前言 作为新一代生物识别技术的代表,静脉识别技术提供了高安全性和便利性。卷积神经网络(CNN),作为一种突出的深度学习架构,已被广泛应用于静脉识别。然而,由于它们的有效感受野较小(例如3×3核)以及训练样本不足,其性能和鲁棒性受到限制,因此它们无法有效地从静脉图像中提取全局特征表示。
为了解决这些问题,作者提出了StarLKNet,一个基于大核卷积的手掌静脉识别网络,并采用了Mixup方法。作者的StarMix有效地学习了静脉特征的分布以扩展样本。为了使CNN能够从手掌静脉图像中捕捉到全面的特征表示,作者探讨了卷积核大小对手掌静脉识别网络性能的影响,并设计了LaKNet,一个利用大核卷积和门控机制的网络。
Pytorch训练营,花两个星期彻底掌握代码实现
CV各大方向专栏与各个部署框架最全教程整理
CV全栈指导班、基础入门班、论文指导班 全面上线!!

1 Introduction
在现代社会,个人信息安全问题越来越受到关注,因为误识别可能对个人的财产安全和隐私造成灾难性的影响。基于密码和身份证等 Token 的认证方法存在被遗忘或被盗的风险。在过去的几十年里,基于生理(如面部[18],指纹[2]和静脉[38, 39])或行为(如步态[3]和眼动[30])特征的个体识别的生物识别技术研究非常广泛。在应用中最常见的生物识别特征是面部和指纹。然而,这些外部特征可能受到潜在的伪造攻击[23]。
相比之下,静脉识别具有明显的优势。静脉和血管位于人体内部,不易受到外部环境(如皮肤湿度和磨损)的影响。此外,因为脱氧血红蛋白只存在于活体中,静脉识别技术具有固有的活体检测功能[28]。在静脉识别领域,传统方法依赖于手工特征提取和浅层机器学习算法进行分类[11, 37]。这些方法基于一些假设,即静脉图案的分布呈现山谷或线状形状,并忽略了更高维度中的有效信息。基于深度学习的方法可以实现端到端特征提取,无需预先假设,但网络参数的训练需要大量的数据支持。
遗憾的是,由于存储限制和隐私政策,实际应用中很难从每个类别获得大量的样本。如何在有限数据的情况下训练一个健壮的高性能网络是一个紧迫的问题。
为了解决因训练数据不足而导致的过拟合问题,研究行人提出了数据增强(DA)技术,通过手工制作或生成方式生成新数据以扩展训练集。Mixup方法通过全局线性插值混合两个或更多样本。由于其实施便捷且额外时间开销极小,研究行人对其进行了广泛使用和改进(例如,CutMix[44],AutoMix[19],PuzzleMix[13],AdAutoMix[29]等)。自从Mixup提出以来,它在包括超分辨率[42]、分割[26]、回归[41]和长尾[1]等下游任务中展现出了出色的性能和鲁棒的泛化能力。从VGG[33]开始,研究行人逐渐将焦点从CNN中使用大核转向采用多个小核的堆叠方法,因为过大的核会导致时间和内存开销显著增加,并且容易忽视图像中的局部细微特征。
然而,一些近期研究[6, 16, 43, 37]表明,经过一些细微改进,具有更大有效感知场的CNN可以与Vision Transformer (ViT)[8]的性能相媲美。鉴于静脉图像特征的连续且稀疏分布,作者认为在大核卷积网络在捕捉静脉特征分布方面比小核网络具有显著优势。如图1所示,与代表小核框架的ResNet18[9]相比,大核显示出更快的拟合速度和更高的分类精度。

