
人工智能(AI)已经成为作者日常生活中不可或缺的部分。计算机视觉已经发展到了能够检测智能交通系统中路口行人的安全关键角色,并提醒车辆注意潜在碰撞的程度。集中的计算分析摄像头反馈并生成附近车辆的警报。
然而,实时应用面临延迟、数据传输速度有限和生命损失的风险。边缘服务器为实时应用提供了潜在的解决方案,它们提供本地计算和存储资源以及较低的响应时间。然而,边缘服务器的处理能力有限。轻量级深度学习(DL)技术使边缘服务器能够利用压缩的深度神经网络(DNN)模型。
本研究探索在人工智能物联网(AIoT)边缘设备上实现轻量级dl模型。一个优化的You Only Look Once(YOLO)基于的dl模型被用于实时行人检测,使用Message Queuing Telemetry Transport(MQTT)协议将检测事件传输到边缘服务器。
仿真结果表明,优化的YOLO模型可以实现实时行人检测,推理速度为147毫秒,帧率为2.3帧/秒,准确性为78%,相较于 Baseline 模型取得了显著的改善。
I Introduction
AI已成为日常生活中不可或缺的一部分,因为它能够根据经验数据进行学习和适应。它在各种领域找到了应用,如医学、治理、金融、通信和交通等。机器学习(ML)提供了一种洞察和解决日益复杂的AI环境和要求的方法。然而,ML通常需要手调优的特征才能发挥良好性能。相比之下,深度学习(DL)可以自动使用通用学习过程从视觉输入中提取潜在特征[1]。
DL有几个应用,其中之一是计算机视觉,其中DL模型根据视觉输入提取类似人类视觉理解的高 Level 信息和特征。与计算机视觉相关的领域包括目标检测、图像分割、视频跟踪、物体识别和运动估计。目标检测和视频跟踪可以协同工作来执行行人检测。行人检测对于智能交通系统和自动驾驶车辆至关重要,因此它已经引起了公司和政府的关注和投资[2][3][4]。
根据中国台湾交通部的交通事故数据[5],2021年,台湾发生了16,649起涉及行人的交通事故。在这些事故中,大约90%的人受伤,410人死亡。在人口密集的国家,这组数据令人担忧。虽然许多因素可能导致事故,但最常见的原因是人类错误。由于行人或驾驶员的疏忽,如分心,可能导致人
Research Contributions
在这项研究中,作者设计了一种可在边缘设备上部署的计算机视觉基础的轻量级深度学习模型,用于行人检测。作者使用一种新颖的方法来检测和定位目标。然后作者对模型进行训练和评估,使其变得更轻量级,并将结果与其他 Baseline 模型进行比较。最后,作者将模型部署在边缘设备(Nvidia Jetson Nano)上,以测试模型在实时场景中的能力。
本研究的贡献如下:
- 作者设计了一种可以在廉价边缘设备上部署的轻量级深度学习模型,用于实时检测行人流量。
- 作者开发了一种可以在低带宽环境中运行的边缘AI系统,通过传输感兴趣的信息。
- 作者将作者的模型与其他流行的非YOLO模型进行了比较,并证明了其他模型需要至少3倍的计算能力(超过2倍的内存)才能达到相似的准确性指标。
Research Organization
在第II部分,作者介绍了相关工作。在第III部分,作者提出了系统模型和提出的算法。在SSIV部分,作者讨论了仿真设置和拓扑。然后,在第V部分,作者呈现了仿真结果和分析。最后,在第VI部分,作者阐述了研究结论和未来研究方向。
II Related Works
