正在直播中
↓↓↓

👇
在数字化时代,文本数据的挖掘与分析已成为人文社会科学研究中不可或缺的一部分。文本数据挖掘,即从大量文本中提取有用信息和知识的过程,对于理解复杂现象、发现潜在规律具有不可替代的作用。Python,作为一种简洁、易学的编程语言,已经成为研究人员在数据挖掘方面的首选工具。
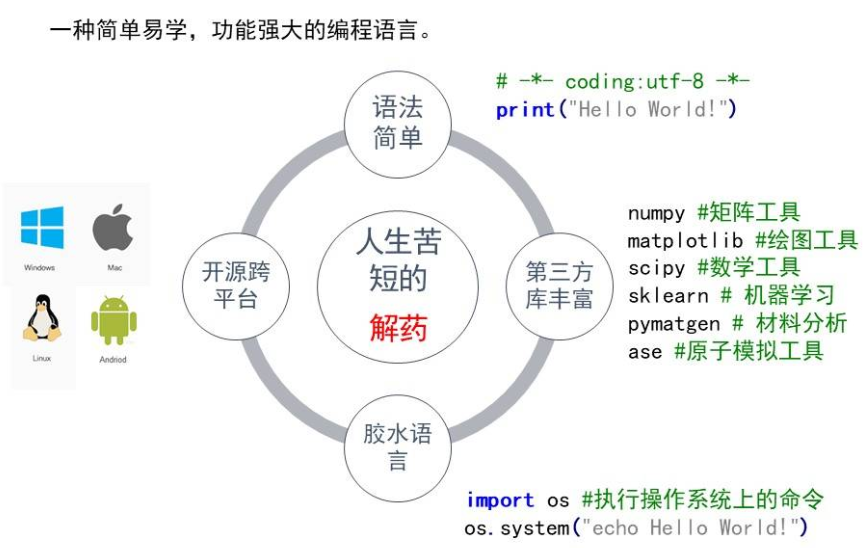
Python 的生态系统不仅庞大而多样,它更是科研人员的得力助手。在这个充满活力的编程世界中,我们可以轻松驾驭一系列文本数据分析任务:
Python的NLTK和spaCy库不仅提供了文本清洗的利器,更让我们能够去除HTML标签、特殊字符和标点符号,执行标准化操作,如小写转换,确保数据的纯净和一致性。停用词的移除和词干提取,进一步精炼数据,为深入分析打下坚实的基础。Scikit-learn的TF-IDF向量化器,以及Word2Vec和BERT等深度学习模型,将文本转化为机器学习模型易于理解的数值形式。这些技术不仅捕捉到单词的频率,更深入挖掘单词之间的语义关系,为文本分析提供了更为丰富和深层次的特征描述。聚类是文本数据分析中的一个核心任务,它旨在将文本数据集中的文档分组,使得同一组内的文档在内容上更为相似。Python的Scikit-learn库提供了多种聚类算法,如K-means和层次聚类,它们可以帮助我们发现数据中的固有结构。通过Python的这些聚类工具,研究者可以深入理解文本数据的内在联系和分布模式。Python的LDA模型,通过统计方法挖掘文档集合中的主题结构,让我们能够识别和提取文本集合中的主要内容,为理解文本数据提供了有力的工具。情感分析是判断文本所表达的情感倾向,如正面、负面或中性的任务。Python的VADER工具利用规则和机器学习模型来评估文本的情感,特别适合分析社交媒体和客户反馈等非正式文本。Python在情感分析领域的应用,为品牌监控、市场研究和公共舆论分析等领域提供了强大的支持。
然而,对于许多文科背景的研究者来说,如何快速上手并有效利用Python进行文本数据挖掘,是一个不小的挑战。然而,AI大模型的兴起为这一难题提供了解决方案。AI大模型能够模仿人类的语言和思维方式,进行自然语言处理,完成自然语言生成和理解的任务。因此,将AI大模型应用于Python,无疑将是一个强有力的助力。
为了更好的协助零基础的学员迅速掌握Python语言这门科研神器,特别是学会如何利用AI赋能Python进行科学研究和论文写作,学术志特别邀请到陈老师开设《AI赋能Python文本数据挖掘和分析线上研修班》。
本课程不仅教授学员Python和AI的基础知识,更注重实战应用,通过丰富的案例和代码实践,帮助学员将所学知识应用到自己的研究和论文写作中,具体涵盖文本数据的预处理、特征提取、聚类、主题分析和情感分析。我们相信,通过这门课程的学习,学员将能够更自信地面对文本数据挖掘的挑战,提升科研和学术写作的能力。
《AI赋能Python文本数据挖掘和分析线上研修班》首发优惠中
扫码立即报名