为了解决从静脉图像中提取特征的挑战,作者提出了针对静脉图像的Mixup方法,以增强训练数据。此外,作者设计了一个基于大型核卷积模块堆叠形成的高性能掌静脉识别网络框架,以提取掌静脉图像更全面和健壮的特征表示。首先,作者提出了StarMix,它具有更适合静脉图像混合的 Mask ,并且混合参数由高斯函数生成。在作者的方案中,网络可以自由选择混合策略,可以是StarMix或者带有阈值的普通Mixup。此外,作者还提出了LaKNet,一个带有卷积和门控模块的网络。卷积模块包括大核卷积和小核卷积,用于提取全局和局部特征。门控模块通过学习控制特征信息的流动来实现特征过滤。实验结果表明,在VERA220[34]数据集上,StarLKNet模型与ResNet18模型相比,无需增强,测试集上的top-1准确率提高了+19.73%。
总之,作者的主要贡献如下:
- 作者重新思考了在静脉识别任务中卷积核大小对网络性能的影响,发现对于具有连续和稀疏特征分布的静脉图像,增加“有效感受野”可以显著提高网络性能。
- 作者提出了StarLKNet,这是一个为静脉识别设计的新型网络框架,它采用了大型核卷积模块和门控模块来实现全面和健壮的特征提取。作者在两个大型公共掌静脉数据集上的评估表明,StarLKNet在识别准确性和验证误差方面优于现有方法。
- 作者提出了StarMix,一种数据增强方法,它使用高斯函数生成适合静脉图像特征分布的混合 Mask ,从而显著提高了分类器的性能。
2 Related Work
掌纹识别。由于血红蛋白在红外光谱中被吸收,红外相机可以获取血管图像。这种获取方法以及血管分布的特点为特征提取带来了挑战。对此挑战的研究大致可以分为两类传统方法:手工提取特征并输入到浅层机器学习方法中,以及基于卷积神经网络(CNN)的特征提取方法:
在第一类方法中,例如Miura等人[24]进行了重复的线条追踪以检测横截面血管图案中的山谷形状,并提取指静脉纹理以进行验证。其他研究假设在预定义的邻域内血管图案可以被视为线段,提出了线检测方法来提取线状纹理,包括基于Gabor的方法[47]和宽线检测器[10]。作为静脉领域中使用的传统浅层机器学习方法,例如[4],使用了主成分分析(PCA)和线性判别分析(LDA)进行特征降维,并结合支持向量机(SVM)进行特征分类;
CNN在提取静脉识别任务中的特征方面表现出了显著的能力。例如,Syafeeza等人提出了一个四层的CNN用于指静脉识别[32],后来又使用预训练的VGG16[33]模型和七层增强的卷积来识别指静脉[17]。
MixUp。混合增强方法的诞生始于MixUp[45],它包括根据从0到1的混合比例,对两个样本进行静态线性插值以获得混合样本。CutMix[44]将MixUp样本从图像像素转换到空间 Level ,生成混合比例大小的 Mask 以随机混合 Patch 。
随后,一些方法被提出以改进样本混合策略或标签混合策略。与手工制作方法相比,SaliencyMix[35]通过额外的特征提取器获取显著性信息,引导样本混合。与此类似,PuzzleMix 和Co-Mix 利用梯度信息进行反向传播以定位特征区域,并采用最优传输方案,通过在混合样本中最大化特征来避免特征信息重叠。AutoMix[19]采用端到端的方法,设计了一个生成器混合块,同时优化生成器和模型,在时间和性能上实现了最优结果。
最近,基于AutoMix的AdAutoMix[29]被提出,以增强生成的样本,不仅混合任意两个样本,而是混合任意一组个样本;AdAutoMix还提出了对抗性训练,以防止生成器过拟合,通过推动生成器生成对提高训练性能有更大影响的困难样本。
3 Preliminaries
Mixup
作者定义 为训练样本集合, 为相应标签的真值集合。对于每个样本对 ,, 是相应的独热标签。其中 分别代表样本的宽度、长度和通道; 是样本类别的数量。作者根据 MixUp 方法的线性插值混合样本对 和 以获得混合样本和标签:
其中 是从 分布中抽取的混合比例。作者通过深度神经网络 将混合样本 映射到其标签
:。通过最小化损失函数连续训练网络参数向量 ,即:
Gating
作者的网络中的MogaNet门控机制包括和激活函数[15]。它为网络训练期间过滤信息流提供了一个简单而有效的结构,从而提高了提取特征的有效性。使用的目的是将函数的平滑性和非线性与ReLU线性单元在正值区域的线性特性结合起来:
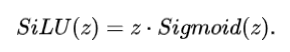
具体来说,被用来实现特征的线性变换,通过调整权重来强调或抑制特征。的输出,,被用作的输入,能够根据输入特征的重要性调整其激活值,从而实现门控机制的效果:
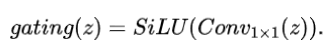
4 StarLKNet
作者提出的StarLKNet模型,如图2所示,由两个组件组成,StarMix和LaKNet。StarMix使用由高斯函数生成的 Mask 来混合和增强数据,而LaKNet包括一个具有大核的卷积模块和一个门控模块。在下一节中,作者首先介绍作者的混合方法StarMix,然后详细描述LaKNet。