行人检测是计算机视觉领域的一个问题,涉及在图像或视频序列中识别行人的存在,同时忽略其他目标。行人检测算法可以分为两大类:手工提取特征,如提取不同颜色和梯度通道等;深度学习(DL),如使用卷积神经网络(CNN)等。手工提取特征的方法使用捕捉行人视觉特徵的特征,如形状、纹理和颜色。
这些特征然后输入分类器,如支持向量机(SVM),以在图像中区分行人和非行人区域。另一方面,DL基础方法使用CNN自动学习从图像的原始像素值中区分特征。这些特征然后用于将图像中的每个区域分类为行人或非行人。这两种算法通常包括两个主要阶段:候选目标生成和分类。候选目标生成涉及在图像中生成一组可能包含行人的区域。
滑动窗口或区域建议方法,如选择性搜索或基于区域的CNN(R-CNN)等,有助于行人检测。分类则涉及确定每个候选区域是否含有行人,使用用于手工提取或DL基础特征的分类器。
Handcrafted Features based Pedestrian Detection
在行人检测的早期发展阶段,各种手工特征被广泛使用。手工特征主要包括颜色、纹理或边缘的变异[24]。在行人检测中最常用的手工特征是直方图梯度(HOG)。它的普及率主要归功于它可以从背景图像中提取特定形状的能力。用于HOG的算法可以通过在重叠的单元格网格上滑动检测窗口来形成一个块,称为HOG特征向量[25]。手工特征通常被输入到像SVM这样的ML算法[26],增强算法[27]等。在中,采用HOG特征提取的各种方法与SVM分类器一起使用。而在[14]中,将HOG特征作为 AdaBoost 和 SVM 分类器的融合模型训练数据。
由于实时应用的日益增长以及计算机处理能力的提高,由于手工特征方法的灵活性较低,因为它们需要搜索整个图像以在不同的位置和规模检测目标,这使得模型速度慢且不实用。新的方法依赖于深度学习(DL),因为它认为可以独立生成特征,因此不需要依赖手工特征生成。因此,DL模型被认为是更快更灵活的。
Deep Learning based pedestrian detection
随着AI的发展,深度学习(DL)模型被用于各种计算机视觉任务,如图像分类[31][32],语义分割[33][34],以及目标检测[21][22]等。根据DL模型在各种计算机视觉任务中的能力,近年来开发了用于行人检测问题的DL模型。DL基础的行人检测可以分为两类:混合式行人检测和全DL基础行人检测。
在混合式行人检测中,DL模型使用卷积神经网络(CNN)从输入图像中以预定的步长提取特征。基于步长,CNN产生一个包含被分类为阳性类(包含目标)或阴性类的特征的检测窗口。提取的特征用于训练一个浅层分类器,如支持向量机(SVM)或Boosting算法。在[35]中,作者利用CNN收集的特征训练了一个增强算法。而在[36]和[37]中,区域 Proposal 网络1被提出[22],通过一个浅层网络进行优化以改进检测结果。
在全DL基础行人检测中,DL模型通过端到端训练学习如何执行特征提取和如何检测和分类结果。这个步骤通常包括训练 Backbone 网络,通常是使用反向传播方法,通过将输出层的误差从网络中反向传播来调整每个神经元在每个层的重量。误差计算方法为预测值与实际值之间的差。然后,使用梯度下降调整每个层中每个神经元的权重;
