循环。
由于这是一个回归问题(即我们试图预测一个连续值),因此损失函数的一个安全选择是均方误差(MSE)。
这提供了一种稳健的方法来计算实际值与模型预测值之间的误差。计算公式如下:

优化器对象存储并计算反向传播所需的所有梯度。
lr = 4e-4 n_epochs = 20
criterion = nn.MSELoss().to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
以下是训练循环。在每个训练迭代中,我们将计算之前创建的训练集和验证集上的损失:
t_losses, v_losses = [], []
for epoch in range(n_epochs): train_loss, valid_loss = 0.0, 0.0
model.train() for x, y in trainloader: optimizer.zero_grad() x = x.to(device) y = y.squeeze().to(device) preds = model(x).squeeze() loss = criterion(preds, y) train_loss += loss.item() loss.backward() optimizer.step()
epoch_loss = train_loss / len(trainloader) t_losses.append(epoch_loss)
model.eval() for x, y in testloader: with torch.no_grad(): x, y = x.to(device), y.squeeze().to(device) preds = model(x).squeeze() error = criterion(preds, y) valid_loss += error.item() valid_loss = valid_loss / len(testloader) v_losses.append(valid_loss)
print(f'{epoch} - train: {epoch_loss}, valid: {valid_loss}')
plot_losses(t_losses, v_losses)

