
这8个深度学习模型包含了人工智能领域的最前沿技术,涵盖了文本处理、视觉任务、目标检测、图像分割、序列数据处理 等多个方面。
通过引入新的架构、算法和机制,显著提升了模型的性能、效率和适用性。
这些模型不仅推动了深度学习领域的发展,也为交叉学科的研究提供了新的思路和方法。
这些模型论文及变体论文我都帮大家下载好了
大家可以任意添加一位小助手获取,记得发送文章标题截图给小助手哦!


Mamba:
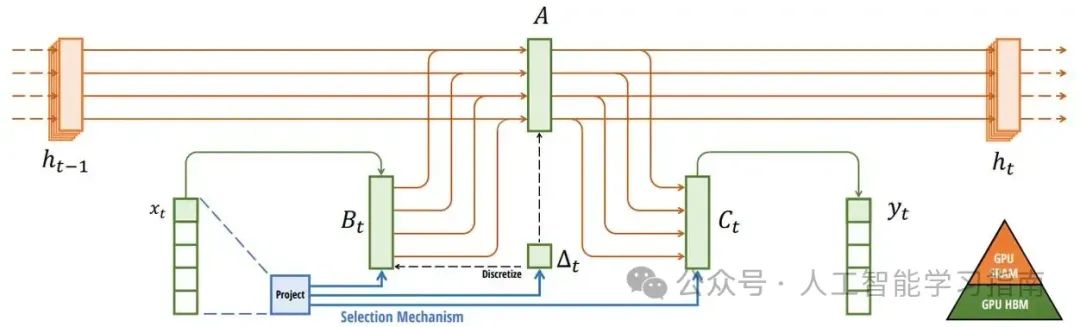
特点:Mamba模型结合了线性层、门控和选择性结构化状态空间模型,解决了Transformer在长序列处理中的效率问题。其核心是选择性机制,能有效压缩和过滤上下文信息,硬件算法通过扫描而非卷积,显著提高了计算速度。
应用方向:适用于需要高效处理长序列数据的场景,如生物信息学中的DNA序列处理、视频内容生成与推理、文学创作中的长篇小说撰写等。
Transformer:
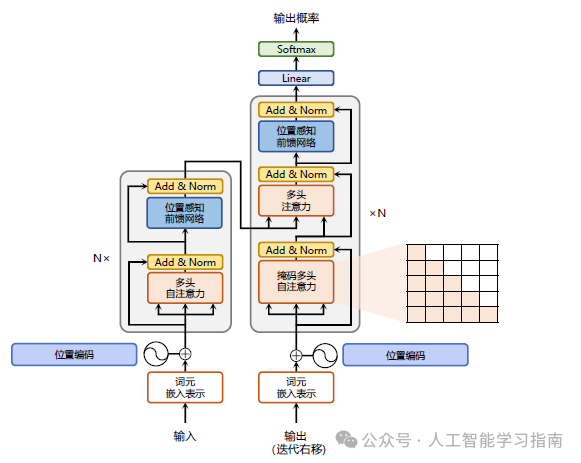
