作者|腾讯音乐内容信息平台部:张俊、罗雷、李继蓬、代凯 腾讯音乐娱乐拥有丰富的内容曲库,包括录制音乐、现场表演、音频和视频等多种形式。通过技术和数据赋能,腾讯音乐娱乐不断创新产品,为用户提供更优质的体验,提高用户参与度,同时为音乐人和合作伙伴在制作、发行和销售方面提供更大支持。基于公司丰富的音乐内容资产,腾讯音乐将歌曲库、艺人资讯、专辑信息、厂牌信息等大量数据统一存储,形成音乐内容库数据平台,该平台旨在为应用层提供库存盘点、分群画像、指标分析、标签圈选等内容分析服务,高效为业务赋能。
内容库数据平台的数据架构已经从 1.0 版本演进到了 4.0 版本。之前的文章介绍了分析引擎从 ClickHouse 到 Apache Doris 升级实践。本文将重点分享内容搜索引擎从 Elasticsearch 到 Apache Doris 的替换,如何通过一个系统同时满足内容搜索和数据分析的需求,并满足复杂的自定义标签计算的支持。最终,实现存储成本降低 80%,写入性能提升 4 倍的显著效益。
从业务角度来看,腾讯音乐有两个场景需要搜索能力的支持,分别是内容库的百科搜索及内容库的标签圈选。
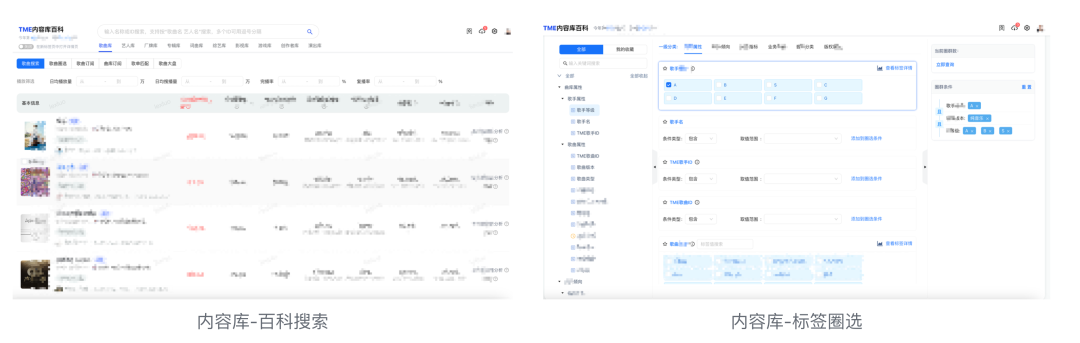
Elasticsearch + Doris 混合架构
在 2.0 版本之前,Doris 暂未推出倒排索引能力,检索能力相对较弱。而 Elasticsearch 在全文检索方面具备优势,能够基于倒排索引快速匹配特定关键词或短语、可对所有字段建立索引,在查询时支持任意组合的过滤条件等。
但是,Elasticsearch 聚合统计分析性能较差,不支持 JOIN 等复杂查询,且存储空间占用较高。这些正是 Apache Doris 所擅长的领域,能够高效处理复杂的统计分析和查询任务,并通过高压缩率优化存储效率。
因此,腾讯音乐构建基于 Elasticsearch 与 Doris 的混合架构,Elasticsearch 负责内容的全文检索和标签圈选,而 Apache Doris 专注于 OLAP 分析。借助 Doris 的 ES catalog 外表查询机制,能够直接查询 Elasticsearch 中数据,实现对外查询接口的统一。
