标题:Ten deep learning techniques to address small data problems with remote sensing
期刊:International Journal of Applied Earth Observation and Geoinformation

研究人员和工程师越来越多地将深度学习(DL)用于各种遥感(RS)任务。然而,来自当地观测或通过地面实况的数据对于训练DL模型通常是非常有限的,特别是当这些模型代表关键的社会环境问题时,例如监测极端,破坏性气候事件,生物多样性和生态系统状态的突然变化。这类案例也被称为小数据问题,在方法论上提出了重大挑战。这篇综述总结了RS领域的这些挑战,以及使用新兴的深度学习技术克服这些挑战的可能性。我们表明,小数据问题是跨学科和尺度上的共同挑战,导致模型的通用性和可移植性差。然后,我们概述了十种有前途的深度学习技术:迁移学习、自监督学习、半监督学习、少次学习、零次学习、主动学习、弱监督学习、多任务学习、过程感知学习和集成学习;我们还包括一种被称为空间k-fold交叉验证的验证技术。我们的特别贡献是开发了一个流程图,帮助DL用户通过回答几个问题来选择使用哪种技术。我们希望这篇综述文章能够在有限的参考数据下,促进深度学习应用于解决重要的社会环境问题。
在过去十年中,人工智能(AI)技术,特别是机器学习(ML)和深度学习(DL),越来越多地用于理解和预测人类与环境的相互作用(LeCun et al, 2015)。机器学习是人工智能的一个子集,它实现了使用数据来学习如何执行特定任务而无需显式编程的算法。深度学习是机器学习的一个子集,专注于训练能够从非结构化数据(如图像、文本和声音)中提取隐式特征的深度神经网络(Chai等人,2021;Lauriola等人,2022;Sztaho等人,2021)。科学家们积极利用深度学习进行图像处理和数据分析,最近在遥感(RS)领域提供了创新的解决方案来检测和分类地球上的物体。本研究将遥感定义为使用卫星和飞机传感器。
RS的扩展领域提供了来自众多来源的大量数据流。这与不断增长的可用数据产品阵列相结合,提供了广泛的数据,可用于解决各种问题。其中,陆地卫星自1970年代初开始运作,提供独特的30米空间分辨率的长期卫星图像记录。哥白尼计划的哨兵-2系统生成10米空间分辨率的数据,提供空间细节和数据连续性之间的平衡,以及基于哨兵-1任务的雷达图像。最近启动的一项高光谱任务,即环境测绘和分析计划(EnMap),以200多个光谱带和30米的空间分辨率脱颖而出;这为研究人员详细描绘生态系统及其变化提供了独特的机会。此外,商业平台,如SkySat,提供空间分辨率不到一米的极高分辨率数据。总之,这些不同的遥感平台有助于更全面地了解不同尺度和领域的地球表面(Spoto等人,2012)。因此,这些RS产品被广泛用于研究当地和区域环境问题,包括农业生产力(Sawada et al ., 2020;Taiwo et al ., 2023),湖泊和池塘的水质(Bhateria and Jain, 2016),森林和草原的生态格局(Zhu et al ., 2023),以及极端天气事件对自然、耕地和居住土地的破坏。由于RS产品的时空分辨率可能会继续提高,因此DL应用有望在解决精细尺度的局部问题方面变得更加流行,因为每个局部站点都有自己独特的条件和背景(Bai等人,2022b;Kattenborn et al, 2021;Ma et al ., 2019a)。