因此,CNN可以自动提取特征。接下来,生成候选区域(在图像中可能包含物体的候选区域),在这种情况下,行人。这个过程可以使用滑动窗口技术[21]或区域 Proposal 网络[36]。然后,CNN将前一步生成的每个候选区域的类别从不同类中分类,通常是一个包含目标的类别。最后一步是应用后处理技术,如非极大值抑制[38],按置信度对检测边界框进行排序,表示框中包含感兴趣物体的可能性。然后,从分数最高的起始边框开始,将其与尚未抑制的所有其他框进行比较。如果两个框之间的交点,通过它们的交集与并集的比值测量,高于某个阈值,则较低分数的框被抑制。作者重复这个过程,直到没有更多的框可以抑制。这一阈值通常设置为0.5,所以当两个框的交集通过它们的交集与并集的比值测量,大于50%时,作者将其视为重复并抑制具有较低置信度的那个框。
虽然混合式方法可以实现良好的检测性能,但由于它们依赖于手工制作的特征和分离的 Proposal 生成和分类步骤,所以通常比DL基础方法慢。此外,混合式方法需要比端到端训练的DL模型进行更多的手动参数调整。
在DL基础方法中,CNN被端到端训练,以学习特征提取和分类步骤。CNN从输入图像中直接生成 Proposal ,并使用相同的CNN将每个 Proposal 分类为包含行人或不含行人。这种方法消除了对手工制作特征的需求,实现了更快、更精确的检测性能,因此更适合实时使用。
III System Model and Proposed Methods
作者部署的AI摄像头系统部署在交通信号设施上,如图1所示。该AI摄像头捕捉穿过道路的行人。在检测到行人后,AI摄像头系统将捕获的图像转发至集成边缘设备进行处理。边缘设备分析图像,并在出现任何异常情况或潜在安全隐患时为附近驾驶员生成警告或警报。由于这些警告对公众安全至关重要,因此在网络基础设施中给予高度重视,确保警报能够及时传达给驾驶员,使他们能够采取必要的预防措施并作出相应反应。
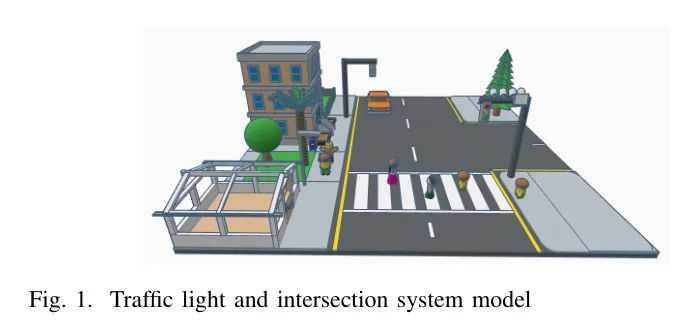
在布局中,作者假定摄像头安装在交通信号灯上。基于这个假设,作者可以根据交通信号灯的高度和宽度估算摄像头的布局。如图2所示,假设交通信号灯(AB)的高度为6米,宽度(BC)为3米,道路行车道(AE)的长度为9.2米,摄像机与对面道路行车道之间的距离为6.2米。因此,安装摄像头的位置(AC)距离交通信号灯侧面(AC)6.7米,距离人行道对面(AC)8.63米。
将摄像头安装在交通信号灯顶部可以提供最佳的视角来检测过对面道路的行人。图3详细了检测区域。如果将摄像头安装在交通标志柱上,摄像头将具有最佳的视野范围(FoV)来获取模型的数据,这将产生更大的和更广的FoV。更大的FoV可以捕获更多的上下文信息,这可能有助于目标检测算法更好地理解场景,并做出更准确的预测。当感兴趣的目标与其他目标或环境互动时,这可能是有帮助的。更大的FoV可以帮助模型理解物体的空间关系,这在物体可能会相互遮挡或场景需要更多上下文以便准确检测时尤其重要。
Proposed pedestrian Model for edge computing
实时行人检测最重要的部件是深度学习(DL)模型。为了实时部署,DL模型必须具有快速的检测时间,并且要使用最小的计算能力来满足这个要求。作者实现了一种名为[44]中描述的模型,并进一步优化以满足这个要求。作者解释说,减少卷积层的深度会使模型的运行速度降低,但准确率也会降低。
然后,DL模型将在道路交叉口处的AIoT设备上部署,用于监控行人过马路。AIoT设备通过MQTT代理将实时检测结果流式传输到边缘服务器。边缘服务器根据特定事件处理结果。如果检测到事件,边缘服务器将向附近的车辆发送通知。
Deep Learning Model
在这项研究中,作者将实现一个两阶段的检测模型,每个阶段处理特定的计算机视觉任务。第一阶段将处理目标检测,用于确定行人相对于摄像机输入的坐标。然后,它将进入第二阶段,处理姿态估计,以预测行人的方向。关于更详细的系统模型,请参见下方的图。