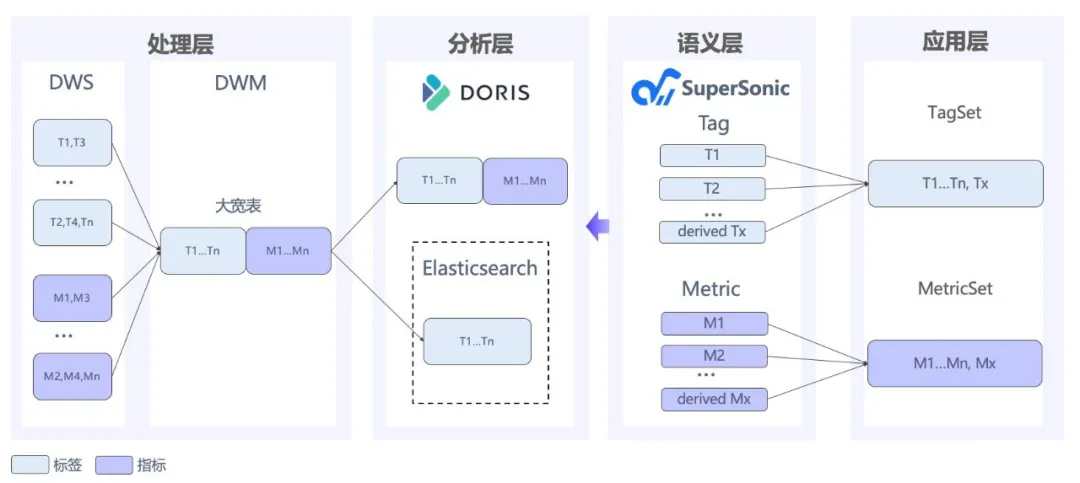
但这套混合架构在应用时,也遇到了一些问题:
存储成本较高:Doris 的引入并没有完全解决存储成本高的问题,Elasticsearch 的存储空间占用仍然显著。
写入性能受限:随着数据量的增长,Elasticsearch 集群的写入压力不断加大,全量写入耗时超过 10 个小时,接近业务可承受极限。
混合架构复杂:Elasticsearch 和 Doris 的混合架构增加了系统和技术栈的维护成本,同时冗余的数据存储也带来了额外费用,两套系统也增加了数据不一致的风险。
因此,腾讯音乐考虑是否可以将搜索引擎统一为 Doris,让其全面负责全文检索、标签圈选以及聚合分析的需求。这样考虑的主要原因是 Apache Doris 自 2.0 版本开始支持倒排索引和全文检索,这使其有能力完全替 Elasticsearch 所负责的部分,获得更好的收益。
在全文检索方面,Doris 不仅支持普通的等值和范围(=, !=, >, >=,
在倒排索引方面,Doris 倒排索引在数据库内核中实现,语法与 SQL 无缝结合,支持多种条件的任意 AND OR NOT 逻辑组合,满足普通过滤以及全文检索组合的复杂需求。如下方示例,WHERE 筛选条件由 5 部分组成,包括全文检索 title MATCH '爱' OR description MATCH_PHRASE '热爱',日期范围过滤 dt BETWEEN '2024-09-10 00:00:00' AND '2024-09-10 23:59:59',数值范围过滤 rating > 4,字符串等值过滤 country = '中国',这些条件通过统一的 SQL 语法无缝组合起来,筛选完之后又按照 actor 进行分组统计,最后对分组统计的 cnt 排序取最高的 100 个结果。