由于深度学习算法比传统的机器学习算法具有更少的归纳偏差,但更大的参数计数,因此深度学习模型通常需要大量的数据进行训练(Adugna等人,2022;Akar and gengor, 2012;Fang等,2021;Sharma et al ., 2013;Thanh Noi and Kappas, 2018)。DL方法通常从原始数据中学习,跳过手动特征工程步骤;这意味着不需要人工来定量地度量数据中的某些属性。例如,深度学习算法可以直接从图像数据中学习,而不是使用提取的图像中物体的形状和大小。当有足够的数据可用时,深度学习方法可以自动从低到高水平提取有意义的特征进行预测(Zhang et al, 2019a)。然而,尽管常见事件的原始数据通常丰富,但缺乏足够的标签信息使得收集和准备大型参考数据集(Russakovsky等人,2015)成为许多RS应用的持续挑战。此外,某些场景还缺乏可用的参考数据。例如,生物多样性监测需要大量在分类分类方面受过良好训练的人类观察员,这通常会阻止观察活动生成足够大的数据集,以用于健全的DL应用程序。此外,极端气候和疾病爆发等异常事件过于罕见,研究人员无法获得足够的数据覆盖。他们的样本量通常小到n = 1-300,这通常不足以用于深度学习应用(Kokol et al, 2022)。
RS图像的大数据可用性与几个重要的现实世界环境问题(称为“小数据问题”)的小数据可用性(Brigato和Iocchi, 2020)之间的差距是一个非常常见的挑战。很难获得与输入特征相关联的真值响应标签。这是有道理的,因为大多数这些研究的目标是开发一个模型,旨在从各种观察到的输入特征中预测特定的响应变量。然而,传统的深度学习训练方法需要大量的初始标记数据集来训练预测模型。越来越明显的是,这是人工智能的一个新兴问题,研究人员已经提出了几种需要较少标记数据的新型深度学习技术(例如,迁移学习和自监督学习)。然而,据我们所知,还没有一篇综述文章概述了这些技术及其在RS领域中的应用。
我们认为,当数据集由> 100,000个带注释的样本组成,或者当它覆盖了高维空间中的整个概率分布时,数据集可以被认为是大的(而不是小的)。例如,有几个免费的大型数据集可以用于深度学习:ImageNet数据集,包含超过1400万张带注释的图像(Russakovsky等人,2015),上下文中的公共对象(COCO)数据集,包含330 K张图像,150万个对象实例和80个对象类别(Lin等人,2015),以及OpenImages数据集,包含超过900万张图像(Kuznetsova等人,2020)。这些数据集可用于训练具有数千到数百万个参数的大型深度学习模型。在遥感领域,土地利用/土地覆盖分类就是一个典型的例子。在这些情况下,模型的通用性和可移植性期望很高。概括性是指深度学习模型对新的、未见过的数据做出准确预测的能力(Habib et al, 2023;Krois等人,2021;Shah等人,2022),可转移性是训练后的模型在不同于最初训练模型的任务或数据集上表现良好的能力(Rom ~ ao等人,2020;Wang et al ., 2019b;Zhang et al, 2020)。