在这个研究中,作者实现了一个轻量级的深度学习模型(DL),专门针对物联网(IoT)设备进行优化。优化这个模型的一个关键部分是降低网络的深度,同时不降低其性能。尽管更深层次的神经网络通常产生更好的结果,但其主要缺点是资源需求。深度神经网络需要很多资源,内存需求,以及计算能力,这可能不适合具有有限内存和计算能力的边缘设备。
作者基于模型YOLO-V3 Tiny [44]。作者发现,添加一个池化层并减少卷积层的深度,仍然可以实现高准确率和较快的推理时间。在作者的DL模型中,作者使用了一种CNN架构[2]和MobileNet。其中,该架构实现了一种称为反转残差技术和线性瓶颈的技术。涉及将输入转换为低维表示,然后在其后深度卷积实现输入模型扩展为高维表示。这种架构的优点是可以在不要求深度卷积的情况下提取特征,即该架构被认为是移动友好的,可以在边缘设备上实现。该模型有三个部分:Backbone 网络、 Neck 和 Head 。Backbone 网络是用于提取特征的神经网络架构。
Model Backbone
在这项研究中,作者将MobileNetv2作为 Backbone 网络。作者使用MobileNetv2的主要原因是因为它具有反转残差块和线性瓶颈层。反转残差块包括以下三个组件:
- 扩展(Expansion):在这个步骤中,输入的通道数(C)通过一个因子(t)扩展。当t>1时,中间特征图(O)中的通道数每(1)。
- 深度卷积(Depthwise Convolution):深度卷积涉及到在特征图上应用具有(kxk)核大小的深度卷积。深度卷积应用独立卷积滤波器到输入的每个通道。深度卷积参数(D)的数量是(2)。式D=k^2*C(2)
- 点积卷积(Projection)使用1x1核在特征图上应用来将输出通道数(C)缩减回原始值。点积卷积输出通道数(C)。反转残差块的总参数数量(T_P)为(3)。式T_P=Ct^2+k^2C+C*C(3)
在MobileNetV2中,一个反转残差块的输出是输入块加上最后一个瓶颈层输出的和。这“短路径连接”帮助跨信息保留。输入块的内容经过瓶颈层后,特别通过一系列深度卷积,使得特征图通道数减小,作为空间滤波器作用于特征图。然后,深度卷积之后接另一个瓶颈层,使得特征图通道数恢复原大小。然后,最后一个瓶颈层的输出添加到反转残差块的输入,产生其输出。该输出之后进入神经网络的下一层。
Model Neck and Head
YOLOv3是一款以其实时性能和效率而闻名的目标检测模型。通过单个全连接层对图像进行单次遍历,该模型能够实现高帧率和响应性。尽管它没有实现最高的准确性,但YOLOv3在速度和准确性之间取得了平衡,使其非常适合实时物体的检测任务。该模型对不同的目标检测任务和自定义数据集具有很好的适应性。由于YOLOv3是开源的,有一个活跃的社区在持续改进和支持。
YOLOv3通过从MobileNet Backbone 模型中获得不同尺度的特征图输入。在YOLOv3中,网络的 Neck 使用了三个不同尺度的特征以实现有效的目标检测:
- 高尺度特征源自最低步长(32)的输出层,捕获细微细节,理想地用于检测较小的目标。
- 中尺度特征源于更高步长(16)的输出层,提供粗糙的空间分辨率,擅长检测中等大小的目标。
