随着近些年来NLP领域研究的不断深入,我们逐渐发现,Transformer架构中出现的幻觉问题,以及各种下游任务中的性能不足,都或多或少与注意力缺陷有关。
虽然上下文窗口可以扩展,但是Transformer还是无法真正关注到有价值的信息。
最近,微软研究院和清华大学的研究人员共同提出了一种新的模型架构——Differential Transformer,不仅保留了原始Transformer中的可扩展性,也能让模型更加关注上下文中与任务相关的关键信息。
实验表明,注意力机制的改进,不仅显著提升了检索精度,还能缓解LLM的幻觉。

论文地址:https://arxiv.org/abs/2410.05258
Transformer的困境
众所周知,Transformer的核心是注意力机制,采用softmax函数来衡量序列中各种标记的重要性。然而,最近的研究表明,LLM难以从上下文中准确到检索关键信息。
比如去年斯坦福Percy Liang团队的一篇论文就指出,虽然语言模型能够接受较长的上下文作为输入,但并不能稳健地利用长输入上下文中的信息。

论文地址:https://arxiv.org/abs/2307.03172
比如,实验中发现,仅仅改变关键信息在文档中的出现位置,就可以造成GPT-3.5 Turbo检索性能的大范围波动。
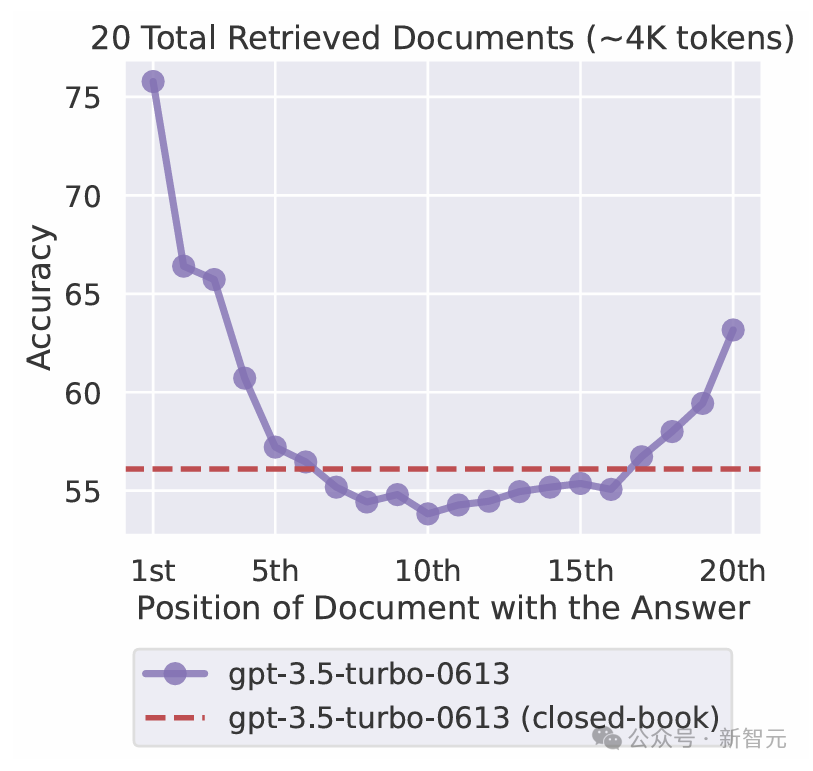
此外,本篇论文的实验结果证明,Transformer经常过度关注不相关的上下文,本文将其称之为「注意力噪声」。
如图1(左)所示,模型分配给正确答案的注意力分数很低,同时不成比例地关注不相关的上下文,这意味着信噪比很低,最终淹没了正确答案。
由此看来,我们对于LLM检索、利用长上下文的过程,知之甚少,其注意力过程也需要更多的改进。