特点:Transformer架构的核心是自注意力机制,这使得模型能够在处理输入序列时同时考虑所有位置的信息。Transformer具有高效的并行计算能力,突破了RNN模型不能并行计算的限制。此外,Transformer架构易于扩展,可以通过增加模型层数和调整模型大小来提升性能。
应用方向:广泛应用于自然语言处理领域,如机器翻译、问答系统、文本生成等,同时也扩展到计算机视觉和语音识别等领域。
YOLO:
特点:YOLO是一种流行的目标检测算法,通过单次前向传播预测图像中的边界框和类别概率。YOLOv1将图像分为网格,每个网格预测多个边界框和类别,后续版本如YOLOv2和YOLOv3进一步提高了准确性和性能。
应用方向:适用于实时目标检测任务,如安防监控、自动驾驶、工业自动化、零售分析、无人机、医疗影像分析和增强现实等。
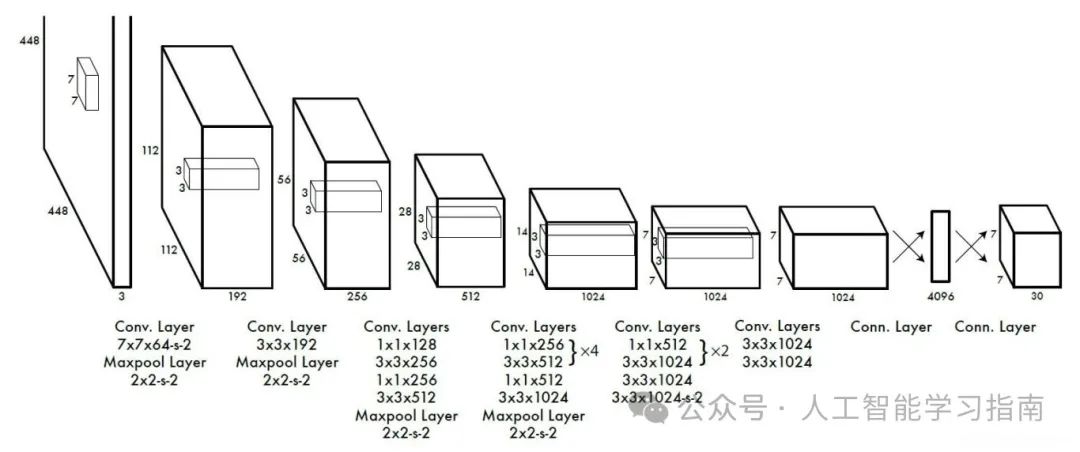
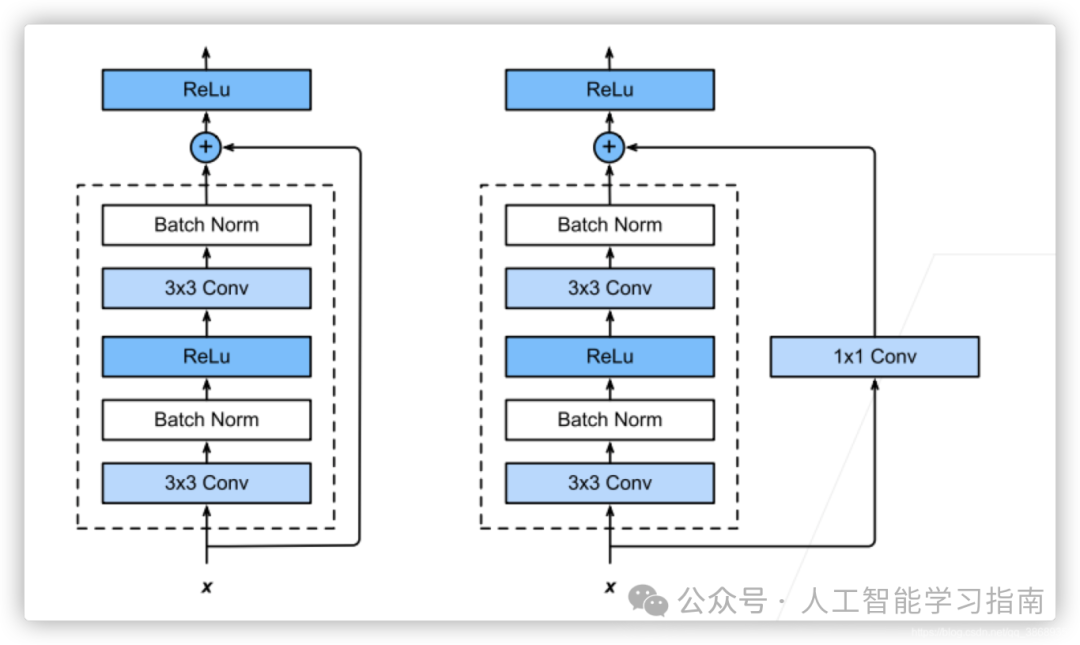
ResNet:
特点:ResNet是一种CNN,用于解决深度网络中的梯度消失问题。其架构允许网络学习多层特征,避免陷入局部最小值。ResNet通过引入残差连接,实现将输入直接传递到输出,使网络能够有效地学习函数,同时提高了网络的训练效率。