- 低尺度特征源自最高步长(8)的输出层,提供最粗糙的空间分辨率,专注于检测大型目标。相应的检测Head预测小型、中型和大型目标的边界框、目标性分数和类别概率。将这些尺度结合在一起,增强了YOLOv3处理大小各异的目标的能力,使其成为实时目标检测任务的首选。YOLOv3的结构如图4所示。
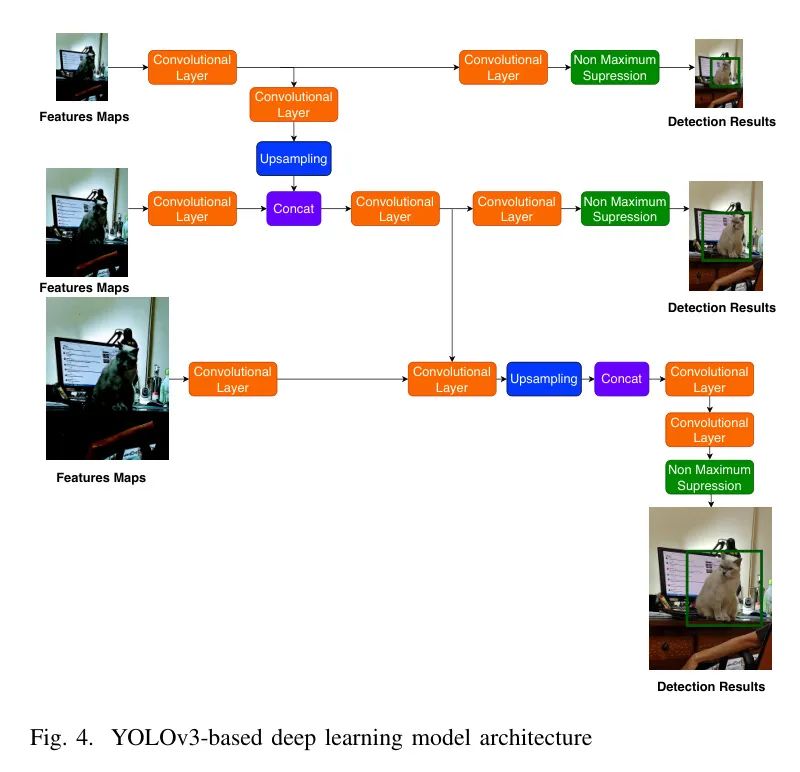
YOLOv3的 Neck 的卷积层从输入特征图中提取视觉特征。卷积层的滤波器和数量随不同尺度和复杂度的特征进行变化,以更好地捕捉不同尺度的特征。上采样层通过增加较低尺度检测层特征图的空间分辨率,以匹配较高尺度检测层的空间分辨率,以确保连接兼容性。拼接层沿通道维将不同尺度的特征图结合在一起,使模型可以融合多尺度信息,更全面地表示输入图像。这对YOLOv3检测大小各异的目标至关重要,使其在实时应用中具有很好的鲁棒性。在YOLOv3的 Neck 进行连接操作后,经过组合的不同尺度特征地图还可以使用额外的卷积层进行进一步处理,以优化多尺度特征表示并提取更抽象的特征,以实现最终的目标检测。
为了优化模型,作者将卷积层数量减少了,使其更紧凑和高效。然而,在降低模型复杂性并保持检测性能之间取得平衡是关键。移除太多卷积层可能会失去重要的特征并降低模型的准确性。图5显示了作者模型的结构。
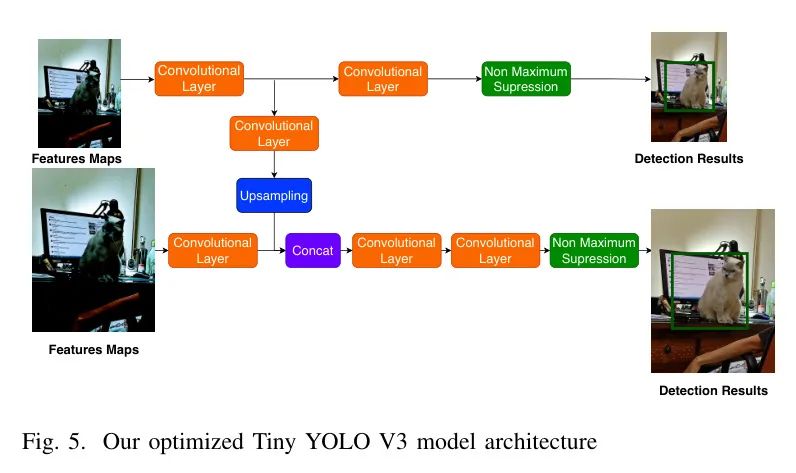
除了减少卷积层数量,作者使用两个检测尺度而不是YOLOv3中使用的三个。Tiny YOLOv3可以利用这两个不同的检测尺度有效地处理图像中的大小不一的目标。较小的目标使用高尺度检测,中等大小的目标使用低尺度检测。Tiny YOLOv3在步长为32(16)的特征图上执行高尺度(低尺度)检测,即这个特征图中的每个单元都对应输入图像中缩小了32倍(16倍)的区域。
使用这种多尺度方法,Tiny YOLOv3可以在受限设备上实时应用中实现目标检测的准确和高效性能。
Dataset
作者使用Crowdhuman数据集[45]训练作者的模型。Crowdhuman数据集包括15,000多张图像,超过470,000个不同尺度的 annotated 人类实例,具有不同的缩放、视点和遮挡水平。该数据集来源于各种地点,如街道、购物中心和机场,并使用不同类型的摄像头拍摄。它通常用于训练涉及在密集人群中检测人的模型。Crowdhuman数据集庞大且丰富,其中包含不同遮挡场景下的高多样性人类。
为了证实作者的模型优于现有模型,作者将与Crowdhuman数据集预训练的广泛使用的深度学习模型进行比较。作者与之相较的模型包括Retinanet [41],Faster RCNN [36],EfficientNet [42]和Single Shot Detector [40]。
MQTT protocol for Internet of Things
为了有效地进行通信,物联网设备需要可靠的实时协议,这些协议可以在低带宽不可靠的网络中运行。最初由IBM [46]开发,消息队列电信传输(MQTT)是一种轻量级的通信协议,可用于物联网设备之间的通信。MQTT设计为高效且可靠,即使在低带宽和不可靠的网络环境中也是如此。MQTT在发布/订阅模型中运行,发布消息的客户端与接收该消息的其他客户端通过发布/订阅异步模式解耦。只有一个客户端接收消息,降低了泄漏消息的风险。
一个典型的MQTT系统包括发布者、代理(Broker)和一名或多名订阅者[46]。向代理发送消息的设备或客户端是发布者。消息可以包含各种数据,包括传感器读数、设备状态和命令,并按主题进行分类。代理是发布者和订阅者之间的中介,将消息分发给所有连接的主题订阅者。代理负责管理所有连接,处理消息队列,并确保消息只发送给预期的收件人。订阅者,即接收代理消息的客户端,可以选择接收一个或多个主题的消息。接收到一条消息后,订阅者可以处理或执行该消息。订阅者还可以根据选择取消接收主题。