本文所提出的Differential Transformer(DIFF Transformer)正是希望用「差分注意力」(differential attention)机制消除注意力噪声,促使模型关注上下文中的关键信息。
图1的对比结果可以看出,DIFF Transformer给出的注意力分数的分布明显不同于传统Transformer架构,给予关键信息更高的注意力分数,进而显著提升了检索能力。
这种能力的提升,对于有效利用LLM的长上下文窗口、缓解幻觉、关键信息检索等方面都有重要的意义。
模型架构
DIFF Transformer也可以用于纯Encoder或Encoder-Decoder模型,但本篇论文以纯Decoder模型为例进行描述。
整个模型由L个DIFF Transformer层堆叠而成,每层由一个差分注意力模块和前馈网络模块连接形成。
宏观布局类似于传统Transformer架构,但主要区别在于修改了注意力的softmax过程,并且采用了pre-RMSNorm、SwiGLU等改进。
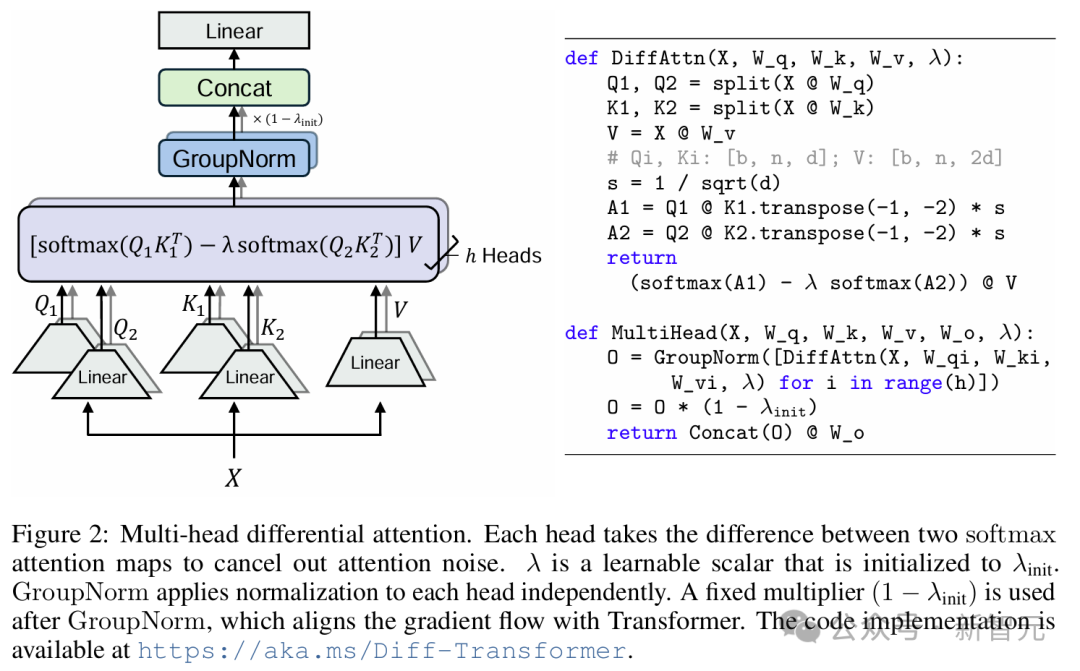
差分注意力
该模块的结构示意图和伪代码如图2所示,具体的代码实现可参考项目GitHub。
代码地址:https://github.com/microsoft/unilm/tree/master/Diff-Transformer
除了传统注意力中的权重矩阵W^Q、W^K、W^V ∈ ℝ^{d_model×2d},模块中还加入了可学习标量λ。
具体来说,给定输入序列X ∈ ℝ^{N×d_model},首先将其投影为Q、K、V矩阵Q_1,Q_2,K_1,K_2 ∈ ℝ^{N×d} , V ∈ ℝ^{N×2d},然后是差分注意力算子DiffAttn(·)通过公式(1)计算输出:
λ被初始化为常量λ_{init} ∈ (0,1),并依照公式(2)与其他权重参数同步更新:
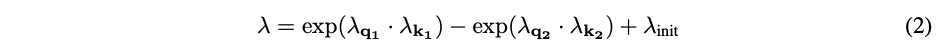
其中,λ_ , λ_ , λ_ , λ_ ∈ ℝ^d也都是是可学习向量。
之所以命名为「差分注意力」,是指两个softmax函数间的差异可以消除注意力噪音。
这个想法类似于电气工程中提出的差分放大器(differential amplifiler),将两个信号之间的差异作为输出,从而消除输入中的共模噪声;降噪耳机的设计也是基于类似的思路。
DIFF Transformer中也可以使用多头注意力机制,在同一层的多个head间共享参数λ,将每个head的输出进行归一化处理后再拼接、投影,就得到了最终输出,如公式(3)所示。
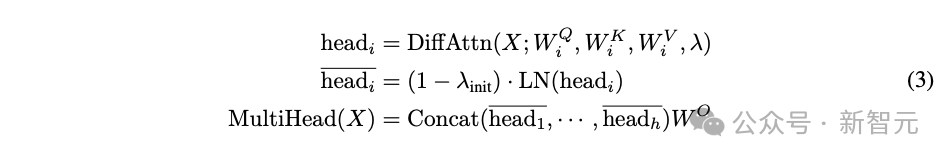
公式(3)中的LN(·)是指对每个头使用RMSNorm,但如图2(左)所示,也可以使用GroupNorm。
加上前馈网络模块,每个DIFF Transformer层就可以描述为:

实验
下游任务
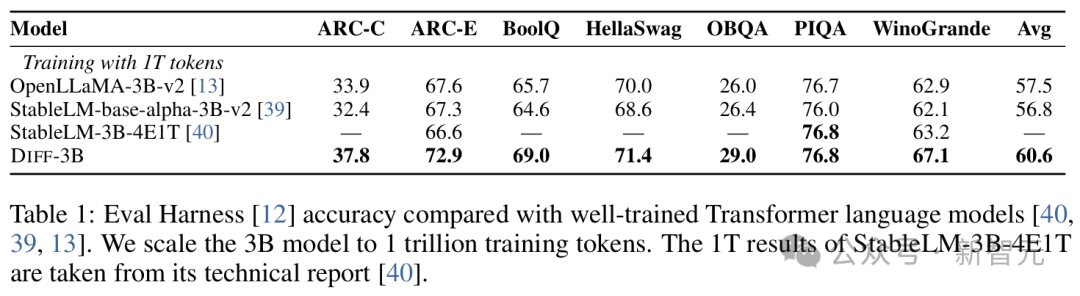
首先,研究人员在1T token上训练3B大小的DIFF Transformer模型,并在各种下游任务上与之前有竞争力的Transformer架构模型进行比较,结果如表1所示。
基线模型大小都为3B,其中,StableLM-3B-4E1T的1T结果取自技术报告,而OpenLLaMA-v2-3B和StableLM-base-alpha-3B-v2同样使用1T数据训练,表中分数为Eval Harness基准测试上的零样本准确率。
