
机器学习在许多应用中取得了显著成功。然而,现有的研究大多基于封闭世界假设,该假设认为环境是静态的,一旦部署模型就是固定的。在许多真实世界的应用中,这一基本而又幼稚的假设可能不成立,因为一个开放的环境是复杂的、动态的,并且充满未知。在这种情况下,拒绝未知,发现新奇性,然后逐步学习它们,可以使模型像生物系统一样安全地并持续地进化。本文提供了一个关于开放世界机器学习的全面视角,通过研究未知拒绝、新类发现和类增量学习在一个统一的范式下进行。当前方法的挑战、原则和局限性被详细讨论。最后,我们讨论了几个未来研究的潜在方向。本文旨在提供一个关于新兴开放世界机器学习范式的全面介绍,以帮助研究人员在各自的领域中构建更强大的AI系统,并促进人工通用智能的发展。
https://arxiv.org/abs/2403.01759
人工智能结合机器学习技术在医疗治疗[1]、工业[2]、交通运输和科学发现[3]等许多领域得到了广泛应用。通常,监督式机器学习涉及孤立的分类或回归任务,它学习一个函数(模型)f : X → Y,从一个包含特征向量和真实标签对的训练数据集D = {(xi, yi)}^N_{i=1}学习。然后,可以将模型f部署用于预测未来遇到的输入。然而,机器学习当前的成功在很大程度上基于封闭世界假设[5, 6, 7],其中学习的重要因素限于训练期间观察到的内容。在分类任务中,模型在部署期间遇到的所有类y都必须在训练中被看到,即y ∈ Y。这个假设在可能的类别已经明确定义且不太可能随时间改变的限制场景中是合理的。例如,在手写数字识别任务中,封闭世界假设成立,因为数字集合(0-9)是固定的并且提前已知。此外,这个假设也使数据收集过程更加简单直接。然而,真实世界的应用往往涉及动态和开放的环境,其中不可避免地会出现意外情况,可能出现属于未知类别的实例(y ∈ Y /)[8, 9]。例如,在非稳态环境中,自动驾驶汽车可能遇到以前从未学过的新奇对象;在网络使用和面部识别系统中,无数的新类别会不断出现。在这种情况下,封闭世界假设可能会出现问题。首先,模型对未知的过于自信,毫不犹豫地将其预测为训练类别[10, 11, 12],这可能导致从财务损失到伤害和死亡的各种危害。其次,模型未能通过发现和聚类它们来外推到新的类别[13]。第三,学习新的流数据会导致对先前知识的灾难性遗忘[14]。为了在这样一个不断变化的无穷多样的场景中学习,我们需要开放世界学习来克服这些限制,通过适应真实世界数据的动态和不确定性。在这种范式下,模型被装备以识别和拒绝偏离训练类的输入以保持安全,然后从未知中发现新类并逐步学习它们,无需从头开始重新训练整个模型。