现在模型已训练完毕,我们可以评估预测结果。
推理
在这里,我们将简单地调用我们的训练模型来预测未打乱的数据,并查看预测结果与真实观测值之间的差异。
def make_predictions_from_dataloader(model, unshuffled_dataloader): model.eval() predictions, actuals = [], [] for x, y in unshuffled_dataloader: with torch.no_grad(): p = model(x) predictions.append(p) actuals.append(y.squeeze()) predictions = torch.cat(predictions).numpy() actuals = torch.cat(actuals).numpy() return predictions.squeeze(), actuals
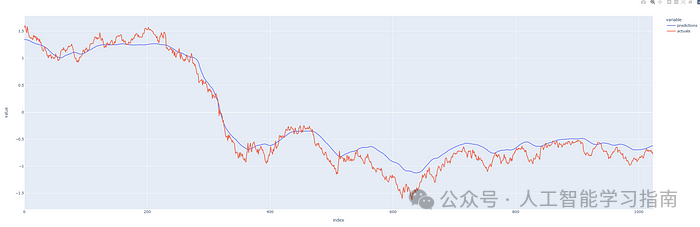
历史石油的标准化预测价格与实际价格
首次尝试,我们的预测结果还算不错!而且验证损失与训练损失一样低,这说明我们没有让模型过拟合,因此可以认为模型的泛化能力良好——这对于任何预测系统而言都至关重要。
针对这一时期油价随时间变化的预测,我们已经有了一个相当不错的估算器,接下来,让我们看看能否用它来预测未来的情况。
预测
如果我们把历史定义为直到预测时刻为止的一系列数据,那么算法就很简单:
从历史数据中获取最新的有效序列(训练窗口长度)。
将该最新序列输入模型,预测下一个值。
将预测值添加到历史数据中。
从第1步开始,进行任意次数的迭代。
这里需要注意的一点是,根据训练模型时选择的参数,预测的时间越远,模型就越容易受到自身偏差的影响,并开始预测平均值。
因此,如果没有必要,我们不想总是预测太远,因为这会影响预测的准确性。
以下函数实现了上述过程:
def
one_step_forecast(model, history): ''' 单步预测函数。 参数: model: PyTorch 模型对象 history: 表示时间序列最新值的数组,要求 `len(history.shape) == 2`(二维数组) 返回: 单个值,表示序列中下一个值的预测结果。 ''' model.cpu() model.eval() with torch.no_grad(): pre = torch.Tensor(history).unsqueeze(0) pred = model(pre) return pred.detach().numpy().reshape(-1)
def n_step_forecast(data: pd.DataFrame, target: str, tw: int, n: int, forecast_from: int=None, plot=False): ''' 多步预测函数。 参数: data: pandas 数据框,包含时间序列数据 target: 目标列名称,表示需要预测的时间序列 tw: 训练窗口大小(训练时所需的历史步数) n: 整数,定义预测未来的步数 forecast_from: 整数,定义从哪个索引开始预测。为 None 时从数据末尾预测 plot: 布尔值,True 表示生成预测结果的可视化图表,False 表示不生成 返回: 包含预测值和实际值的数据框。 ''' history = data[target].copy().to_frame()
if forecast_from: pre = list(history[forecast_from - tw : forecast_from][target].values) else: pre = list(history[target])[-tw:]
for i, step in enumerate(range(n)): pre_ = np.array(pre[-tw:]).reshape(-1, 1) forecast = one_step_forecast(model, pre_).squeeze() pre.append(forecast)
res = history.copy() ls = [np.nan for i in range(len(history))]
if forecast_from: ls[forecast_from : forecast_from + n] = list(np.array(pre[-n:])) res['forecast'] = ls res.columns = ['actual', 'forecast'] else: fc = ls + list(np.array(pre[-n:])) ls = ls + [np.nan for i in range(len(pre[-n:]))] ls[:len(history)] = history[target].values res = pd.DataFrame([ls, fc], index=['actual', 'forecast']).T
return res
让我们从序列的中间不同位置开始进行预测,以便将预测结果与实际发生的情况进行比较。
我们编写的预测器代码可以从任何位置开始预测,并且可以进行任何合理数量的步骤。
红线表示预测结果,请注意,图表中的y轴显示的是归一化价格。
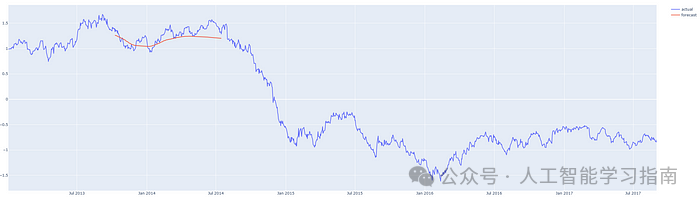
预测从 2013 年第 3 季度开始的 200 天
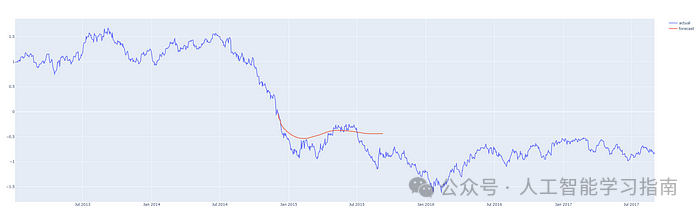
预测从 2014/15 年度开始的 200 天
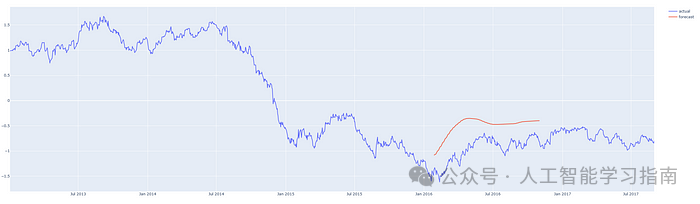
预测从 2016 年第 1 季度开始的 200 天
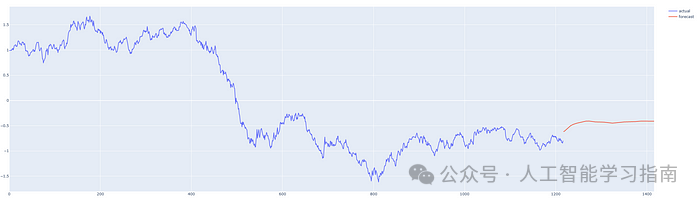
从数据的最后一天开始预测 200 天
而这只是我们尝试的第一个模型配置!如果更多地尝试不同的架构和实现,肯定能让模型训练得更好,预测也更准确。
结论
通过以上步骤,我们拥有了一个可以预测单变量时间序列中接下来会发生什么的模型。
本文只处理了单变量时间序列,即只有一系列单个值,但是,还有方法可以使用多个测量不同事物的序列一起来进行预测,这称为多变量时间序列预测。
这种预测模型真正的魔力在于其LSTM层,以及它作为神经网络的循环层如何处理和记忆序列。
另外我们打磨了一套基于数据与模型方法的 AI科研入门学习方案(已经迭代过 5 次),包含时序、图结构、影像三大实验室,我们会根据你的数据类型来选择合适的实验室,根据规划好的路线学习 只需 5 个月左右(很多同学通过学习已经发表了 sci 二区以下、ei 会议等级别论文)如果需要发高区也有其他形式。

人工智能系统班学习路线
大家感兴趣可以直接添加小助手微信:ai0808q 通过后回复咨询既可!

大家想自学的我还给大家准备了一些机器学习、深度学习、神经网络资料大家可以看看以下文章(文章中提到的资料都打包好了,都可以直接添加小助手获取)
大家觉得这篇文章有帮助的话记得分享给你的死党、闺蜜、同学、朋友、老师、敌蜜!