StarMix
本节详细介绍了StarMix方法;StarMix的伪代码在算法1中提供。

算法1 StarMix伪代码流程。
StarMask. 如图3所示,与普通MixUp中的相比,混合 Mask 更多地关注样本的周围和中心部分,能更好地适应静脉特征的分布。为了得到,作者定义了一个高斯函数来生成 Mask 。作者假设一对样本,,其中样本,并考虑从中抽取的混合参数。高斯函数由方程4给出:

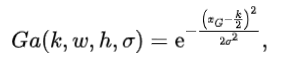
其中是高斯核的大小,设为224,是 Mask 的区域划分,,。将参数传递给如方程5所示,作者得到 Mask :
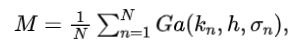
其中。注意,
,。然后作者对
进行归一化,得到最终的 Mask 如方程6:
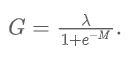
当作者得到 Mask 后,需要根据方程7重新计算混合比例的正确比值:
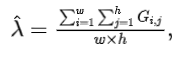
其中表示中第行第列的像素值。可以看作是中所有像素值在强度上的平均值。最后,根据方程8获得混合样本及其对应的标签:
阈值设置。如图2所示,由于,当小于0.3或大于0.7时获得的 Mask 不可靠,因此作者建议使用阈值化来避免在混合时获得不可靠的 Mask :

当在[0.3, 0.7]的阈值范围内时,使用StarMix,当在该阈值范围外时,作者选择普通Mixup。这种阈值设置避免了StarMix在特殊情况下的缺点。混合StarMix和普通Mixup的好处可以在表3中看到。

LaKNet
这一小节详细介绍了LaKNet模块和方法。
架构规范。LaKNet由以下子模块组成:
Stem 是作为网络输入的第一个模块,通过将原始样本映射到更高维空间来捕获更多细节。Stem包括一个步长为2、通道为64的 。然后通过步长为1的 和步长为2的 (深度可分离卷积)进行下采样。
Embedding 阶段的子模块包括一个 和一个 BatchNorm 层。此模块的输入和输出通过 函数激活。Embedding的主要目的是在卷积中进一步聚合阶段的输入特征信息,防止模型过拟合训练集,避免梯度爆炸或消失。这是大多数网络模型的常见做法。
LaKBlock 包括两个分支:一个 模块和一个门控模块。 模块采用 大核与 的组合,通过捕捉全局和局部特征来扩展 _有效感受野_。 使用一些小卷积核 捕获局部特征,以及两个膨胀卷积,旨在捕捉离散特征而不产生额外开销。门控模块采用由 和
激活函数组合形成的门控机制来获取输入 的有效特征。作者最终将 模块的输出和门控模块的输出合并为总输出,作为 Neck 层的输入。
Neck 模块的位置用于连接架构中的不同阶段,并使用 来增加下一阶段的通道输入维度。
FC Layer 模块是一个 层,用于最终的分类,将获取的特征信息映射以获得最终的分类概率分布。
总结来说,由于下采样操作,每个阶段的通道维度是不同的,LaKNet中每个阶段的大卷积维度也是不同的。因此,LaKNet中每个阶段的层数、通道维度和大卷积分别为 、 和 。
核混合。这一段解释了大型核函数 和一组小型核函数 的混合方法,旨在使模型能够捕捉到局部和全局特征。这允许模型 的稳定优化。
其中 表示嵌入层的输出,
是 和 的加法输出, 与深度可分离 和两个深度可分离 (膨胀设置为2和4)组合。
图4:所提出的StarLKNet的框架。:表示StarLKNet的主模块,包含1个Stem、4个Stages、3个Necks和一个FC层。:每个模块内功能和具体操作的全面说明。

