摘要:
针对传统的道路提取方法在高分辨率遥感影像中存在提取效果差和提取速度慢的问题,提出了改进Deeplabv3+的高分辨率遥感影像道路提取模型。采用MobileNetv2主干特征提取网络与Dice Loss函数相结合,较好地平衡了高分辨率遥感影像道路提取精度与速度的矛盾,实现较高提取精度的同时减少了模型参数,满足了时效性的要求。基于开源道路提取数据集的实验结果表明: ①该文提出的道路提取模型在高分辨率遥感影像上具有可行性,提取道路的整体精度达到98.71%,具有较高的提取精度; ②在提取道路的速度方面该方法平均帧数达到120.05,模型参数量仅为5.81 M,总体上比原模型更加轻量化,表明该方法满足了时效性的要求。该方法在大幅减少参数量、满足时效性的同时保证了提取的精确度,为提高基于高分辨率影像的道路提取精度和速度提供了一种新的改进思路和方法。
引言
道路是人类在生活与工作中不可或缺的元素,如改善民生生活条件及配套设施,提供出行便利; 提高城市各项工作的运行效率,加快城市化建设; 优化城市资源配置,便于各项特色资源的输入输出等。道路信息也是重要的地理信息,是城市地理信息数据库的重要组成部分。随着遥感技术的快速发展,遥感图像的空间分辨率也在逐步提高,目前已经达到亚米级别,并且发展趋势呈上升态。随之而来的是地物特征的细节信息更加丰富,非道路信息(植被阴影、车辆流动、高层建筑物遮挡和人流流动)非常复杂,因其作为噪声使得提取道路目标信息更加困难。此外,具有不同质地材料的道路在识别的过程中将具有不同的光谱特征[1],它们表现为不同道路具有相同光谱或同一道路具有不同光谱。目前,绝大多数道路提取采用半自动化方式,半自动化方法是需要人工给定道路的起始点,按照特定的规则和逻辑提取道路信息,Kass等[2]提出的Snake算法; 罗庆洲等[3]利用光谱特征和形状特征识别道路的方法; Ghaziani等[4]提出利用二值图像分割提取道路的方法; Sirmaçek等[5]利用边缘检测和投票机制进行道路的提取。半自动化道路提取方式具有算法鲁棒性差、识别精度低、流程繁琐等一系列问题,一般适用于中低空间分辨率的遥感影像,而不太适用于高空间分辨率的遥感影像[6]。因此,研究一种自动的针对高分辨率遥感影像的道路提取方法具有非常重大的意义。
深度学习是机器学习的一个分支,传统机器学习需要人工设计特殊的特征量,如尺度不变特征转换(scale-invariant feature transform,SIFT)和方向梯度直方图(histogram of oriented gradient,HOG)等,而深度学习直接学习数据本身,数据中包含的所有特征都由机器来学习。深度学习网络利用训练数据的损失函数进行误差的反向传播从而实现参数的更新,这样就能达到直接从数据中学习的目的[7]。近些年来随着深度学习在计算机视觉中的兴起[8],其在图像的识别、分类和分割中都取得了较大的突破。最近几年,也有越来越多的学者将深度学习应用于遥感影像的道路分割。Mnih等[9]最先提出使用卷积神经网络(convolutional neural network,CNN)提取遥感影像的道路,并采取条件随机场(conditional random field,CRF)进行后处理细化分割效果,但分割精度并不高,存在明显的椒盐噪声; 叶雪娜[10]比较了基于小批量梯度下降(mini-batch gradient descent,MBGD)和基于拟牛顿法(BFGS method)的CNN在道路提取上的效果,结果表明BFGS算法不需要计算梯度,不用考虑学习率参数设置问题,不会出现训练过程中梯度下降缓慢或发生震荡的现象; Long等[11] 提出了全卷积网络(fully convolution network,FCN),其旨在于对图像进行像素级的分类,即对每个像素都产生了一个预测,从而解决了语义级别的图像分割问题。FCN就是将CNN最后的全连接层替换为卷积层,称为反卷积,采用反卷积层对最后一个卷积层的特征图进行上采样, 使它恢复到输入图像相同的尺寸,在预测每个像素的同时还保留了空间信息。