深度聚类不仅继承了传统聚类算法的优点,在对高维和非线性数据的处理能力,以及自适应性和抗噪性方面也具有很大优势。
具体来说,结合深度学习的聚类算法通过利用深度神经网络的强大特征提取能力,自动学习和识别数据中的复杂结构和模式,能够在无需人工干预的情况下实现更高的聚类性能和准确度。
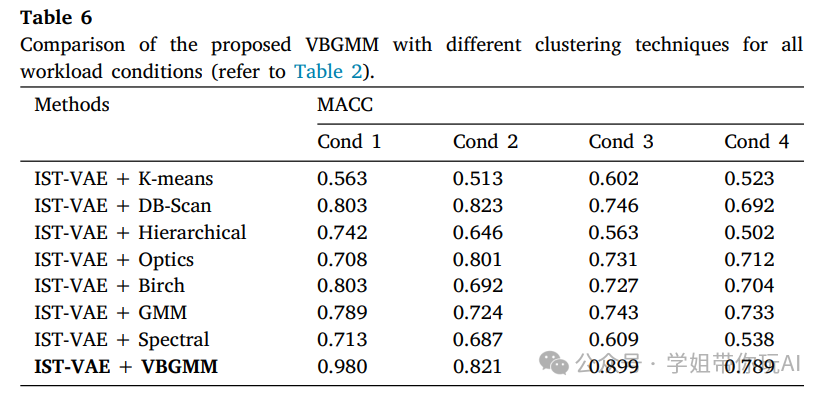
比如集成时空深度聚类(ISTDC)模型,它使用四种算法和变分贝叶斯高斯混合模型(VBGMM)聚类方法进行说明,在0-back与2-back任务上该模型实现了最高平均聚类准确率98.0%,比现有方法提高了11.0%。
除ISTDC外,还有一些很值得学习的深度学习聚类算法最新成果,我从中挑选了11篇,简单提炼了可参考的创新点,希望可以给同学们提供论文灵感。
扫码添加小享,回复“新聚类”
免费获取全部论文+开源代码

Integrated Spatio-Temporal Deep Clustering (ISTDC) for cognitive workload assessment
方法:论文提出一种基于ISTDC框架的深度聚类模型,并比较其与现有研究的差异。研究缺口在于目前的模型对于相同实验数据集的分类准确性较低,而这篇论文的主要贡献是提出了一种有效的深度特征表示方法,以及使用VBGMM聚类方法对工作负荷水平进行分类。方法包括实验设计和数据采集,以及对聚类结果和性能进行分析。