IV Simulation Setup
使用视频模拟人行横道场景有多种优势。其中之一是研究者可以创建受控环境来测试和评估人行模型、算法和系统。模拟也可以用于测试在现实生活中难以复制或确保安全的情景。
为了复现通过道路的人行横道场景,在这项研究中,作者使用了Unity[47]结合Traffic3D库。Unity旨在是万能的和灵活的,允许开发行人创建任何类型或风格的游戏和模拟。Traffic3D是一个交通仿真工具,它提供了一个丰富的三维环境来训练智能交通管理代理人。它的目标是创建视觉和物理上智能的交通仿真模型,以测试将在现实中部署的新技术。Traffic3D支持在编程方式甚至在运行时生成场景,并支持插件和即插即用架构,以确保Traffic3D训练过的代理在环境变化时仍保持稳定性和普遍性。这项研究使用Traffic3D在交叉口模拟行人过马路。场景如图6所示。

Deep Learning Model
在本次实验中,作者将使用MMDetection[48],这是一个基于Pytorch[49]的开源框架,由新加坡南洋理工大学OpenMMLab团队开发。使用MMDetection框架,作者将R-CNN[36],Faster R-CNN[36],EfficientNet[42],Single Shot Detector[40]以及作者的优化版Tiny-YOLOv3模型在Crowdhuman[45]数据集上进行训练,使用预训练权重以保持每个类别保护特征的公平性,并在评估模型时进行部署。
然后,作者将模型部署在一个价格低廉的Nvidia Jetson Nano上,即专为AI应用设计的高性能单板计算机。对于像自动驾驶汽车、机器人学和智能摄像头等应用,高性能处理和低功耗至关重要,Jetson Nano非常适合这些应用。Jetson Nano B01的详细参数请参阅表1。
MQTT Broker Setup
在这项研究中,作者使用Eclipse Mosquito [50],一个轻量级的MQTT服务器,作为MQTT代理。在作者的测试环境中,作者将个人电脑用作MQTT代理通过无线网络连接到Jetson Nano。MQTT代理控制消息流,确保发布者消息能够送达预期接收者。无线网络充当MQTT代理和MQTT客户端之间的通信通道,两者都连接到同一无线网络。
MQTT客户端是一个设备或应用程序,表示希望关注特定主题,并通过无线网络连接到MQTT代理。这种配置模拟了一个类似于LTE或5G网络的无线网络环境,其中MQTT服务器位于蜂窝网络内部,其订阅者也连接到同一网络。
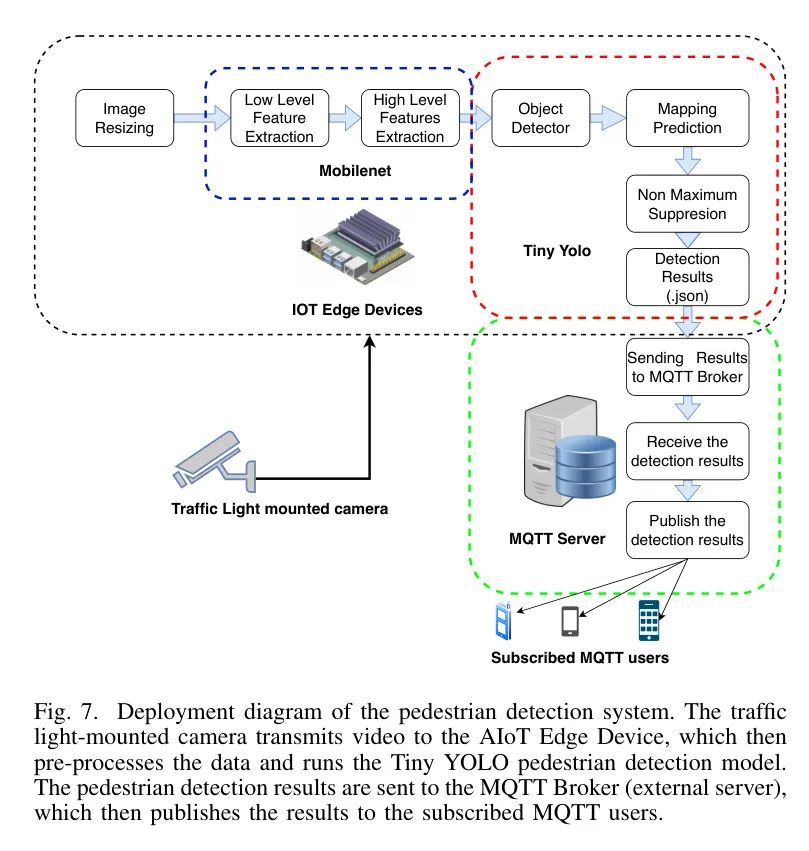
Deployment Diagram
如图7所示,这是作者系统的测试台拓扑结构。对于深度学习处理,所有输入图像必须被缩放以使其类似用于训练的图像。之后,这些图像经过三个功能模块:MobileNet、Tiny YOLO和MQTT服务器进行处理。YOLO模型使用特征金字塔网络(FPN)通过生成多级特征金字塔来提高特征表示,每个特征金字塔都捕获不同尺度的特征。这使得YOLOv3能够有效地检测各种大小的物体。特征金字塔使用上采样和 ConCat 来将来自不同 Backbone Level 的特征结合。具有更高空间分辨率的低 Level 特征会被上采样和与高级特征 ConCat ,从而创建一个多尺度特征图。然后,来自多个 Level 的特征会被 ConCat 。