SELECT actor, count() as cnt FROM table1WHERE dt BETWEEN '2024-09-10 00:00:00' AND '2024-09-10 23:59:59' AND (title MATCH '爱'
OR description MATCH_PHRASE '热爱') AND rating > 4 AND country = '中国'GROUP BY actorORDER BY cnt DESC LIMIT 100;
因此,腾讯音乐将 Doris 升级至 2.0 版,将架构从原先的 Elasticsearch + Doris 转变为统一的 Doris 解决方案:
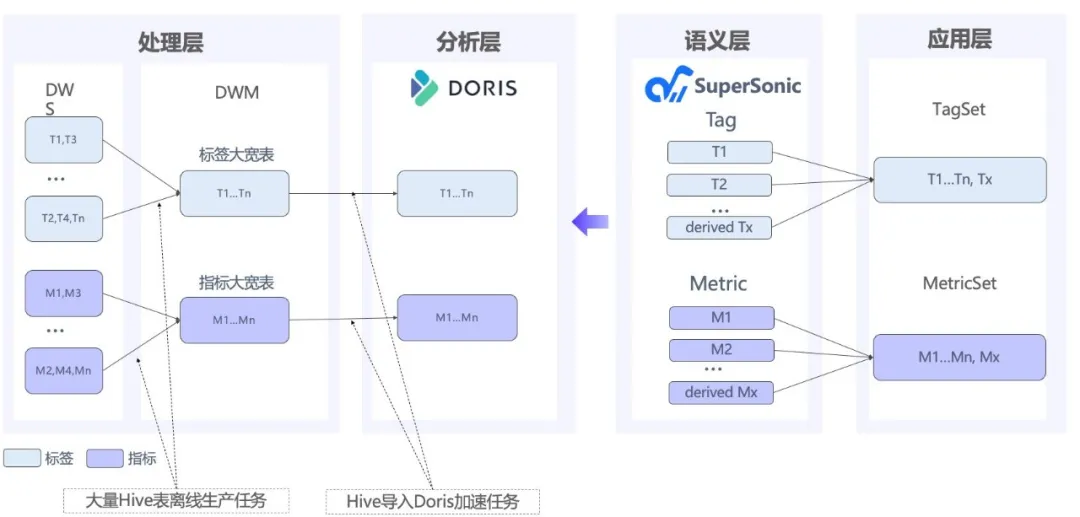
基于 Doris 的统一架构上线后,所带来的收益也非常可观:
在架构统一的过程中,涉及到一些关键设计,接下来将相关方案及经验分享给读者。
在存储结构上采用了维度表与事实表的方案:
参考 Doris 倒排索引的使用文档(https://doris.apache.org/zh-CN/docs/table-design/index/inverted-index),根据 Elasticsearch Mapping 设计了对应的 Doris 的表结构和索引。其中,Elasticsearch 的 Keyword 类型对应 Doris 的 Varchar/String 类型及不分词的倒排索引(USING INVERTED),ES 的 Text 类型对应 Doris 的 Varchar/String 类型及分词倒排索引(USING INVERTED PROPERTIES("parser" = "english/chinese/unicode"))。