门控。门控操作的目的是通过学习 的权重,结合激活函数引入非线性,强调或抑制特征,完成特征筛选过程。选择ReLU而非SiLU的依据是,输入 在进入LaKBlock之前通过ReLU激活,从而无需根据方程式11引入额外的负半轴非线性特征:
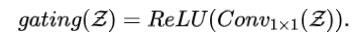
5 Experiments
为了评估作者方法的有效性,作者进行了实验比较,总共包括了3种情况下的6个基准测试:基础线、MixUp和StarMix。为了公平验证,作者比较了一些主流的网络,即VGG16[33],ResNet18[9]和ResNet50;
在静脉识别任务中,作者还比较了三种分类器:FVCNN[5],PVCNN[27]和FVRasNet[40]。
作者以测试集上最后10个周期的中值Top-1准确率作为最终结果,因为在该状态下模型的分类性能趋于稳定,这是衡量模型最终性能和过拟合程度的更好指标。最后周期的错误接受率(FAR)和错误拒绝率(FRR)用于计算等于错误率(EER),此时的bold和cyan标记了最佳和第二好的结果。
Dataset information
作者选择了两个大型公共掌静脉数据集进行作者的实验:
TJU600: 天津大学掌静脉数据集[46] 包含了300名志愿者的左右手掌静脉图像。每位志愿者的样本数据收集了2次,两次收集之间的时间间隔大约为60天。每次从每只手掌收集10张静脉图像,因此数据集总共包含12,000张图像(300名志愿者 2只手掌 10张图像 2个时间段)。每张图像的分辨率在ROI标准化后调整为224 224。
VERA220: VERA掌静脉数据集[34] 包含了110名志愿者的左右手掌静脉图像,这些图像是在两个时间段内获取的。每次为每只手收集5张掌静脉图像,因此数据集总共包含2200张图像(110名志愿者 2只手掌 5张图像 2个时间段)。每张图像的分辨率也被设置为224 224。
Experiments implementation details
对于TJU600,作者将整个数据集分为训练集和测试集,每个集合包含6000张图像(300名志愿者 × 2掌部 × 10张图像)。同样,作者将VERA220数据集划分为训练集和测试集,每个集合包含1100张图像(110名志愿者 × 2掌部 × 5张图像)。
作者将RandomFlip和填充3个像素的RandomCrop作为基本的增强方法。实验的批量大小设置为32,总共考虑600个周期进行训练;学习率设置为0.1。
对于VGG16,学习率设置为0.01,通过余弦调度器进行调整;对于FVCNN和PVCNN,使用Adam[22]优化器,学习率设置为0.0001,权重衰减为0.001;其他模型的训练通过动量为0.9和权重衰减为0.0001的SGD[21]优化器进行。对于MixUp和StarMix,,
= 1。
Classification results
表1和表2展示了StarMix和LaKNet在两个指标上的性能:分类准确率和EER。

表1显示,在分类性能上,作者的方法在TJU600数据集上超越了现有方法。StarMix在不同模型中均取得了较好的增益;特别是,在ResNet50和FVCNN中,作者分别达到了94.13%和80.45%,比原始Mixup分别高出+1.2%和+1.2%。与其他模型相比,没有增强方法的StarLKNet达到了91.90%的准确率,而使用StarMix后,准确率提高到了96.63%。
同样,作者的方法在VERA220上的结果展示在表2中。作者观察到,由于VERA220数据集较小,没有增强的模型的性能非常低。在使用Mixup和StarMix之后,性能得到了显著提升。例如,VGG16和PVCNN分别提高了+39.6%和+39.18%。但在同样的情况下,即使不使用增强方法,StarLKNet也取得了不错的结果,这有力地证明了StarLKNet在有效特征提取方面的能力。
5.4.2 Occlusion
为了分析StarLKNet对随机遮挡[25]的鲁棒性,作者从TUU600和VERA220构建了测试数据集,这些数据集被随机16×16大小的 Patch 遮挡,遮挡比例逐渐从0%增加到10%。作者将被遮挡的测试集输入到不同的模型进行分类。由于静脉图像的特征是连续且离散的,当遮挡 Patch 落在具有连续静脉的区域时,可能会导致特征中断。这对识别模型提出了挑战,并为评估模型对静脉特征的鲁棒性提供了额外的设置。
从图6中,作者观察到当遮挡比例从0% → 8%时,StarLKNet达到最高的准确率,这表明大核对于鲁棒性是有益的。与 Baseline 模型相比,StarMix也被证明对鲁棒性有益。