特征然后被输入到后续层进行不同尺度和分辨率的目标检测。最后,检测层的卷积网络使用 ConCat 特征图来预测检测物体的边界框和分类概率。检测到的物体、边界框位置和分类结果随后被转换为JSON格式并发送到MQTT服务器。
在进行视频负载和JSON负载大小的比较时,作者发现视频负载要显著大得多,达到1500千字节(KB)的大小,而JavaScript目标表示法(JSON)负载要小得多,只有1200字节(B)的大小。这显著的尺寸差异凸显了传输视频内容和JSON数据之间的重要差异。虽然视频负载需要高效的数据流协议和专门的视频传输技术来处理其负载大小和实时要求,但JSON负载可以由轻量级的协议(如MQTT)来管理,这对于消息排队和小数据包的交付是理想的。
V Simulation and Analysis
作者进行了模拟以评估作者的行人检测模型的性能,使用两种类型的测试来展示模型的能力。第一种测试是在部署之前进行的,旨在评估模型在给定上下文中的行人检测效果。在这一初始测试阶段,作者使用多个指标评估模型性能。主要的评估指标是平均平均精确度(mAP),它衡量模型检测行人的准确性。此外,作者通过对DL模型执行所需的浮点运算次数(FLOPS)考虑计算效率。最后,作者通过查看模型的参数大小,以获得对内存需求和存储空间的洞察。作者使用具有Ubuntu 18.04操作系统的RTX 3090 GPU进行这些测试。作者使用MMDetection 2.25.1版本,PyTorch v.13.1和Python 3.8进行测试。这种配置使作者能够充分评估模型的性能并确定其是否适合在作者的目标场景中进行行人检测。
在第二种测试阶段,作者将行人检测模型部署在边缘AIoT设备(Nvidia Jetson Nano)上。这一阶段的目的是评估模型在实时场景中的性能。由于行人检测任务的时效性,模型必须能够准确且快速地识别行人。作者考虑了几个关键指标来评估模型的能力。首先,作者检查了模型的置信评分,它代表了模型正确检测行人的准确性。然后,作者分析了推理时间,它们表示了模型处理和生成预测的速度。最后,作者评估了模型的内存使用,以确保它满足了边缘AIoT设备的资源约束。作者选择在Jetson Nano设备上部署该模型。
选择Jetson Nano设备的原因是它适用于边缘计算任务,优化了深度学习推理的硬件设计以及成本。Jetson Nano在计算能力和能效之间取得了平衡,使其成为边缘设备上实时行人检测的理想选择。
Analysis
本文使用了一种RTX 3090 GPU和Crowdhuman数据集的一个子集进行测试,该数据集包含4370个带有标注的图像。表格II提供了初步测试阶段获得的结果的简述。可以观察到模型的规模与其性能没有显示线性关系。尽管单次检测模型具有最大的规模和FLOPS,但与其他模型相比,它表现不佳。另一方面,作者的模型在模型大小和FLOPS方面都表现出紧凑性,但其mAP结果并不是最好的。EfficientNet模型具有最高的mAP,但它需要作者的模型两倍多的参数。这些发现为作者模型的紧凑性和性能提供了见解,但仍需要进一步的分析来评估其实时部署能力。模型的速度和性能在实时场景中需要评估,以便得出全面的结论。
