 夕小瑶科技说 原创
夕小瑶科技说 原创
作者 | Tscom
引言:大语言模型的高效微调及其在多样化任务中的应用
在人工智能领域,大语言模型(LLMs)已成为推动技术进步的关键力量。它们在理解和生成自然语言方面展现出了卓越的能力,从而在问答系统、机器翻译、信息提取等多样化任务中发挥着重要作用。然而,要将这些模型适配到特定的下游任务中,通常需要进行微调(fine-tuning),这是一个资源密集型的过程。高效的微调方法因此成为了研究的热点,旨在减少训练成本,同时保持或提升模型性能。
尽管如此,实现这些方法在不同模型上的应用仍然需要非凡的努力。为了解决这一问题,研究者们开发了各种框架来简化微调流程,提高资源利用率,并通过友好的用户界面降低技术门槛。这些框架的出现,使得更多的研究者和开发者能够利用LLMs,推动了人工智能技术的民主化。
LLAMA FACTORY是一个旨在普及LLMs微调的框架。它通过可扩展的模块统一了多种高效微调方法,使得数百种语言模型能够在资源有限的情况下进行高吞吐量的微调。此外,该框架还简化了常用的训练方法,如生成式预训练、监督式微调、基于人类反馈的强化学习以及直接偏好优化等。用户可以通过命令行或Web界面,以最小或无需编码的方式自定义和微调他们的语言模型。
LLAMA FACTORY的有效性和效率已通过语言建模和文本生成任务得到实证验证。该框架已在GitHub上发布,并获得了超过13,000个星标和1,600个分支。
论文标题:
LLAMAFACTORY: Unified Efficient Fine-Tuning of 100+ Language Models
论文链接:
https://arxiv.org/pdf/2403.13372.pdf
项目链接:
https://github.com/hiyouga/LLaMA-Factory
LLAMA FACTORY框架的核心组成
下图显示了LLAMA FACTORY由三个主要模块组成:模型加载器(Model Loader)、数据工作者(Data Worker)和训练器(Trainer)。
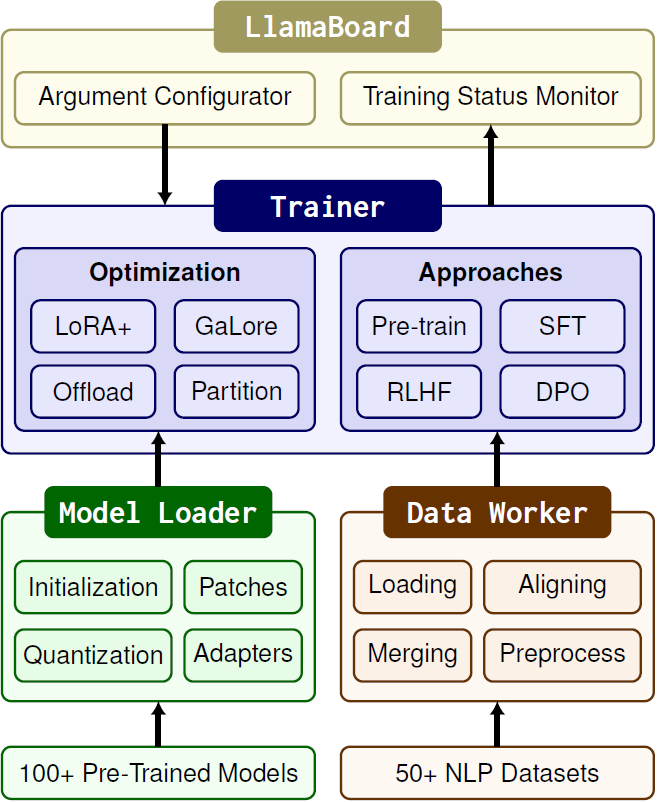
1. 模型加载器:支持100+语言模型的准备工作
LLAMA FACTORY框架的模型加载器是其核心组件之一,负责准备和加载超过100种不同的语言模型。这一模块通过建立模型注册表,精确地为预训练模型附加适配器,识别并处理模型的各个层次。此外,模型加载器还负责模型的初始化、模型补丁、模型量化和适配器附加等关键任务,确保了框架能够灵活地扩展到数百种模型和数据集。