结果显示,与之前经过精心调优的Transformer语言模型相比,DIFF Transformer取得了良好的性能。
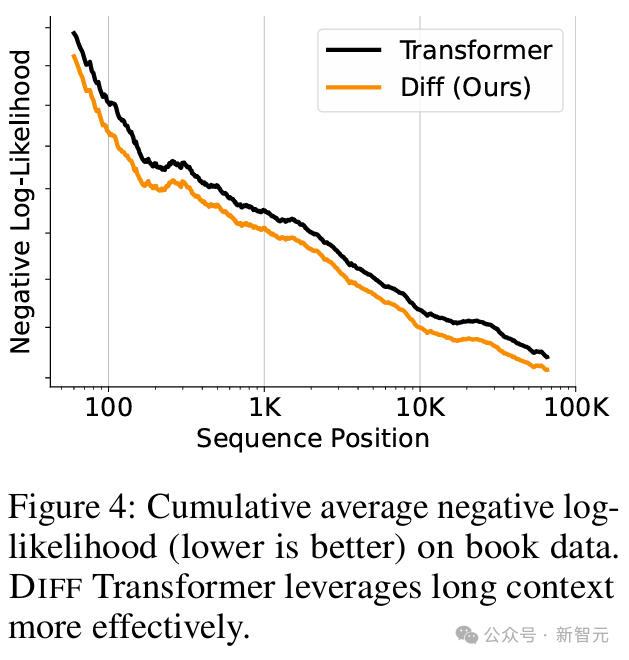
尤其是对于长上下文任务,如图4所示,随着上下文长度不断增加,累计平均的负对数似然值(NLL)持续降低,说明Diff Transformer可以更有效地利用不断增加的上下文。
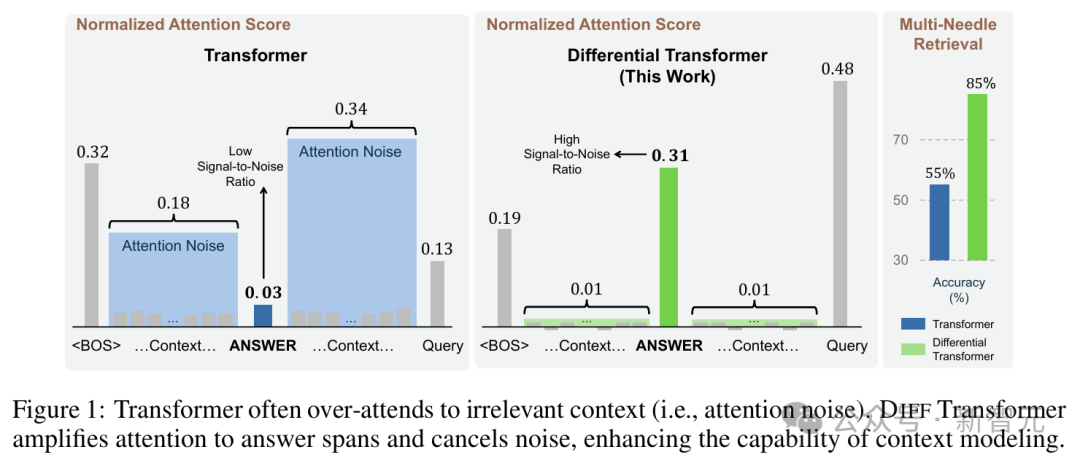
关键信息检索
「大海捞针」(Needle-In-A-Haystack)测试被广泛用于评估LLM提取长上下文中的关键信息的能力。
本文的实验遵循LWM和Gemini 1.5的「多针」评估方案,在不同长度的上下文中,N根针被插入不同的深度。每根「针」都由一个简洁的句子组成,为特定城市分配一个独特的魔法数字。
答案针被放置在上下文中的5个不同深度:0%、25%、50%、75%和100%,同时随机放置其他分散注意力的针。待测LLM的目标,就是是检索与查询城市相对应的数字。
4k上下文检索的可结果如表2所示。虽然两种模型在N=1或N=2时都取得了良好的准确率,但随着N的增加,DIFF Transformer的性能保持相对一致,Transformer则显著下降。
 4K长度的平均检索精度,N代表针数,R表示查询城市的数量
4K长度的平均检索精度,N代表针数,R表示查询城市的数量将上下文长度扩展至64k时,差距就更加明显,尤其是关键信息位于前半部分时(即0%、25% 和 50%深度)。
特别是,将针放置在25%深度时,DIFF Transformer相对于传统Transformer实现了76%的精度提升。
