在进行数据分析时,我们所用到的数据往往都不是一维的,而这些数据在分析时增加了不少难度,因为我们需要考虑各个维度之间的关系。而这些维度关系的分析就需要用一些方法来进行衡量,相关性分析就是其中一种。本文就用Python通过绘图的方式来解释一下数据的相关性。
这里分享一些期刊上的美图:
图1:https://doi.org/10.1128/aem.00352-11
图2:https://doi.org/10.3390/w14132120
图3:https://doi.org/s41586-022-05292-x
首先加载所需要用的python包。如果需要更改颜色,将True改成False
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns; sns.set(color_codes=True)
第二步导入数据,本文用的数据来自唐白河流域数据,三个水文站69年洪峰流量和水位数据,其中B、C站是A站的上游测站,共69个6维数据。存储在hy.csv文件中。通过pandas导入并展示数据的相关性情况。
df=pd.read_csv('D:\\桌面\\hy.csv')df.head()
也可以使用绘图库seaborn自带的数据,想熟悉流程的同学可以自行练习。
df = sns.load_dataset('iris')
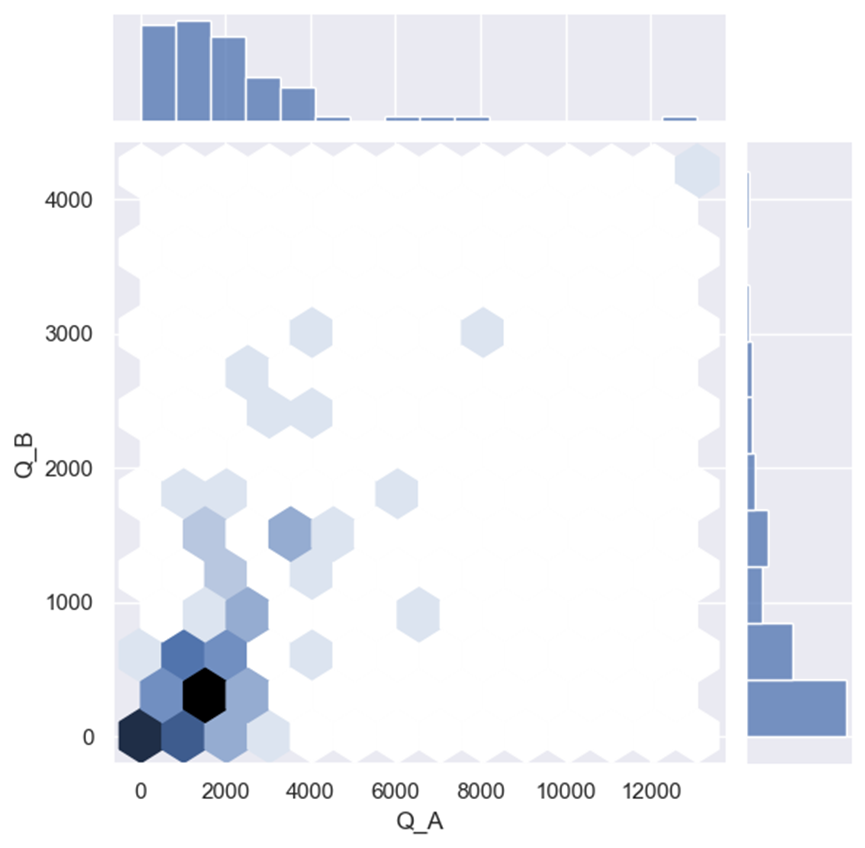
1、首先来做一个比较简单的分析,即分析这个数据集中第1列和第3列的相关性,也就是Q_A和Q_B。
sns.jointplot(x ='Q_A', y ='Q_B', data = df,kind = 'reg')
第二种可以将点改为蜂窝状的六边形网格。
代码如下:
sns.jointplot(x ='Q_A', y ='Q_B', data = df,kind = 'hex')
2、利用seaborn库绘制的普通相关关系图。
代码如下:
生成图片如下:
这一行代码结果如所示,是一张大图,其中包含36个子图,每个子图都是每个维度和其他某个维度的相关关系图,这其中主对角线上的图,则是每个维度的数据分布直方图。
也可以利用seaborn绘制以第一列列数据为基准的相关关系图。
代码如下:
sns.pairplot(df , hue ='Q_A');
生成图片如下:
这一行代码是画出同样的图形,但却以Q_A这个维度的数据为标准,来对各个数据点进行着色,其结果如图所示。从图中可以看出,Q_A这列数据共5个不同的数值,每个数值一种颜色,所以生成的图是彩色的。
3、利用pandas库生成的相关关系图。
代码如下:
pd.plotting.scatter_matrix(df,figsize=12,12),range_padding=0.8);
生成图片如下:
可以看到用pandas绘制的图和seaborn的大体结果一样,但图片的可定制程度和精细度还是略差一些,所以一般情况下建议用seaborn。
4、利用seaborn库绘制相关关系热力图。
代码如下:
#相关性热力图sns.heatmap(df.corr())
生成图片如下:
代码如下:
#聚类相关性热力图sns.clustermap(df.corr())
生成图片如下:
以上便是本期图绘的诚意分享啦,希望能对大家的科研工作有所帮助,欢迎大家持续关注我们!一图胜千言!水文图绘改版后致力于分享水文相关的精美图表,为读者提供作图思路和经验,帮助大家制作更漂亮丰富的图表。同时欢迎留言咨询绘图难点,我们会针对性地分享相关绘制经验。另外也期待读者踊跃来稿,分享更好的构图思维和技巧,稿件可发送至邮箱hydro90@126.com, 或者联系微信17339888901投稿。