2. 数据工作器:处理和标准化不同任务的数据集
数据工作器是LLAMA FACTORY框架的另一个关键模块,它通过一系列的数据处理流程,包括数据加载、数据对齐、数据合并和数据预处理,来处理和标准化不同任务的数据集。该模块利用数据描述规范(下表)来统一不同格式的数据集,使其能够适应各种任务。例如,对于文本生成模型的训练,数据工作器提供了多种聊天模板,这些模板可以根据模型类型自动选择,并通过分析器编码句子。

3. 训练器:整合多种高效微调方法
训练器是LLAMA FACTORY框架的第三个核心模块,它整合了多种高效的微调方法,如LoRA+和GaLore,通过替换默认组件来适应不同的任务和数据集。这些训练方法与训练器相互独立,易于应用于各种任务。训练器还支持分布式训练,可以与DeepSpeed等工具结合使用,进一步降低内存消耗。
高效微调技术的分类与应用
高效的LLM微调技术可以分为两个主要类别:一类专注于优化,另一类旨在计算。
1. 高效优化技术:减少参数调整成本
高效优化技术的主要目标是在保持成本最低的同时调整LLMs的参数。LLAMA FACTORY框架中包含的高效优化技术(下表)有freeze-tuning(冻结大部分参数,仅微调少量解码器层的参数)、GaLore(将梯度投影到低维空间,以内存高效的方式进行全参数学习)、LoRA(冻结所有预训练权重,引入可训练的低秩矩阵)以及DoRA(将预训练权重分解为幅度和方向组件,仅对方向组件应用LoRA)等。

2. 高效计算技术:降低计算所需的时间或空间
高效计算技术旨在减少LLMs所需的计算时间或空间。LLAMA FACTORY框架整合了一系列高效计算技术(上表),如混合精度训练、激活检查点、flash attention(一种硬件友好的注意力计算方法)、S2 attention(解决块稀疏注意力中上下文扩展的挑战)以及各种量化策略(使用低精度表示权重以减少内存要求)。此外,Unsloth技术通过Triton实现LoRA的反向传播,减少了梯度下降过程中的浮点运算,加速了LoRA训练。
LLAMA FACTORY的实用工具和特性
在当今大数据时代,高效地调整和优化LLMs对于实现其在下游任务中的最佳性能至关重要。LLAMA FACTORY框架应运而生,为广大研究者和开发者提供了一个统一、高效的LLM微调平台。以下是LLAMA FACTORY的一些核心工具和特性:
1. 加速推理:提供高吞吐量的并发推理服务