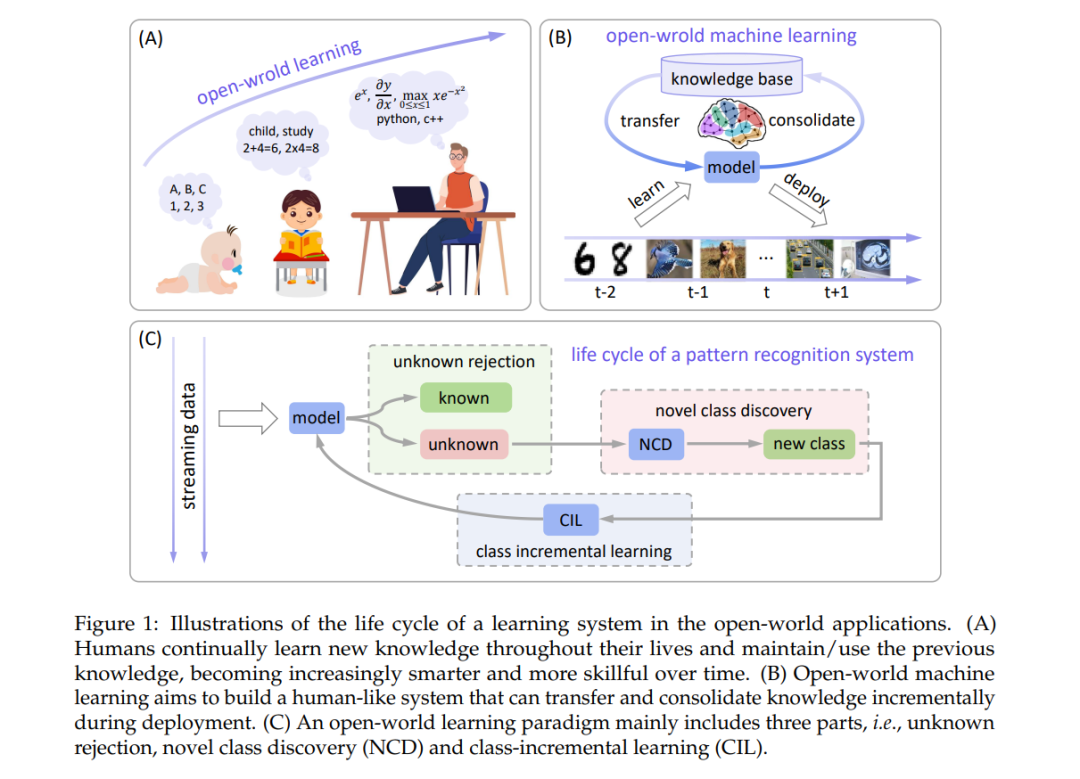
开放世界学习(OWL)范式的一般生命周期如图1所示。这个过程主要包括三个关键步骤。第一步是未知拒绝,要求模型识别属于已见类的测试实例,同时也能够检测或拒绝不属于训练类的错误分类和未知实例,基于可靠的置信度估计[11, 15]。第二步是新类发现[13],它基于过去学到的知识自动地将收集到的未知样本在缓冲区中聚类。最后,当发现的类有足够的数据时,系统必须扩展原始的多类分类器,以包含新类,而无需从头开始重新训练或灾难性地忘记先前学到的知识[16, 17, 18]。通过整合未知拒绝、新类发现和持续学习,系统能够适应并扩展到不断演变的环境。换句话说,模型可以意识到它不知道的内容,并在开放世界中部署后(在工作中)像人类一样交互式学习。
在本文中,我们对开放世界机器学习的最新研究进展进行了系统综述,重点讨论了有关未知拒绝、新类发现和类增量学习的技术。详细讨论了当前方法的原则和局限性及其之间的关系。最后,介绍了开放世界机器学习未来发展的可能挑战、研究空白和展望。我们广泛而深刻的综述将有助于研究人员将这一新的学习范式应用于他们自己的领域,并呼吁构建类似人类的、真正智能的系统。
开放世界学习的总体挑战
如图1和图2所示,开放世界学习涉及顺序地和定期地执行未知拒绝、新类发现和类增量学习。核心挑战是使上述过程能够通过模型与开放环境之间的交互自动进行,而不依赖于人类工程师[26]。不幸的是,在封闭世界假设[7]下,模型过于自信,几乎无法意识到未知。具体来说,从表示学习的角度来看,模型仅在当前数据集上受到数据驱动的优化训练,学到的表示是任务特定的且较不通用;从分类器学习的角度来看,当前的判别分类器为未知留下的空间很小,使得难以描述、发现和适应新奇性。因此,来自未知类的示例将被映射到已知类的区域,导致在后续的增量学习过程中发生之前知识的灾难性遗忘。

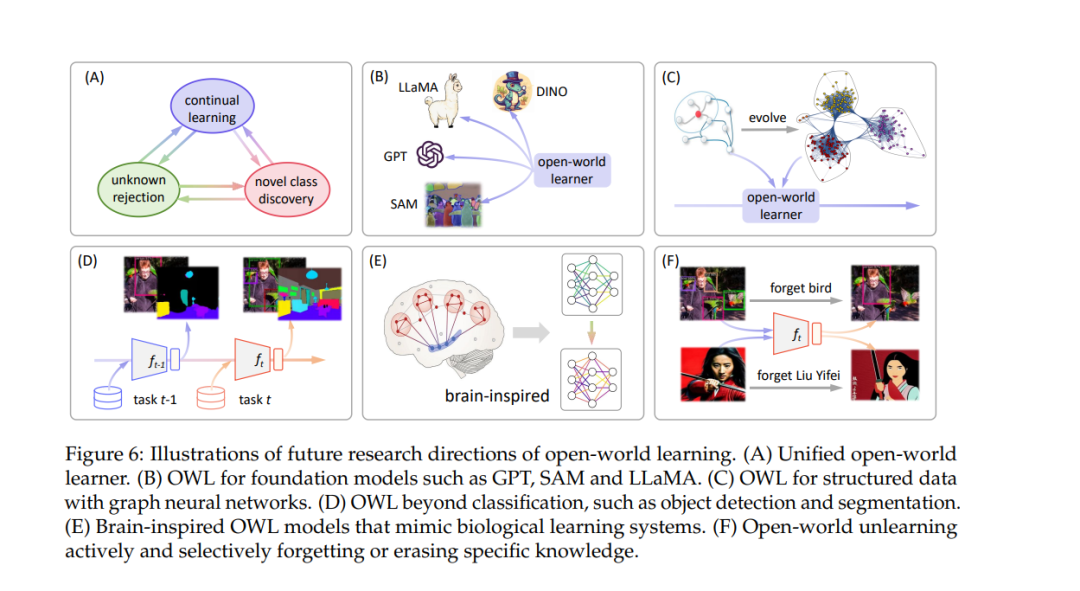
开放世界机器学习是一个活跃且长期的研究话题,存在许多值得进一步探索的关键开放方向。在本节中,我们简要概述了几个有前景的研究方向,这些方向使OWL能够在统一的框架和更复杂的情境中实现,例如结构化数据和应用,如检测、分割等。此外,还讨论了考虑脑启发式OWL和机器遗忘的额外方向。图6展示了未来方向的插图。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)

点击“阅读原文”,了解使用专知,查看获取100000+AI主题知识资料