但全卷积的结果比较模糊,对图像中的细节不够敏感,且只考虑了单个像素的预测,没有关注像素与像素之间的关系,缺乏空间统一性。Chen等[12]提出Deeplabv1模型,采用空洞卷积进行特征提取并利用条件随机场恢复边界信息。Deeplabv2在Deeplabv1基础上引入了空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)并采用残差网络(residual neural network,Resnet)作为主干网络。Deeplabv3改进了空洞空间金字塔池化模块,加入了批量归一化层(batch normalization,BN),加快了网络收敛速度避免了网络过拟合。Deeplabv3+[13]引入编码-解码结构且再次修改了主干网络,将残差网络升级为Xception网络,使物体边界分割效果更好。
随着网络深度和结构的不断加深与复杂,分割精度在不断提升,但随之而来的是网络参数的规模也愈发庞大。因此,本文针对深度学习的道路提取在算力有限的计算机和嵌入式系统等设备上的应用,研究一种基于Deeplabv3+的道路提取网络,在满足较高提取精度的前提下实现了实时处理。
1.1 整体流程
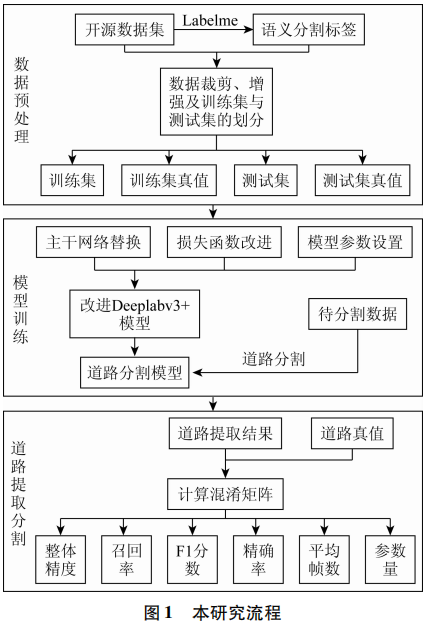
高分辨率遥感影像道路提取实质上是一种二元的语义分割问题,语义分割的主旨是为图像中的每一个像素都分配一个语义标签,即为图像中的每一个像素都进行分类[14]。本文提出了基于Deeplabv3+的轻量化高分辨遥感影像道路语义分割模型。整体流程可以分为3个阶段: 首先,遥感影像数据的预处理阶段包含对图像的标注、裁剪、增强以及训练集与测试集的划分等; 其次,模型的训练阶段包含参数的设置、主干特征提取网络的替换和损失函数的改进等方面; 最后,遥感影像道路的提取分割,并对提取结果进行评价,如图1所示。
1.2 Deeplabv3+网络模型
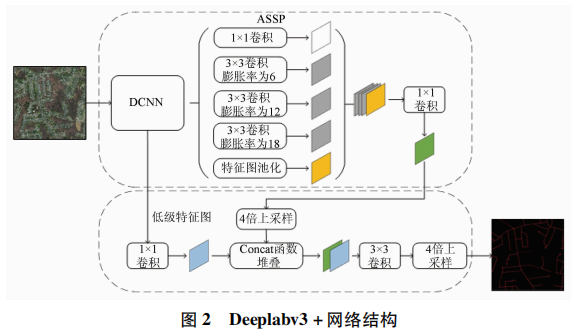
Deeplabv3+以编码-解码为基础结构。其中编码器负责特征抽取,将输入的图像编程为中间表达形式,即逐渐减小特征图并提取高层语义信息。相应的解码器负责将中间表达形式解码为输出,逐渐恢复图像的空间信息并给每个像素分类,Deeplabv3+的整体网络结构如图2所示。其编码部分包括作为主干网络的深度卷积神经网络(deep convolutional neural networks,DCNN)和ASPP这2个部分。其解码部分,接收来自主干网络中间层的低级特征图和来自ASPP模块的输出作为输入。首先,对低级特征图使用1×1卷积进行通道降维; 然后,对ASPP模块的特征图进行4倍上采样得到与低级特征图尺寸相同的特征图; 再使用Concat函数将上述2种特征图堆叠起来,一起送入3×3卷积块进行特征融合; 最后,进行线性插值上采样得到与原始图像分辨率大小相等的预测图。
1.3 改进Deeplabv3+网络模型
Deeplabv3+原文中所用的主干网络是Xception特征提取网络,但Xception对模型的参数规模和运行速度控制不佳,所以本文采用MobileNetv2[15]特征提取网络作为主干网络以提升模型的提取效率; 并且针对遥感影像中道路提取类别不均衡的问题,本文采用Dice Loss与交叉熵损失函数相加作为损失函数来解决样本极度不均衡的情况。
1.3.1 MobileNetv2网络
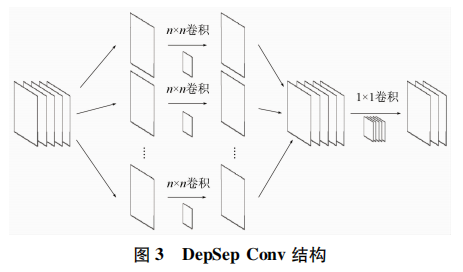
MobileNetv2是Google提出的一个轻量化CNN,其将MobileNetv1中的深度可分离卷积(depthwise separable convolution,DepSep Conv)沿用,与常规卷积不同的是DepSep Conv是将一个完整的卷积分解成2步进行,分别是深度卷积与逐点卷积,图3为DepSep Conv示意图。相比常规的卷积操作,其参数规模和运算成本比较低。