LLAMA FACTORY通过集成先进的计算技术,如混合精度训练、激活检查点以及特定的注意力机制优化(例如Flash Attention和S2 Attention),显著提高了模型的推理速度。这些技术共同作用,使得在进行大规模模型推理时,能够以更低的内存占用和更高的吞吐量执行,从而加速了模型的部署和应用。
2. 综合评估:包含多种评估LLMs的指标
为了全面评估微调后模型的性能,LLAMA FACTORY集成了一系列评估指标,包括多项选择任务的评估(如MMLU、CMMLU和C-Eval)以及文本相似度评分(如BLEU-4和ROUGE)。这些综合评估工具不仅支持自动评估模型的性能,还能通过人工评估提供更加深入的洞察,帮助用户从多个维度理解模型的优势和局限。
LLAMABOARD:用户友好的界面
为了降低LLM微调的门槛,LLAMA FACTORY提供了
LLAMABOARD,一个基于Gradio构建的用户友好界面,使得用户无需编写任何代码即可轻松地进行模型的配置、训练和评估(下图)。
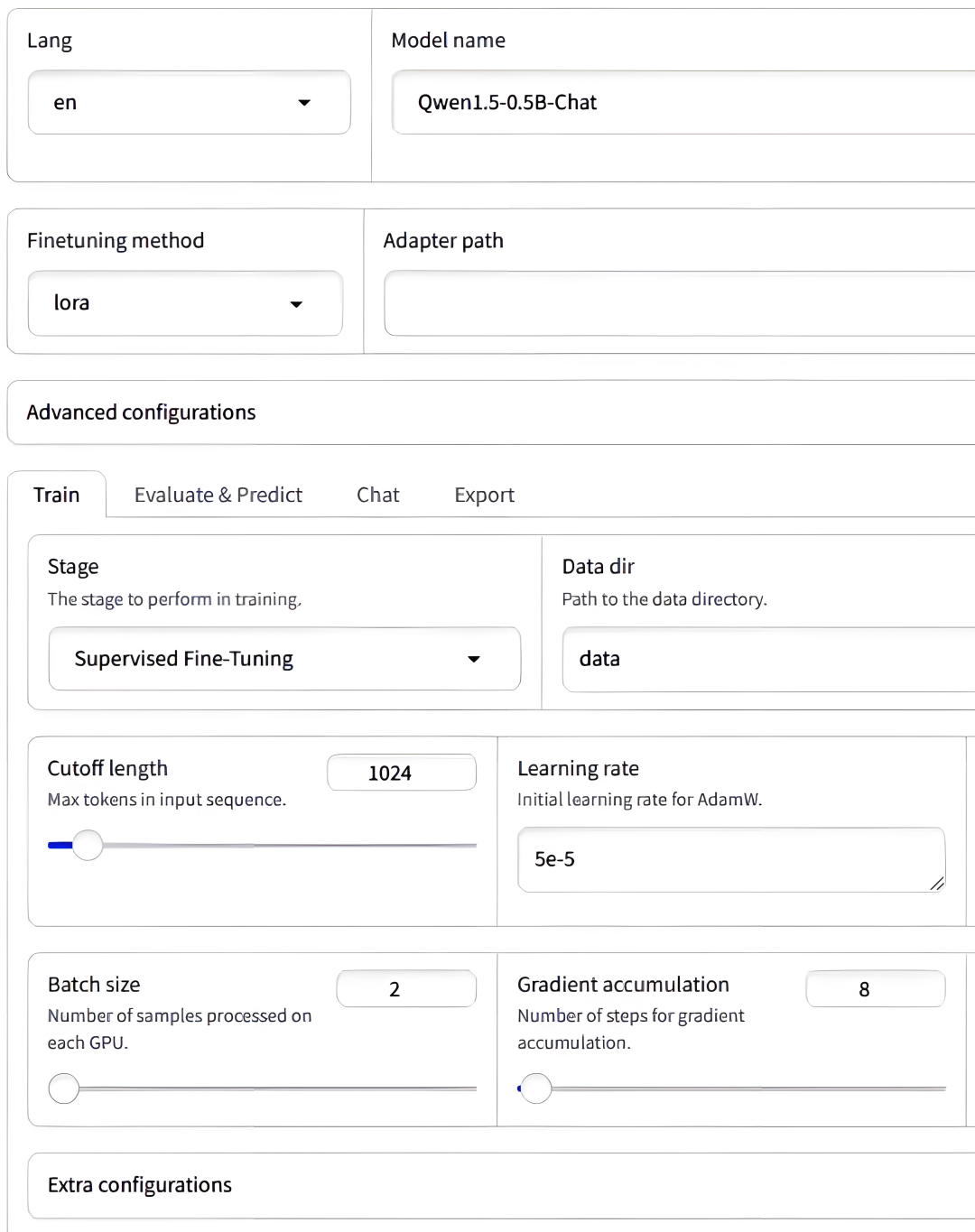
1. 易于配置:无需编码即可自定义微调参数
通过LLAMABOARD,用户可以通过简单的图形界面来配置微调参数,如学习率、批次大小等。该界面为用户提供了默认的参数值推荐,同时也允许用户根据自己的需求进行自定义,极大地简化了模型微调的配置过程。
2. 可监控训练:实时可视化训练日志和损失曲线
在模型训练过程中,LLAMABOARD实时更新并可视化训练日志和损失曲线,使用户能够实时监控训练进度和模型性能。这一特性为用户提供了及时调整训练策略的依据,有助于提高模型微调的效率和效果。
3. 灵活评估:支持自动和人工评估模型性能
LLAMABOARD支持在数据集上自动计算文本相似度分数来评估模型性能,同时也提供了与模型交互的界面,允许用户通过与模型的对话来进行人工评估。这种灵活的评估方式使用户能够从不同角度全面了解模型的性能,为进一步优化模型提供了宝贵的反馈。
通过这些实用的工具和特性,LLAMA FACTORY为广大研究者和开发者提供了一个高效、便捷的平台,以促进LLMs在各种应用场景中的发展和应用。
实证研究:框架的训练效率和任务适应性验证
1. 训练效率的实验设置和结果分析
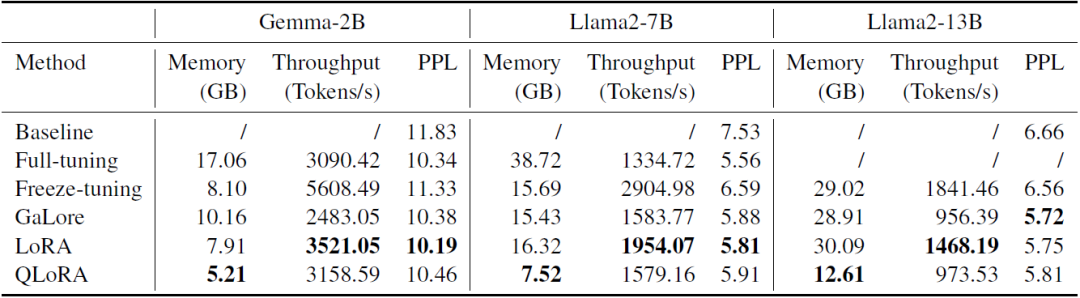