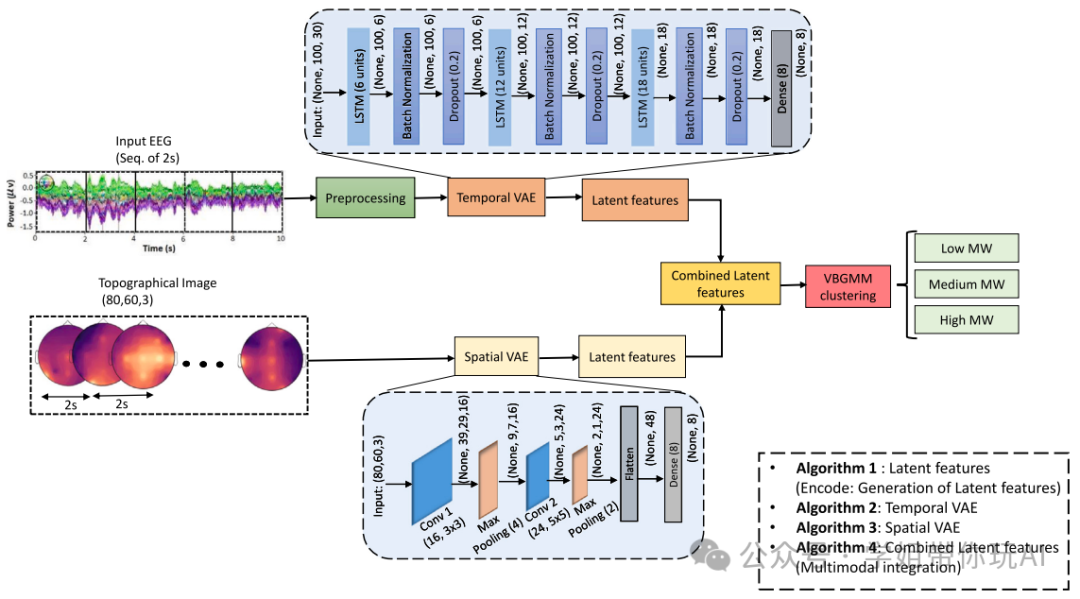
创新点:
- 提出的多模态深度VAE模型与VBGMM聚类方法相结合,用于工作负荷分类。
- 提出的IST-VAE模型的性能在很大程度上取决于VAE模型的结构和超参数。
- 提出的多模态深度聚类模型在具有不同任务复杂度的三种不同工作负荷条件下进行评估。
- 提出的IST-VAE模型的整体复杂度为(LSTM网络的时间复杂度 + CNN模型的计算复杂度 + VBGMM聚类算法的复杂度)。
Gene-SGAN: discovering disease subtypes with imaging and genetic signatures via multi-view weakly-supervised deep clustering
方法:Gene-SGAN是一种基于生成对抗网络和变分推断的基因引导弱监督聚类方法,旨在从表型和基因特征中识别与疾病相关的亚型,具有独特的影像和基因特征。该方法通过从参考总体(例如健康对照的脑测量)到目标总体(例如患者队列)的表型测量的一对多映射,学习捕捉与疾病相关的多样性脑变化模式,以减少与疾病无关的变化的混淆因素,如人口统计因素或与疾病无关的基因影响。