CREATE TABLE `tag_baike_zipper_track_dim_string` ( `dayno` date NOT NULL COMMENT '日期', `id` int(11) NOT NULL COMMENT 'id', `a4` varchar(65000) NULL COMMENT 'song_name', `a43` varchar(65000) NULL COMMENT 'zyqk_singer_id', INDEX idx_a4 (`a4`) USING INVERTED PROPERTIES("parser" = "unicode", "support_phrase" = "true") COMMENT '', INDEX idx_a43 (`a43`) USING INVERTED PROPERTIES("parser" = "english") COMMENT '') ENGINE=OLAPUNIQUE KEY(`dayno`, `id`)COMMENT 'OLAP'PARTITION BY RANGE(`dayno`)(PARTITION p99991230 VALUES [('9999-12-30'), ('9999-12-31')))DISTRIBUTED BY HASH(`id`) BUCKETS autoPROPERTIES (...);
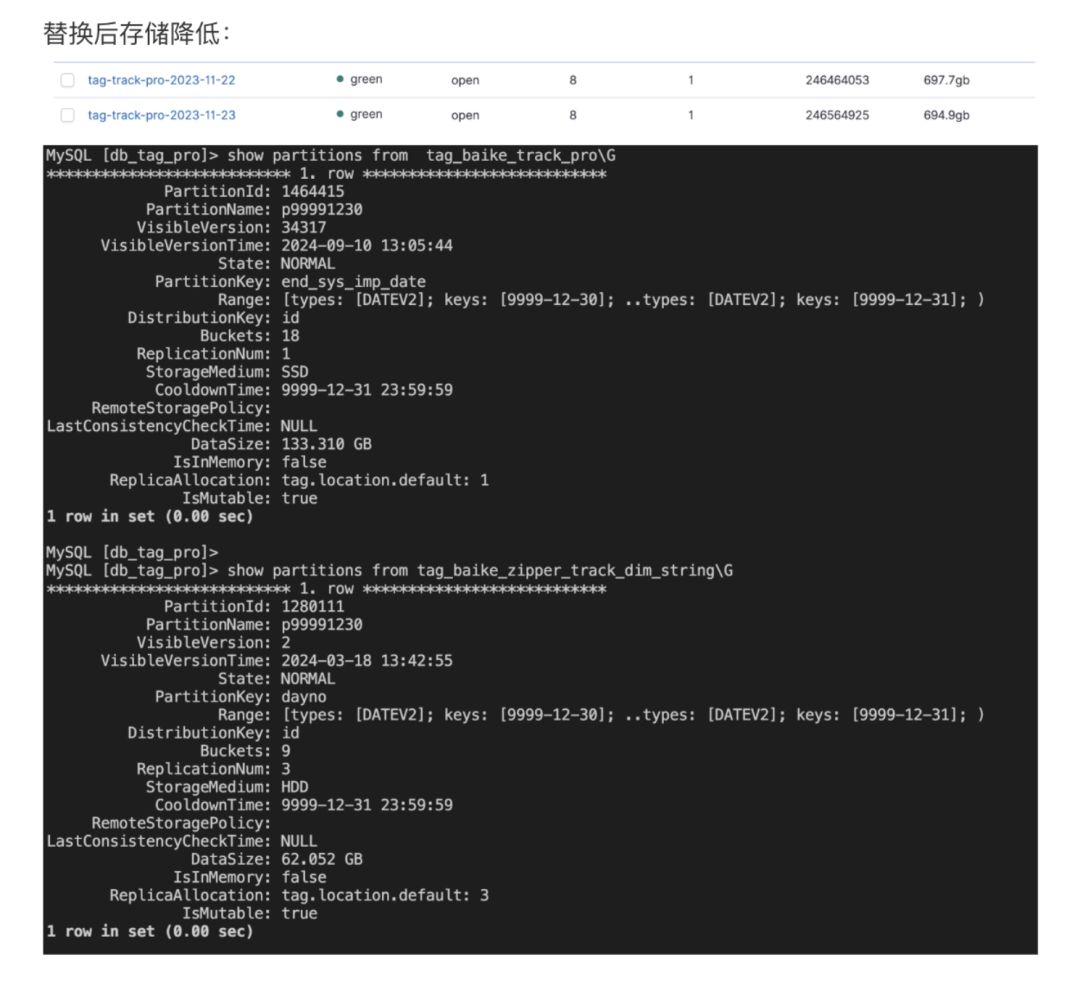
使用 Doris 倒排索引的前后对比:
使用前:以下方复杂查询为例,在使用 Doris 倒排索引之前,该查询运行较慢、响应级别为分钟级。
SELECT * FROM db_tag_pro.tag_track_pro_3 WHERE dayno='2024-08-01' AND ( concat('#',a4,'#') like '%#若月亮还没来#%' or concat('#',a43,'#') like '%#1000#%')
SELECT * FROM ( SELECT tab1.