在LLAMA FACTORY框架的训练效率实验中,研究者们选择了PubMed数据集作为训练材料,该数据集包含超过3600万条生物医学文献记录。从这些文献的摘要中提取了约40万个token作为训练样本。实验涉及了多种不同的高效微调方法,包括全参数微调(Full-tuning)、冻结微调(Freeze-tuning)、GaLore、LoRA以及4位QLoRA。实验中,研究者们使用了Gemma-2B、Llama2-7B和Llama2-13B模型,并通过计算在训练样本上的困惑度(Perplexity, PPL)来评估不同方法的效率。
实验结果显示(下表,粗体字是最佳结果),QLoRA在内存占用上一致表现最佳,这得益于其在低精度下表示预训练权重。而LoRA则在吞吐量上表现更优,这是由于使用了Unsloth对LoRA层进行的优化。在大型模型上,GaLore在降低PPL方面表现更好,而在较小的模型上,LoRA则具有优势。这些结果凸显了高效微调方法在适应特定任务时的有效性。
2. 在下游任务上的微调效果评估
为了评估不同高效微调方法的任务适应性,研究者们在多个下游任务上进行了实验。这些任务包括CNN/DM、XSum和AdGen,分别代表了文本摘要和广告文案生成等文本生成任务。实验中选取了多个指令调优模型,并采用序列到序列的任务进行微调。比较了全参数微调(FT)、GaLore、LoRA和4位QLoRA的效果,并在每个任务的测试集上计算了ROUGE得分。
实验结果表明(下表,粗体字是最佳结果),除了Llama2-7B和ChatGLM3-6B模型在CNN/DM和AdGen数据集上,LoRA和QLoRA在大多数情况下都取得了最佳性能。这表明这些高效微调方法在特定任务上具有良好的适应性。此外,Mistral-7B模型在英文数据集上表现更好,而Qwen1.5-7B模型在中文数据集上得分更高,这表明微调后模型的性能也与其在特定语言上的固有能力有关。

结论与未来工作:总结LLAMA FACTORY的贡献和展望
LLAMA FACTORY框架通过模块化设计,最小化了模型、数据集和训练方法之间的依赖性,并提供了一个集成化的方法,可以使用多种高效微调技术对超过100种语言模型进行微调。此外,该框架还提供了一个灵活的Web UI LLAMABOARD,使用户能够在无需编码的情况下自定义微调和评估语言模型。通过在语言建模和文本生成任务上的实证验证,证明了框架的效率和有效性。
未来,研究者们计划持续将LLAMA FACTORY与最新的模型和高效微调技术保持同步,并欢迎开源社区的贡献。在未来的版本中,研究者们将探索更先进的并行训练策略和多模态高效微调语言模型。