Ablation Study
作者的消融实验旨在分析StarMix增强方法、门控模块和大核模块在LaKNet中的有效性。
- 作者在VERA220数据集上使用ResNet18和FVRasNet进行实验。目的是验证StarMix以及[0.3,0.7]阈值设置的效果。表3显示,在某些情况下,应用StarMix对模型有害,与MixUp测试集相比,Top-1准确率降低了0.1%。如图3所示,当小于0.3时, Mask 集中在中央区域;当大于0.7时, Mask 集中在外围。然而,当在0.3和0.7之间时, Mask 通过超越MixUp,分别为ResNet18和FVRasNet带来额外的提升,提升幅度分别为**+0.91%和+5.73%**。
- 在表4中,作者对LaKNet的每个模块进行了消融实验,以验证相应模块的效果。可以看出,相比于仅含和的LaKNet,提供了**+0.36%的改进。门控操作还帮助模型的分类性能提升了+0.74**%。这是合理的,因为使用扩张卷积扩展了_有效感受野_,使模型能够捕捉到更多的全局特征。门控模块过滤特征,进一步保留了有效的高维特征。
6 Conclusion
在本论文中,作者提出了StarLKNet,一个具有大核的基于卷积的手掌静脉识别网络,该网络融合了StarMix数据增强方法和LaKNet结构。
StarMix通过高斯函数为图像混合生成 Mask ,有效减少了数据集中样本不足引起的过拟合问题,同时也提高了模型的鲁棒性。LaKNet网络通过结合大有效感受野和门控机制的筛选能力捕获更多全局有效特征,从而稳定了模型的识别能力。
进行了一系列分类和分析实验来验证作者方法卓越的性能。
未来工作。作者的未来工作将进一步探索如何增加有效感受野的大小以及后者对模型性能的影响程度。
作者还将研究如何解决由大卷积核引起的时间开销问题。关于mixup方法,作者将尝试开发一种端到端的方法。
参考
[1].StarLKNet: Star Mixup with Large Kernel Networks.
若觉得还不错的话,请点个 “赞” 或 “在看” 吧
论文指导班
论文指导班面向那些没有导师指导、需要升学申博的朋友,指导学员从零开始调研相关方向研究、尝试idea、做实验、写论文,指导老师会提供一些idea、代码实现部分的指导、论文写作指导和修改,但整体仍然是由学员自主完成。需要说明的是,论文指导班并非帮你写论文,或者直接给一篇论文让你挂名,我们不会做任何灰色产业,因此,想直接买论文或挂名的朋友请勿联系。
指导老师:
海外QS Top-60某高校人工智能科学博士在读, 师从IEEE Fellow,曾在多家AI企业担任研究实习生和全职算法研究员,具备极强的学术届和工业界综合背景。研究领域主要包括通用计算机视觉模型的高效设计,训练,部署压缩以及在目标检测,语义分割等下游任务应用,具体包括模型压缩 (知识蒸馏,模型搜索量化剪枝), 通用视觉模型与应用(VIT, 目标检测,语义分割), AI基础理论(AutoML, 数据增广,无监督/半监督/长尾/噪声/联邦学习)等;共发表和审稿中的15余篇SCI国际期刊和顶级会议论文,包括NeurIPS,CVPR, ECCV,ICLR,AAAI, ICASSP等CCF-A/B类会议。发明专利授权2项。
长期担任计算机视觉、人工智能、多媒体领域顶级会议CVPR, ECCV, NeurIPS, AAAI, ACM MM等审稿人。指导研究生本科生发表SCI, EI,CCF-C类会议和毕业论文累计30余篇,有丰富的保研,申博等方面经验,成功辅导学员赴南洋理工,北大,浙大等深造。
涉及范围:CCF会议A类/SCI一区、CCF会议B类/SCI二区、CCF会议C类/SCI三区、SCI四区、EI期刊、EI会议、核心期刊、研究生毕业设计
报名请扫描下方二维码了解详细情况,备注:“论文班报名”。

如果有其他想要当论文指导老师的朋友,请发简历给我,同样扫描上方二维码,备注:“论文指导老师”。基本条件:已发表两篇以上一作顶会,或3-5篇其他级别的一作论文,学历在985博士及以上。