图8显示,作者模型在与其他模型的推理速率/最低推理时间方面表现最佳。它比最慢的模型快了近20倍,并且比第二快速度模型快3倍以上。这种显著的速度可以归因于通过优化技术精确定义了卷积层。通过简化模型的架构,作者实现了一个更简洁和高效的系统。通过精确定义卷积层,作者可以更快地进行推理,并为模型尺寸的减小做出了贡献。在后续评估阶段,作者专注于评估作者的优化模型的准确性。
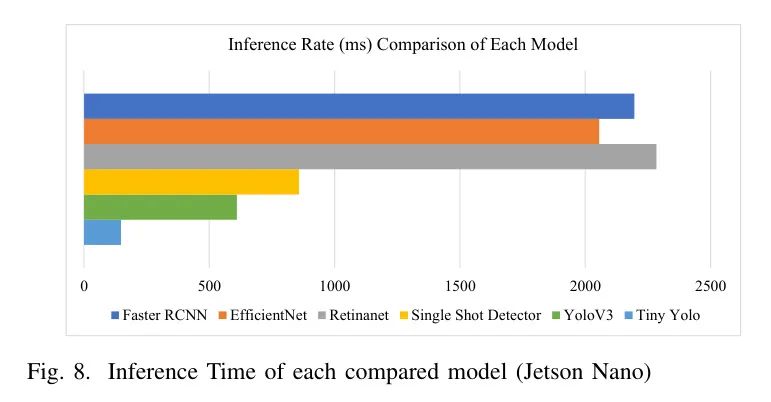
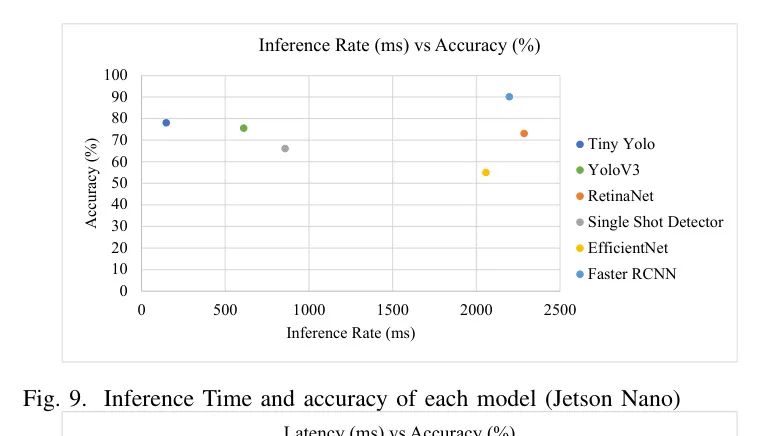
图9说明了作者的模型在实现满意准确度的同时,也显著提高了推理速度。尽管作者的模型准确度不是最高的,但它在速度上超过了Faster RCNN模型。虽然作者的模型准确度不是最高的,但它超过了Faster RCNN模型在速度上的表现。
在行进检测中,实时处理至关重要,更喜欢具有更快推理时间的模型。当作者考虑行进检测速度时,作者也考虑了系统模型延迟,行进检测模型推理时间 + 将检测结果传输到MQTT服务器的延迟。该系统模型延迟显示在图10和10中。根据结果,作者的系统模型是最快模型中的二倍,这是第二快速度模型的两倍。作者的建议行进检测系统模型延迟为424毫秒,这是第二快速度模型的一半。当作者考虑检测帧率时,如图11所示,最高的准确度模型(Faster RCNN)无法实现 sub-second 行进检测,即它无法在实时的行进场景(帧率≥1)中有效地检测行进者。
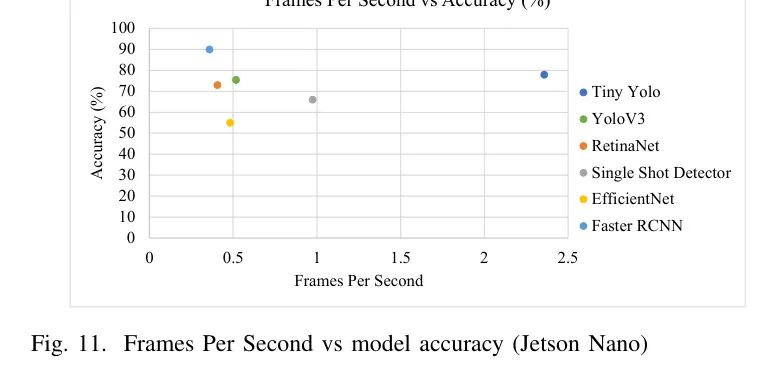
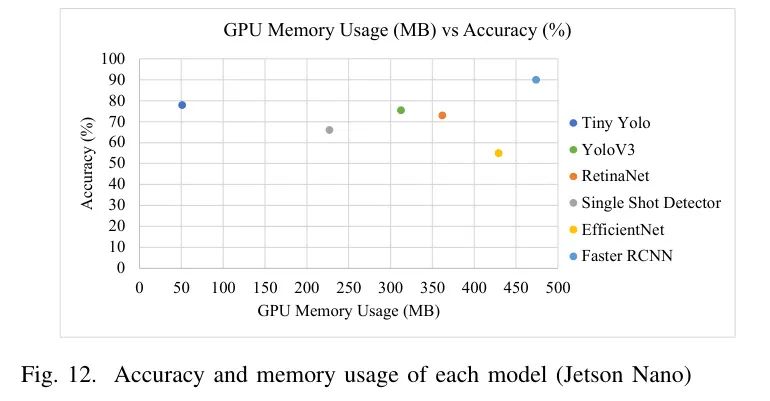
图12呈现了模型评估结果,表明作者的优化模型所需的内存比其他模型少得多。尽管作者的模型体积较小,但其性能与较大模型相似。具体来说,作者的模型所需的资源只有Faster RCNN模型的大约10%,并且实现了类似的表现。这突显了作者的优化模型在效率和节省资源方面的优势。
基于Tiny YOLO和YOLO模型比较,作者可以看到作者的优化结果在性能和计算需求方面都有所改善。虽然准确度的提高很小(只有2.5%),但是其他结果,例如GPU内存和推理时间,都有显著的改善。作者的模型使用了6倍的GPU内存,并且比纯YOLOv3模型实现了大约5倍的推理速率。
现在作者将作者的优化YOLOv3模型与原始YOLOv3模型进行比较,以确定优化是否对模型的性能产生了影响。计算机视觉的一个主要目标是提高准确性。然而,实现更高准确性通常需要使用更大和更复杂的模型。
当这些模型被设计用于资源受限的平台,如物联网领域中常见的高资源限制设备时,它们面临着固有的挑战,如有限内存,处理功率和功耗。因此,尽管大型模型可能在准确性方面优于其他模型,但它们在实际应用中的可行性受到质疑,因为它们与实时资源有效处理的需求不兼容。
VI Conclusion and Future Work
根据作者的研究,在IoT边缘设备上部署优化后的深度学习模型已取得了实时的行人检测优秀结果。
该模型的有效优化使其能够在资源约束最小且计算能力有限的设备上运行,实现高精度和快速检测。
在未来整合我国系统与商业可用的LTE或5G网络面临重大挑战。
这将需要确保与蜂窝网络的无缝兼容性以提升系统性能。
最终,作者的系统为智能交通系统提供了负担得起且智能的替代方案, promising在降低成本和提高效率方面带来显著的好处。
参考
[1].Real-Time Pedestrian Detection on IoT Edge Devices: A Lightweight Deep Learning Approach.