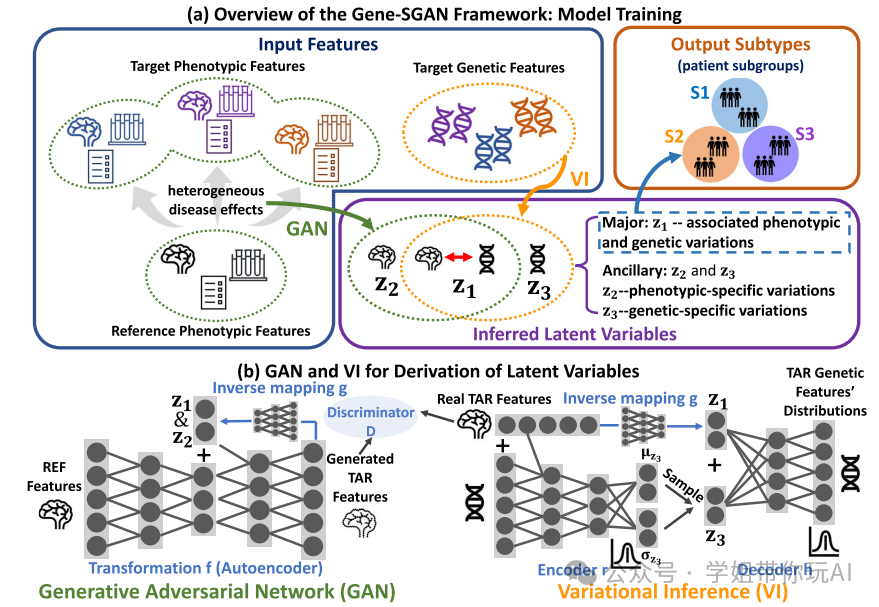
创新点:
- Gene-SGAN是一种基于生成对抗网络和变分推断的多视图弱监督深度聚类方法,用于从基因和成像特征中识别与疾病相关的亚型。
- Gene-SGAN通过学习生成模型从参考人群(例如健康对照组)到目标人群(例如患者群体)的表型测量之间的一对多映射,从而捕捉与疾病相关的大脑变化模式的多样性。
-
Gene-SGAN通过低维潜变量空间将表型和基因的异质性分解为反映疾病亚型的潜变量。
扫码添加小享,回复“新聚类”
免费获取全部论文+开源代码
Hard Sample Aware Network for Contrastive Deep Graph Clustering
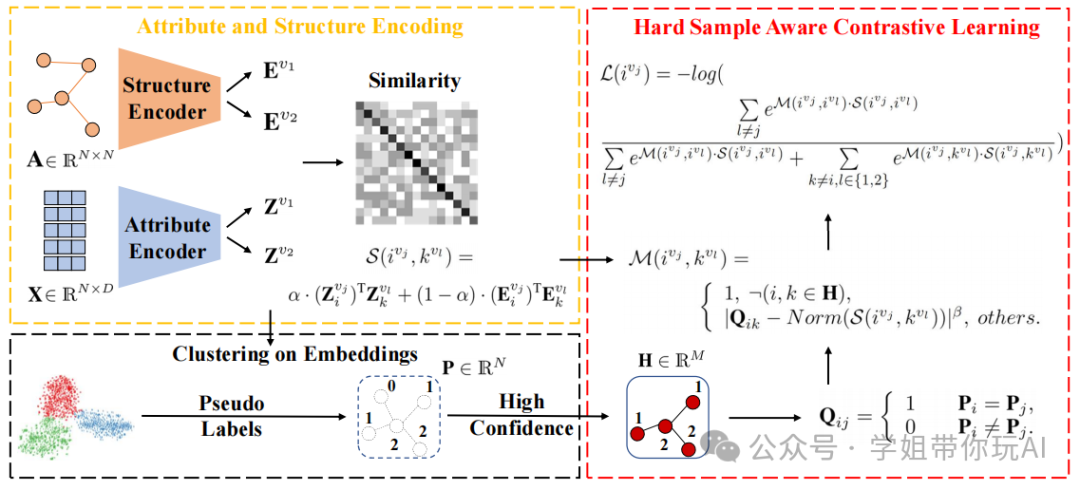
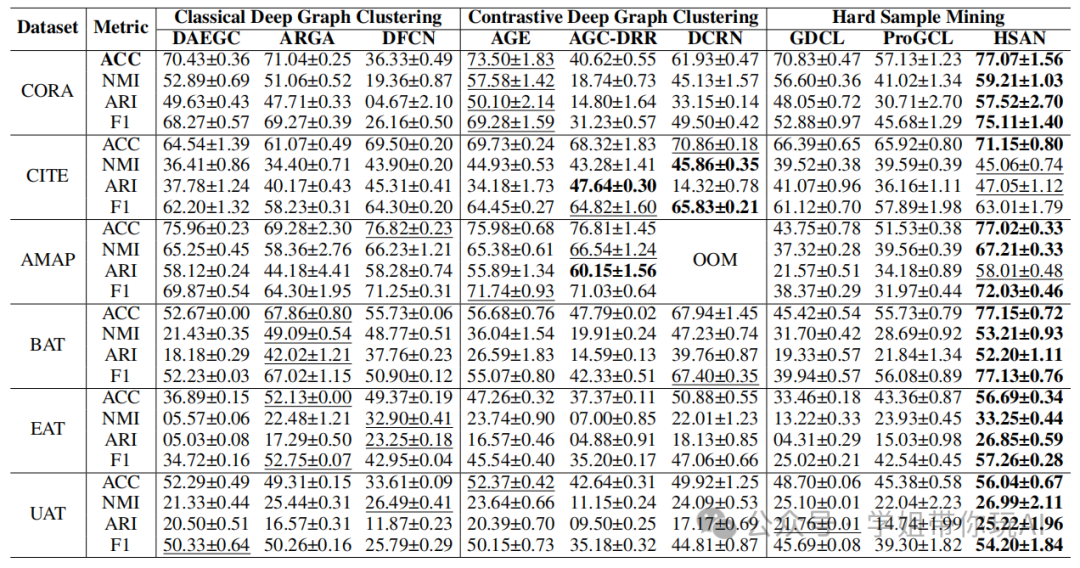
方法:本论文提出了一种新的对比深度图聚类方法,称为Hard Sample Aware Network (HSAN)。该方法通过设计综合相似度度量准则和动态样本加权策略,引导网络关注难以区分的正样本和负样本。
创新点:
- 提出了Hard Sample Aware Network (HSAN)方法,通过引入综合相似性度量准则和动态样本加权策略,引导网络关注难样本。