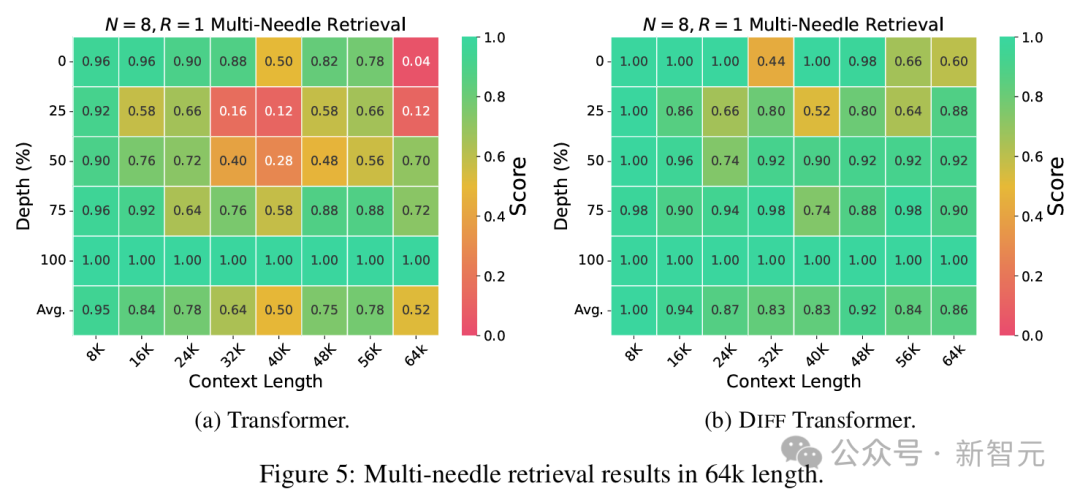
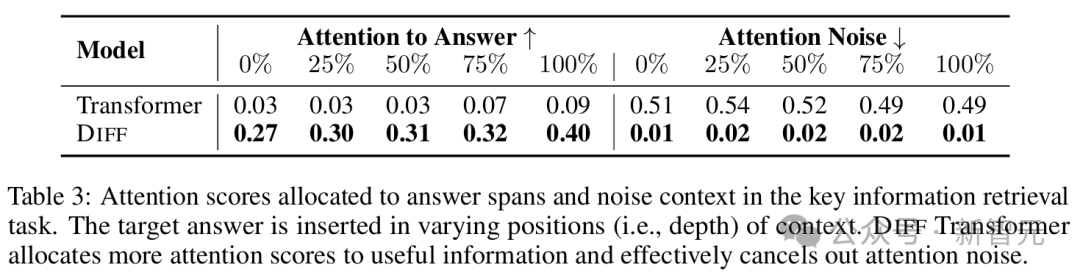
除了检索精度,表3进一步分析了两种模型为上下文分配的注意力分数。可以看出, DIFF Transformer的确将更多的注意力分配给了有用的信息,并有效地消除注意力噪声。
值得注意的是,DIFF Transformer在提升检索精度的同时也缓解了幻觉现象。
实验包含模型在总结(图4a)和问答(图4b)两种任务上的幻觉评估。可以发现,与Transformer相比,DIFF Transformer的上下文幻觉明显减轻。
这种性能的提高可能源于,改进后的注意力模块能更好第关注任务所需信息,而非不相关的上下文。
这与之前研究中的观察结果一致,即Transformer出现上下文幻觉的一个主要原因是注意力分数的错误分配。
 对文本摘要和问题回答的幻觉评估。准确度越高表示幻觉越少;评估时采用GPT-4o进行自动化的二元判断
对文本摘要和问题回答的幻觉评估。准确度越高表示幻觉越少;评估时采用GPT-4o进行自动化的二元判断缩放特性
除了下游任务性能,论文还进行了缩放特性的对比。
扩展模型规模
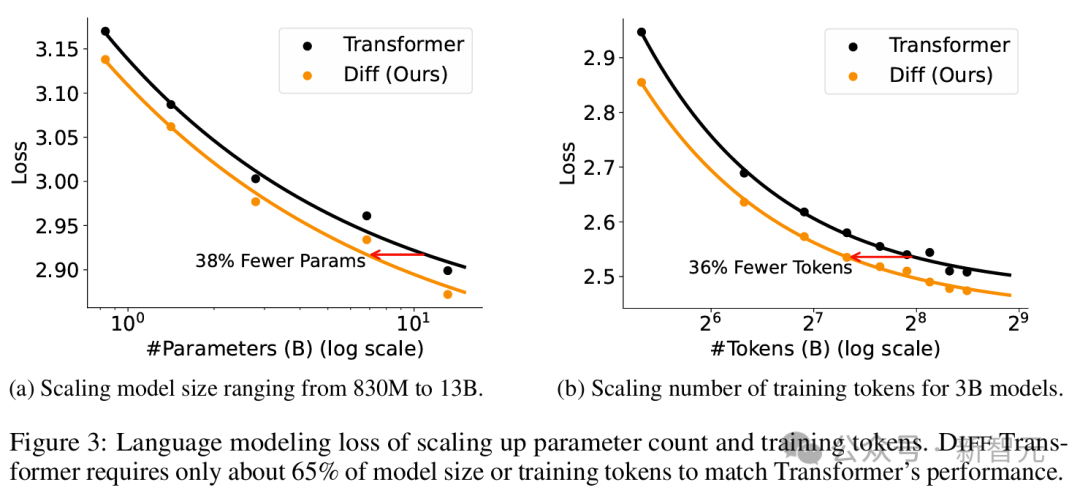
如图3a所示,分别使用830M、1.4B、2.8B、6.8B和13.1B参数训练语言模型,发现DIFF Transformer依旧遵循Scaling Law。
根据拟合曲线,68亿参数规模的DIFF Transformer达到了与110亿参数规模Transformer相当的验证损失,但仅需62.2%的参数。
同样,78亿参数的DIFF Transformer匹配了131亿参数的Transformer的性能,参数量是后者的59.5%。