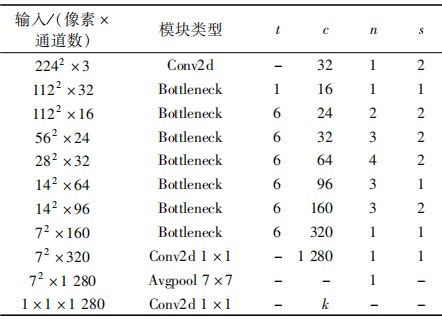
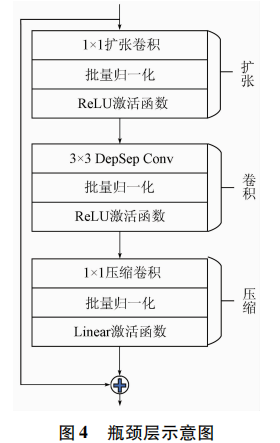
首先MobileNetv2是由多个瓶颈层构成的,如表1所示,其中t为输入通道的倍增系数,c为输出通道数,n为该模块重复的次数,s为该模块第一次重复时的步长,k为实际输出的通道数。每个瓶颈层都包含扩张、卷积和压缩3个部分(图4)。其中扩张是利用1×1卷积来增加特征图的通道数; 卷积是用3×3的DepSep Conv提取图像每个通道的特征以此减少模型参数; 压缩是利用1×1卷积来减少特征图的通道数。通过扩张、卷积、压缩这3个过程可以在保留空间信息的同时提取更多的通道信息。在最后的压缩过程后,如果仍使用ReLU函数就会有较大的信息丢失,因此为了减少信息丢失使用Linear作为激活函数。其次MobileNetv2为每个瓶颈层加入了残差连接使得网络训练精度有明显的提升。
1.3.2 ASSP多特征提取模块
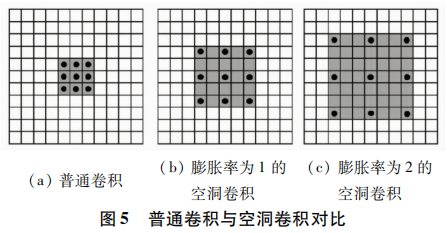
在一张图像中,如果一个像素只看到它相邻的像素则无法判断此像素的类别和属性,那就应该增加观察的视野以将更多的像素点纳入考察范围。在CNN中“视野”被称为感受野,通过增大感受野来捕获图像的上下文信息,增大感受野的方式一般有池化和增大卷积核,但这2种方法带来的是计算量和参数量的激增。空洞卷积就是权衡感受野与计算量的明智之选,在增大感受野的同时又不增加计算量与参数量。空洞卷积就是在一般的卷积核中添加空洞,空洞的值为0,膨胀率越大添加的0越多,感受野也越大,如图5所示。Deeplabv3+采用ASSP模块进一步提取多尺度的特征信息,ASSP使用不同膨胀率的空洞卷积来实现多尺度特征提取,其中包括一个1×1卷积、膨胀率为6的3×3空洞卷积、膨胀率为12的3×3空洞卷积、膨胀率为18的3×3空洞卷积和一个特征图池化层,最后将这5个部分的特征图进行堆叠。
1.3.3 类别不平衡修正
在神经网络的学习中,寻找最优参数时,要寻找使损失函数的值尽可能小的参数。为了找到使损失函数的值尽可能小的参数,需要计算损失函数关于参数的导数(梯度),然后以这个梯度为指引,逐步更新参数的值,在这个过程中损失函数的确定尤为重要,它可以影响分类的精度。
2.1 实验数据集
本文的实验数据来自Massachusetts Roads[16]遥感道路语义分割数据集,Massachusetts Roads遥感道路语义分割数据集覆盖了美国马萨诸塞州超过2 600 km2的面积,包含城市、城镇、农村和山区等多种地区的道路信息,图像大小为1 500像素×1 500像素,空间分辨率约为1 m。由于该数据集的样本存在严重的图像与标签数据丢失现象,经过人工筛选去除不符合要求的图像与标签,对于存在漏标与错标的标签使用Labelme软件重新标注。由于计算机性能的限制原始大小图像无法输入网络训练,所以将原始遥感图像和标签图像以256步长进行裁剪,裁剪过后的图像大小为256像素×256像素。同时对训练集应用图像增广,图像增广在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模,并且随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力,本文采取旋转、水平和垂直翻转、改变颜色、高斯模糊等多种图像增广技术。最终得到8 575张道路图像以及对应标签图像,并按照9∶1分配训练集与测试集。
2.2 评价指标
为了从多个维度对提取结果进行评价,实验选取整体精度、精确率、召回率、F1分数、平均帧数及参数量作为评价指标。
3.1 模型训练实验
3.1.1 模型训练实验环境及参数设置