*,a4_single,a43_single FROM ( SELECT * FROM db_tag_pro.tag_track_pro_3 WHERE dayno='2024-08-01' ) tab1 lateral view explode_split(a4, '#') tmp1 as a4_single lateral view explode_split(a43, '#') tmp2 as a43_single ) tab2 where a4_single='若月亮还没来' or a43_single='1000'
使用后:使用 Doris 倒排索引之后,查询过程显著简化,运行速度极大提升,响应时间从分钟级缩短至秒级别。
SELECT id FROM db_tag_pro.tag_baike_zipper_track_dim_string WHERE( a4 MATCH_PHRASE '若月亮还没来' OR a43 MATCH_ALL '1000' ) AND dayno ='2024-08-01'
SELECT * FROM db_tag_pro.tag_baike_track_pro WHERE id IN ( 563559286 )
不仅如此,原来在 Elasticsearch 中由于语句过长而无法查询的复杂自定义标签,在 Doris 内能够更好的支持,Doris 能够处理更长的 SQL 语句。并且在同一个引擎内,可以通过物化视图和 BITMAP 类型轻松对查询后的中间结果进一步优化,避免了不同引擎之间的跨网络同步。
为了确保业务侧使用体验和成本可控,我们采用了 Doris 的资源隔离机制进行业务间的资源管理。
第一层:物理隔离(Resource Group)。将集群划分为两个资源组:Core 和 Common,以服务不同重要场景的需求。Core 组专注于内容搜索和标签圈选的核心需求,而 Common 组则处理其他普通需求。通过在节点层面实施物理隔离,可确保核心业务不受其他业务的影响。
第二层:逻辑隔离(Workload Group)。在每个物理隔离内部,通过 Workload Group 对每个 Resource Group 进行逻辑资源的细分。例如,在普通集群中建立多个 Workload Group,并为用户指定默认的 Workload Group,以防止单个用户占满整个集群的资源。