扩展训练Token
如图3b所示,训练数据的缩放也遵循类似规律,且拟合曲线表明,使用160B token训练的DIFF Transformer达到了与使用251B token训练的Transformer相当的性能,但仅消耗了63.7%的训练数据。
此外,在HellaSwag上的测试结果还可以发现,Diff Transformer对量化和位宽的稳健性显著高于Transformer。

作者介绍
本文的4位共同一作都来自微软研究院,其中两位是清华大学学生。
Tianzhu Ye
Tianzhu Ye本科毕业于清华大学自动化系,今年刚刚进入本系就读博士一年级,目前是微软自然语言计算部门实习生。
Li Dong(董力)

Li Dong从2018年起担任MSRA自然语言计算组的首席研究员。他2012年毕业于北京航空航天大学,获得了计算机科学与工程方向的学士和硕士学位,之后前往爱丁堡大学攻读信息学博士,曾在微软Redmond研究院自然语言处理组实习。
Yuqing Xia(夏雨晴)

Yuqing Xia是微软亚洲研究院(MSRA)系统与网络研究组的研究员,此前于2019年在北京大学获得了生物学博士学位她的研究方向是利用现代硬件技术为计算密集型任务(如机器学习和深度学习)构建大规模计算系统。此外,她还对如何运用人工智能来推动自然科学(尤其是生物学)的研究进展抱有浓厚兴趣。
Yutao Sun(孙宇涛)

Yutao Sun是清华大学的一年级博士生,导师是王建勇。同时,他也在微软亚洲研究院实习,由董力指导。他的研究兴趣是大语言模型的骨干网络、长序列的建模和推理,以及大语言模型在其他领域的应用。
参考资料:
https://arxiv.org/abs/2410.05258