本文实验环境为: 操作系统为64位Windows10,CPU型号为Intel i5-10400f,内存为16 GB,GPU型号为GeForce1060显存为6 GB及CUDA并行计算平台实现GPU编程加速。模型基于Pytorch深度学习框架搭建网络结构,损失函数加入Dice Loss以解决正负样本不均衡带来的训练问题,并采用Adam(adaptive moment estimation)优化器算法优化权重更新。实验还引入迁移学习的策略,将在ImageNet上训练好的MobileNetv2网络权重作为实验的初始权重,使用迁移参数初始化网络能够提升泛化性能。所以训练分为2个阶段: 阶段一为冻结主干特征提取网络阶段,冻结主干特征提取网络意味着权重不进行更新,是为了防止权重在一开始就被破坏; 阶段二是解冻主干特征提取网络阶段,也就是需要更新主干网络的权重来达到更高的精度。阶段一的初始学习率为0.000 5,批处理大小为8,迭代30轮,每迭代5轮学习率变为原来的0.02倍。阶段二初始学习率为0.000 05,批处理大小为4,迭代70轮,每迭代5轮学习率变为原来的0.02倍。
3.1.2 实验结果
使用Massachusetts Roads数据集对改进的Deeplabv3+网络模型进行训练,将训练好的最优模型权重提取并保存用于测试数据集的道路提取,得到被提取道路的混淆矩阵,并依据混淆矩阵计算整体精度、精确率、召回率和F1分数4项评价指标,然后计算模型的平均帧数及参数量。
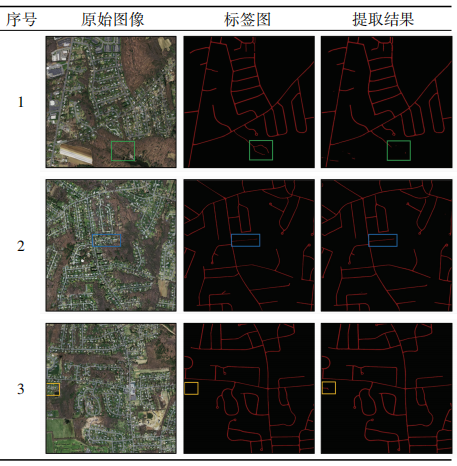
本文所改进的Deeplabv3+模型对Massachusetts Roads测试集提取道路的整体精度达到98.71%,精确率、召回率和F1分数都在87%以上,证明了模型在高分辨率遥感影像中道路提取的有效性。模型参数量为5.81 M,相比一般深度神经网络模型大幅减少,说明了模型的轻量化。平均帧数达到120.05,即每秒平均能提取120张256像素×256像素图像的道路,证明了模型在高分辨率遥感影像中道路提取的时效性。部分道路提取结果如表2所示,可以看到提取结果与真实道路基本吻合,也不存在传统提取方法所产生的椒盐噪声,提取道路边缘较为平滑。表2中绿色框表示标签图错误标注的道路,蓝色框表示道路存在被遮挡现象,橙色框表示标签图中没有标出的道路。可以看到对于标错的道路模型并没有提取,对于漏标的道路模型提取出来了,表明模型具有强大的学习能力,能较好地对道路特征进行提取,对于有遮挡现象的道路模型还具有屏蔽遮挡的能力。
3.2 对比实验及其分析
3.2.1 实验结果分析
为了进一步验证本文深度学习模型在高分辨率影像道路提取中性能和轻量化的优越性。在Massachusetts Roads数据集上,将本文模型与现有3种经典语义分割模型进行道路提取效果比较,分别是U-Net,PSPNet和Deeplabv3+,且为了比较的公平性和客观性,所有模型都在统一的环境配置中训练,测试所用的数据集也一致。U-Net是基于编码-解码结构的深度学习语义分割网络,其主干特征提取网络使用VGG-16。U-Net经常被用于医学影像的分割,道路类似于医学影像中的血管,所以U-Net可以被用来提取道路。PSPNet是基于全局金字塔池化的空洞全卷积语义分割网络,其主干网络使用与本文一致的MobileNetv2。Deeplabv3+使用Xception作为主干网络。对比结果如表3所示。
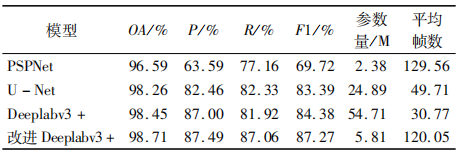
由表3可知,改进Deeplabv3+模型在整体精度、精确率、召回率、F1分数、参数量及平均帧数较其他3个模型都有不同程度的提高。PSPNet作为语义分割网络并不适用于高分辨率遥感影像的道路提取,其精度在4种网络中最低,但因其使用MobileNetv2轻量化网络使得模型参数量很小,只有2.38 M。U-Net与Deeplabv3+有着不错的分割精度,但这两者的网络参数繁多、计算量庞大导致平均帧数相对较低,不能够达到时效性的要求。反观改进Deeplabv3+模型,相比原Deeplabv3+模型,因其采用更加轻量化的主干特征提取网络MobileNetv2,使得参数量减少了89.38%,平均帧数提高了3.90倍; 因改进损失函数来平衡样本不均衡问题,使整体精度、精确率、召回率和F1分数分别提升了0.26,0.49,5.14和2.89百分点。改进后的模型在不损失精度的同时大大减少了参数量,满足了时效性的要求。