- 设计了全面的相似性度量准则,同时考虑属性和结构信息,更好地揭示样本间的关系。
- 提出了样本加权策略,动态加权难样本对,降低易样本对的权重,从而提高网络的区分能力。
Hard Regularization to Prevent Deep Online Clustering Collapse without Data Augmentation
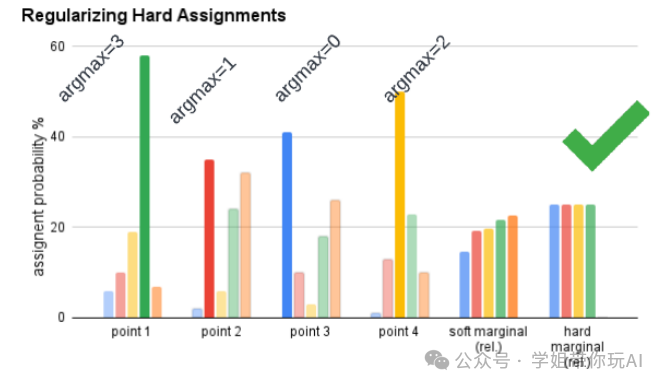
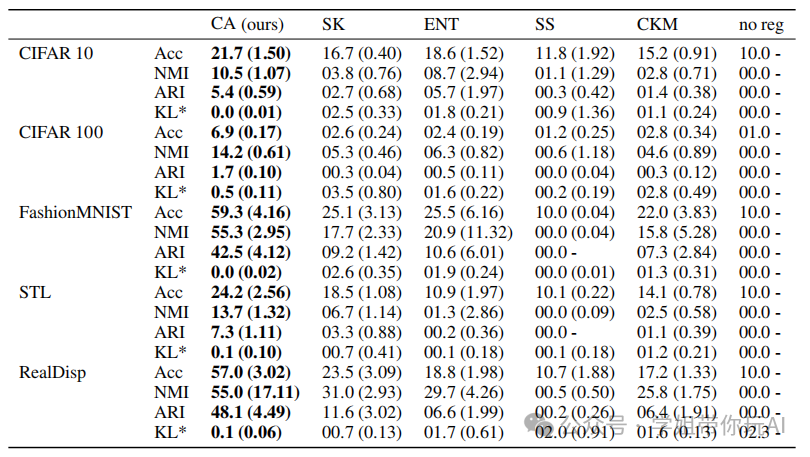
方法:本文提出了一种无数据增强的在线深度聚类方法,旨在防止聚类崩溃。作者通过概率化的方式来决定将一批数据点分配给哪个聚类簇,给定聚类中心和数据点的特征,从而推导出一种直观的优化目标,用于进行硬聚类分配。
创新点:
- 提出了一种无数据增强的在线深度聚类方法,通过正则化硬分配来防止坍塌问题。
- 在贝叶斯框架中表达了聚类问题,推导出一个直观的优化目标,并证明了与最大化聚类分配和数据索引之间的互信息的目标的等效性。
- 该方法在四个常用图像聚类数据集上优于现有方法,并且能够提供更准确的聚类结果。
扫码添加小享,回复“
新聚类”
免费获取全部论文+开源代码