应用方向:主要用于图像分类、目标检测、图像分割等计算机视觉任务,也适用于其他需要处理复杂图像数据的场景。
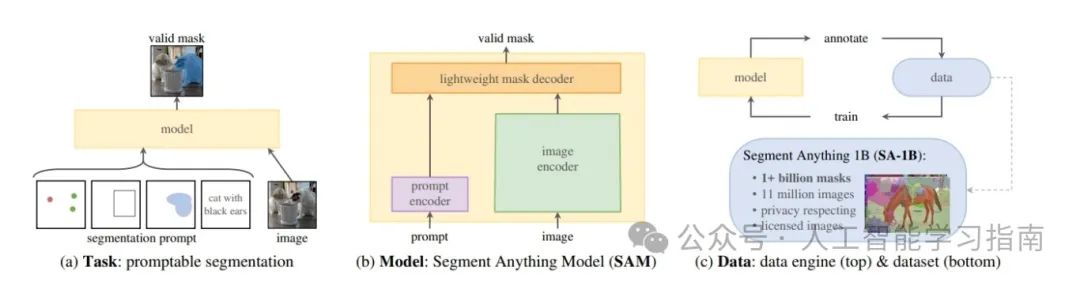
SAM:
特点:SAM(Segment Anything Model)是Facebook Research团队开发的一项先进的图像分割技术。它通过使用深度学习模型,能够识别并分割出图像中的各个物体。SAM支持多种交互方式,如鼠标悬停、点击、框选和全图分割,实现了高精度的图像分割。
应用方向:适用于计算机视觉中的图像和视频物体分割任务,也适用于遥感图像分析、医学图像分析等需要高精度图像分割的场景。
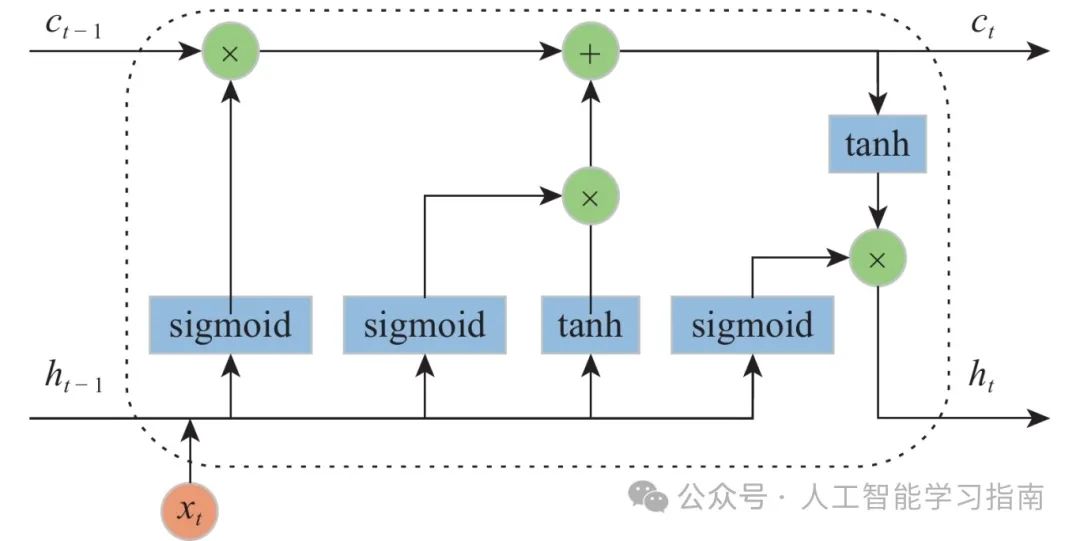
LSTM:
特点:LSTM(Long Short-Term Memory)是一种特殊类型的递归神经网络(RNN),专门用于解决传统RNN在处理长序列时遇到的梯度消失和梯度爆炸问题。LSTM通过引入记忆单元和门控机制,控制信息的流动,从而能够更好地捕捉长时间跨度的依赖关系。
应用方向:适用于处理时空序列数据的场景,如语音识别、自然语言处理、时间序列预测、视频处理等。
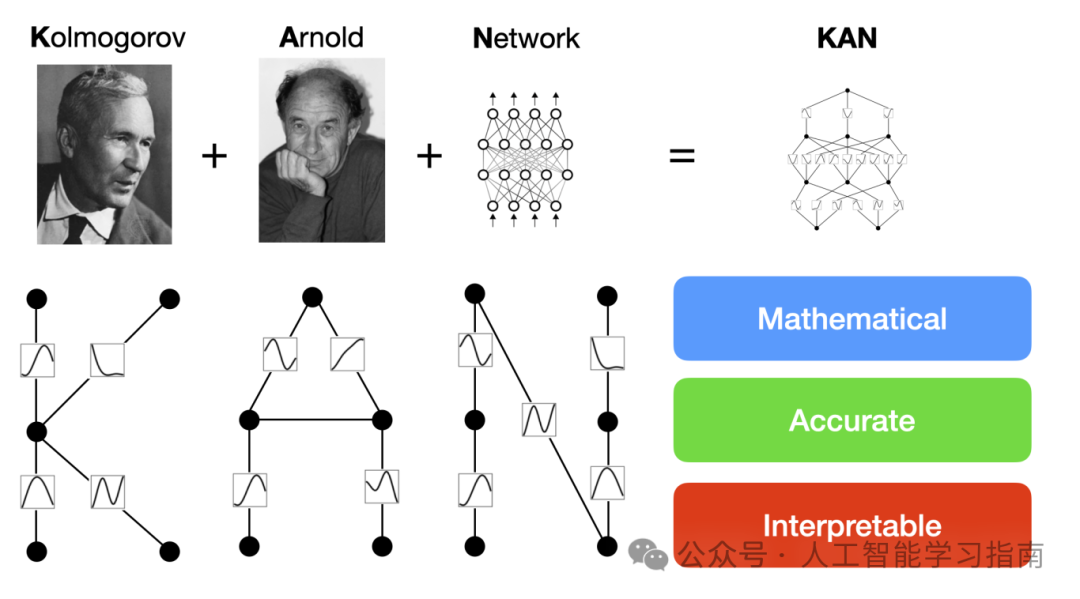