3.2.2 不同情况下道路提取分析
为了更加直观地对比4种模型的道路提取效果,选取测试集中不同情况的道路对其细节进行对比,如表4所示。

细节表现方面,在表4区域a,b和d中,因PSPNet网络模型结构不适合道路提取,导致其道路细节提取能力较弱,不能有效地分离双车道和多车道等复杂的道路情况,U-Net与Deeplabv3+模型可以分离上述道路情况,但其分离效果不佳,会产生不同道路局部粘连问题,而本文改进的Deeplabv3+模型可以有效地提取双车道和多车道信息,不同道路之间少有粘连现象,与真实道路细节基本一致; 在表4区域c中,PSPNet,U-Net与Deeplabv3+模型均不能完整地提取左下方的圆形道路,其提取结果与真实道路差别过大,结构上存在缺陷,而本文改进的Deeplabv3+模型能够完整地提取该目标区域的道路。可以看出本文方法适应于道路细节特征的提取,可以有效地提取出一些局部细节特征,在细节表现方面优于其他3种模型。在模型的适应性方面,在表4区域c中,遥感影像中道路存在被树木、建筑物及阴影遮挡或阻断现象,除了本文改进模型,其他3种模型均有不同程度不能提取被遮挡或阻断道路的情况,也就是说改进Deeplabv3+模型的屏蔽遮挡的能力较强,对遮挡道路提取效果良好。说明了本文改进模型对于复杂环境下的道路提取具有较好的适应能力。在提取准确性方面,在表4中,PSPNet模型道路提取分辨率较低,道路边缘粗糙并且存在缺失问题,道路结构损失最为严重; U-Net与Deeplabv3+提取结果接近,也都存在道路边缘粗糙和结构不完整等问题。相比于这3种方法,本文改进方法提取结果噪声较少,并且道路结构最完整。由于本文针对遥感影像中道路像素数量远小于背景像素数量,模型严重偏向于背景,导致分割效果不好的现象,提出了Dice Loss与交叉熵损失函数相加作为损失函数的方法来解决样本极度不均衡的情况,使得本文方法对各种情况下道路的提取均优于Deeplabv3+模型,改善了Deeplabv3+错提和漏提的现象,提取出的道路结构完整度较高,总体上提取效果较好。
本文以深度学习语义分割中的Deeplabv3+网络模型为基础,提出结合MobileNetv2主干特征提取网络与Dice Loss函数的改进Deeplabv3+高分辨率遥感影像道路提取模型。该方法针对遥感影像中背景与道路像素比例极度失衡的特点引入Dice Loss函数,并结合轻量化特征提取网络大大减少了模型的参数量。研究表明: 本文提出的道路提取模型在高分辨率遥感影像上具有可行性,提取道路的整体精度达到98.71%,具有较高的提取精度; 与3种经典的语义分割网络相比,在道路提取的完整性和精确度,以及树木、建筑物和阴影遮挡方面,本文方法均有较好的提取效果; 在提取道路的速度方面本文方法平均帧数达到120.05,模型参数量仅为5.81 M,表明本文方法满足了时效性的要求。本文方法在大幅减少参数量满足时效性的同时保证了提取的精确度,为提高基于高分辨率影像的道路提取精度和速度提供了一种新的改进思路和方法。
在下一步的研究中,可以针对道路的结构信息及特点,将在本文模型的基础上加入注意力机制,从而提高模型对道路的提取能力; 在数据集制作方面,标签的获取采用Labelme软件对道路进行人工标注,在这个过程中存在漏标和错标的问题,会产生一定的误差,所以可以从如何快速获取高质量的标签出发,进一步提高道路提取精度。
原标题:改进Deeplabv3+的高分辨率遥感影像道路提取模型
赵凌虎1, 袁希平2,3, 甘淑1,2, 胡琳1, 丘鸣语1
1.昆明理工大学国土资源工程学院,昆明 650093
2.云南省高校高原山区空间信息测绘技术应用工程研究中心,昆明 650093
3.滇西应用技术大学地球科学与工程学院,大理 671000
(原文有删减)
参考文献:
Herold M, Roberts D.Spectral characteristics of asphalt road aging and deterioration:Implications for remote-sensing applications
[J]. Applied Optics, 2005, 44(20):4327-4334.DOI:10.1364/AO.44.004327 URL [本文引用: 1]
Kass M, Witkin A, Terzopoulos D.Snakes:Active contour models
[J]. International Journal of Computer Vision, 1988, 1(4):321-331.DOI:10.1007/BF00133570 URL [本文引用: 1]
罗庆洲, 尹球, 匡定波.光谱与形状特征相结合的道路提取方法研究
[J]. 遥感技术与应用, 2007, 22(3):339-344.[本文引用: 1]
Luo Q Z, Yin Q, Kuang D B.Research on extracting road based on its spectral feature and shape feature
[J]. Remote Sensing Technolo-gy and Application, 2007, 22(3):339-344.[本文引用: 1]
Ghaziani M, Mohamadi Y, Koku A B, et al.Extraction of unstructured roads from satellite images using binary image segmentation
[C]// 2013 21st Signal Processing and Communications Applications Conference (SIU).IEEE, 2013:1-4.[本文引用: 1]
Sirmaçek B, Ünsalan C.Road network extraction using edge detection and spatial voting
[C]// 2010 20th International Conference on Pattern Recognition.IEEE, 2010:3113-3116.[本文引用: 1]
贾建鑫, 孙海彬, 蒋长辉, 等.多源遥感数据的道路提取技术研究现状及展望
[J]. 光学精密工程, 2021, 29(2):430-442.[本文引用: 1]
Jia J X, Sun H B, Jiang C H, et al.Road extraction technology based on multi-source remote sensing data: Review and prospects
[J]. Optics and Precision Engineering, 2021, 29(2):430-442.DOI:10.37188/OPE.20212902.0430 URL [本文引用: 1]
Krizhevsky A, Sutskever I, Hinton G E.ImageNet classification with deep convolutional neural networks
[J]. Communications of the ACM, 2017, 60(6):84-90.DOI:10.1145/3065386 URL [本文引用: 1] 
He K M, Zhang X Y, Ren S Q, et al.Deep residual learning for image recognition
[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition.IEEE, 2016:770-778.[本文引用: 1]
Mnih V, Hinton G E.Learning to detect roads in high-resolution aerial images