相比之下,当数据集包含< 1,000个带注释的样本时,数据更有可能被视为小(或不够大),数据集覆盖分布较差,或者在使用深度学习寻找有意义的特征时,预计样本数量不足。值得注意的是,不仅是数据总量问题,类不平衡和数据分布偏斜也可以看作是小数据问题的一部分。这是一个经常发生的情况,但它可能是训练深度神经网络的重大挑战(Adadi, 2021;Du et al, 2019)。由于过度拟合,相对较小的数据集可能会对深度学习模型的性能产生负面影响,过度拟合是指模型在训练数据上表现良好,但在新的独立测试数据上表现不佳。因此,这导致了低水平的模型通用性和可移植性。RS领域内的一个常见情况(但特别相关)是数据可能"特别小",这意味着数据集仅由1-10个带注释的样本组成(例如,历史自然灾害和疾病暴发)。这个大小足以让人类开始猜测哪些特征可以唯一地描述目标,但对于自动、隐式的深度学习特征提取来说,它还不够。
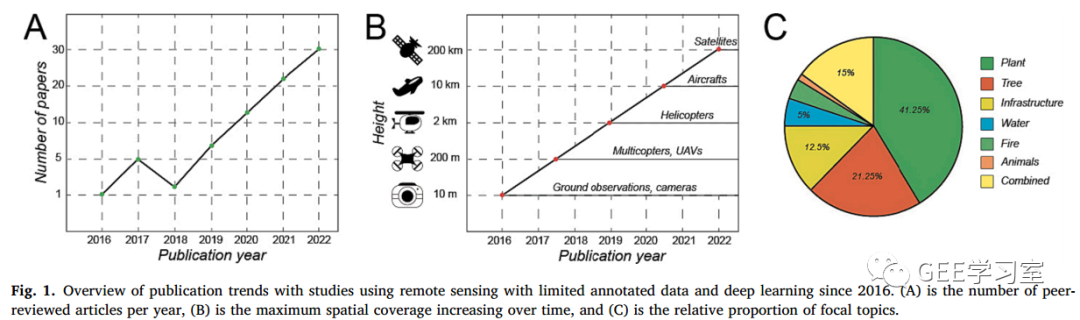
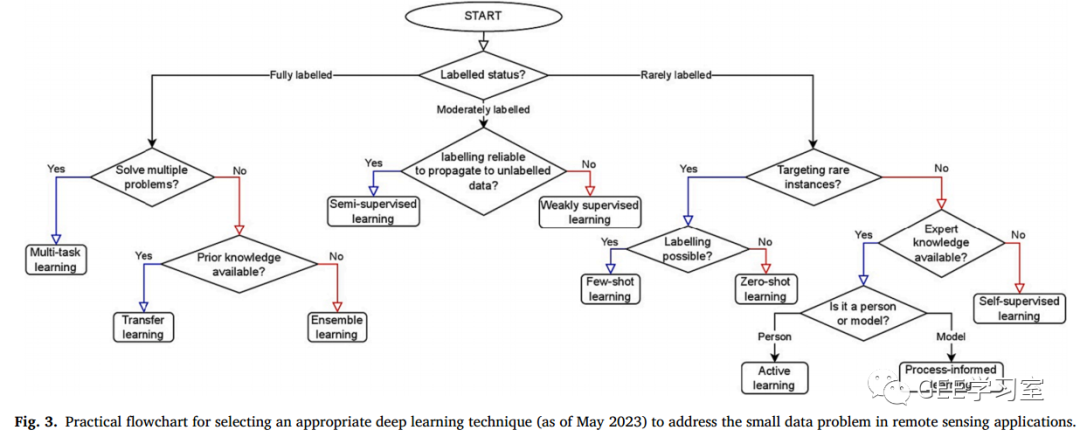
我们注意到数据增强和迁移学习很受欢迎,但其他技术也很有前途。为了解决这个问题,本节就DL的实施策略提供了实用的建议。我们介绍了以下技术:TL、自监督学习、半监督学习、少次学习、零次学习、弱监督学习、过程学习、多任务学习和集成学习。本节的文献检索与之前主要问题的检索方式相同。然而,我们添加了一个查询,能够返回应用上述技术之一的研究(例如,“迁移学习”,“半监督学习”,“少量学习”)到主要搜索关键字。此外,表1简要总结了用于小数据集的每种深度学习技术的优缺点。截至2023年2月16日,我们发现了37篇文章(图2)。我们还提供了一个实用的流程图,用于决定在每个特定用例中使用哪种算法:我们认为这个流程图是对深度学习用户的独特贡献,因为它可以帮助以简单的方式确定用于不同用例的技术(图3)。我们没有明确涵盖其他方法,如数据增强和正则化,因为它们已经在各种文献中被广泛覆盖,例如(Shorten和Khoshgoftaar, 2019)的工作。



交流合作
GEE学习室是一群由认真学习和使用GEE等遥感大数据平台的高校博士生(含在读和已毕业)组建的团队,致力于GEE等大数据原创和优质算法开发,希冀通过团队的努力为遥感大数据智能处理普及和广大学子科研之路提供绵薄之力、荧荧之光。本学习室业已创建了4个学习交流群,即博学群、明辨群、如琢群和修远群,来自各地高校和研究所,涵盖本科、硕士和博士群体,交流群每天活跃度非常高。想加入交流的加小编微信邀请进群(扫描下方二维码咨询报名或菜单栏“联系我们”选项框都可以找到小编哟)。
注意,咨询加群验证信息请备注为“研究方向-学校-加群”格式,否则不予通过。例如,假如你是武汉大学的土地利用分类方向的研究生,则可以备注“LULC-武大-加群”;假如你是北京大学的生态学方向的研究生,则可以备注“生态学-北大-加群”。