KAN:
特点:KAN(Kolmogorov-Arnold Networks)的设计基于Kolmogorov-Arnold表示定理,具有强大的表达能力。KAN将可学习的激活函数放在权重上,而不是神经元上,这种设计思路可以带来更高的参数效率和更好的学习能力。KAN还表现出比MLP更优的神经缩放律,意味着随着模型参数数量的增加,KAN的性能提升更加显著。
应用方向:适用于需要强推理能力的场景,如问答系统、推荐系统、知识推理等。
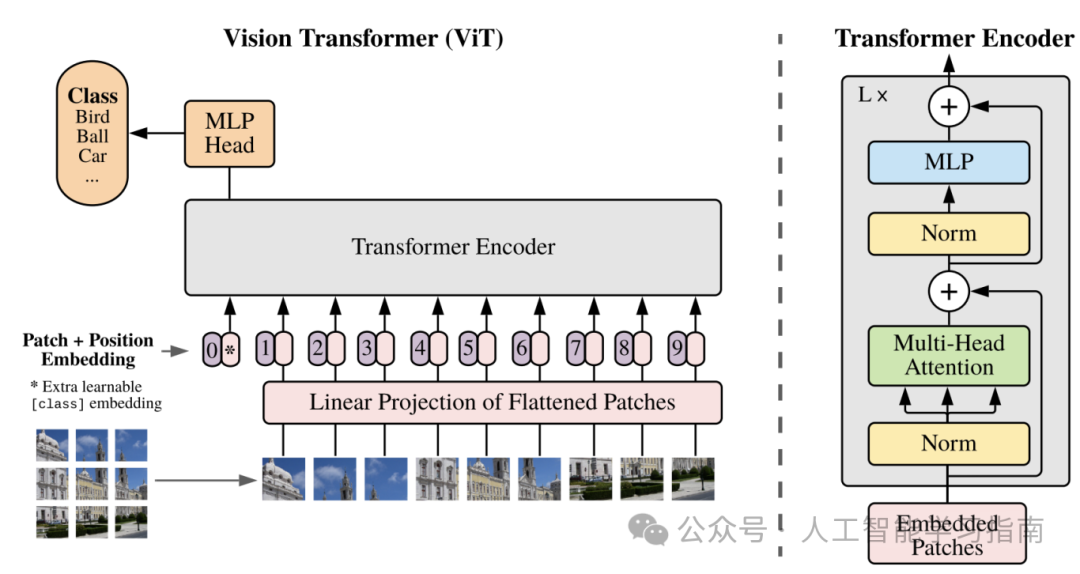
ViT:
特点:ViT(Vision Transformer)将Transformer架构扩展到计算机视觉任务中,如视频处理、目标检测等。ViT通过将图像分割成小块并作为序列输入到Transformer中,实现了对图像
的有效处理。
应用方向:适用于视频处理、目标检测、图像分类等更广泛的计算机视觉任务。
如果大家想更进一步学习机器学习、深度学习、神经网络技术的可以看看以下文章(文章中提到的资料都打包好了,都可以直接添加小助手获取)
大家觉得这篇文章有帮助的话记得分享给你的朋友、同学、闺蜜、敌蜜、死党!