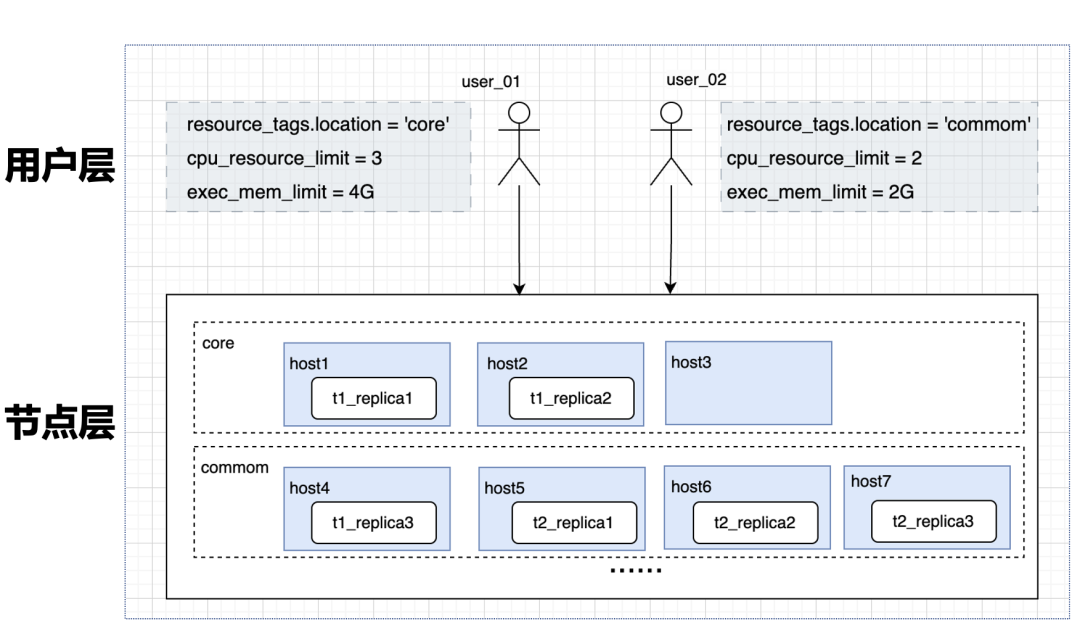
上述资源隔离机制显著提升了系统的稳定性,告警频率从每天 20 多次降低到每月个位数。这不仅保障了业务的可靠性,还减轻了团队运维管理压力,使他们能够将更多时间投入到系统优化中。
腾讯音乐自研的 SuperSonic 项目内置了 Headless BI 功能,其核心理念是将数据建模、管理和消费进行解耦。通过这种架构,业务分析师只需在 Headless BI 平台上定义指标和标签,而无需关心底层数据源的具体实现。
在业务迁移过程中,业务团队通过 SuperSonic Headless BI 进行。利用转换工具将 DSL 转换为 Elasticsearch SQL 查询,只需切换已定义指标和标签所对应的数据源即可。由于 Headless BI 屏蔽了底层不同数据存储和分析引擎的差异,业务方能够实现无感知的迁移。
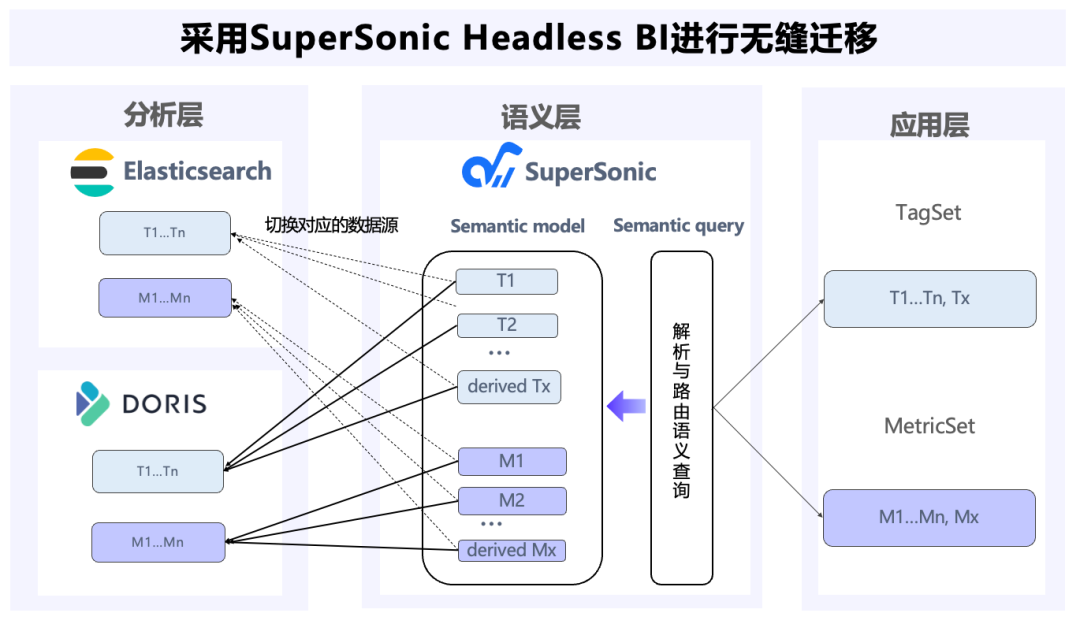
Headless BI 架构不仅实现了数据源的无缝迁移,还大大简化了数据管理和查询的复杂性。SuperSonic 将 Chat BI 与 Headless BI 融合,使用户能够实现统一的数据治理,并通过自然语言进行数据分析。经过腾讯音乐的自主研发和实际应用,SuperSonic 平台现已开源,欢迎感兴趣的同仁使用与共同建设。
GitHub 地址:https://github.com/tencentmusic/supersonic
借助 Doris 替代 Elasticsearch 集群,腾讯音乐统一了搜索和分析引擎。基于倒排索引和全文检索的能力,支持复杂的自定义标签计算,满足秒级响应需求。此外,写入性能提升了 4 倍,存储空间减少了 72%,使用成本节省达 80%。
未来,腾讯音乐将与 Apache Doris 深度合作,探索更多特性在场景应用中的可能性,包括引入 3.0 版本的存算分离,以进一步降低成本。