[C]// European Conference on Computer Vision.Springer,Berlin,Heidelberg, 2010:210-223.[本文引用: 1]
叶雪娜. 基于卷积神经网络的遥感图像道路提取研究[D]. 西安: 陕西师范大学, 2017.[本文引用: 1]
Ye X N. Research on remote sensing image road extraction based on convolutional neural network[D]. Xi’an: Shaanxi Normal University, 2017.[本文引用: 1]
Long J, Shelhamer E, Darrell T.Fully convolutional networks for semantic segmentation
[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition.Washington, DC: IEEE Computer Society, 2015:3431-3440.[本文引用: 1]
Chen L C, Papandreou G, Kokkinos I, et al.Semantic image segmentation with deep convolutional nets and fully connected CRFs
[J]. Computer Science, 2014(4):357-361.[本文引用: 1]
Chen L C, Zhu Y, Papandreou G, et al.Encoder-decoder with atrous separable convolution for semantic image segmentation
[C]// Proceedings of the European Conference on Computer Vision, 2018:801-818.[本文引用: 1]
魏云超, 赵耀.基于DCNN的图像语义分割综述
[J]. 北京交通大学学报, 2016, 40(4):82-91.[本文引用: 1]
Wei Y C, Zhao Y.A review on image semantic segmentation based on DCNN
[J]. Journal of Beijing Jiaotong University, 2016, 40(4):82-91.[本文引用: 1]
Sandler M, Howard A, Zhu M, et al.Mobilenetv2:Inverted residuals and linear bottlenecks
[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018:4510-4520.[本文引用: 1]
Mnih V. Machine learning for aerial image labeling[D]. Toronto: University of Toronto, 2013.[本文引用: 1]
【作者简介】赵凌虎(1998-),男,硕士研究生,研究方向为遥感图像处理。Email: 2919404153@qq.com。
【通讯作者】甘淑(1964-),女,教授,博士生导师,研究方向为摄影测量与遥感技术。Email: gs@kust.edu.cn。
【基金资助】国家自然科学基金项目“滇中星云湖高原湖泊流域聚落空间格局演化研究”(41561083);“东川小江泥石流迹地的多尺度遥感探测试验分析研究”(41861054)
【引用格式】赵凌虎, 袁希平, 甘淑, 胡琳, 丘鸣语. 改进Deeplabv3+的高分辨率遥感影像道路提取模型[J]. 自然资源遥感, 2023, 35(1): 107-114.








