几乎所有的机器学习算法最后都归结为求一个目标函数的极值,即最优化问题,例如对于有监督学习,我们要找到一个最佳的映射函数f (x),使得对训练样本的损失函数最小化(最小化经验风险或结构风险):
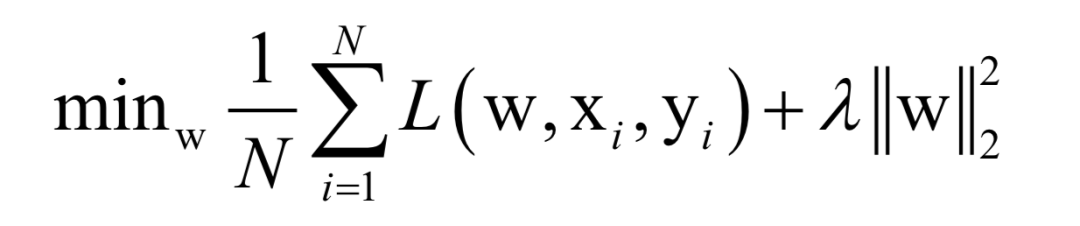
在这里,N为训练样本数,L是对单个样本的损失函数,w是要求解的模型参数,是映射函数的参数,xi为样本的特征向量,yi为样本的标签值。
或是找到一个最优的概率密度函数p(x),使得对训练样本的对数似然函数极大化(最大似然估计):
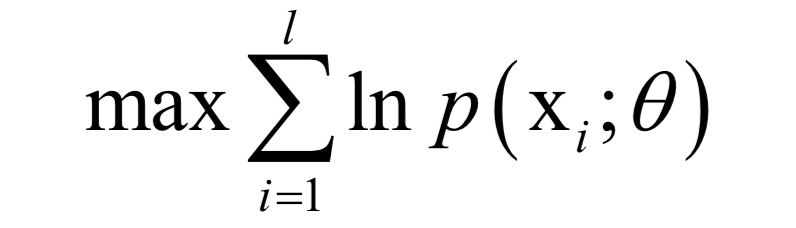
在这里,θ是要求解的模型参数,是概率密度函数的参数。
对于无监督学习,以聚类算法为例,算法要是的每个类的样本离类中心的距离之和最小化:
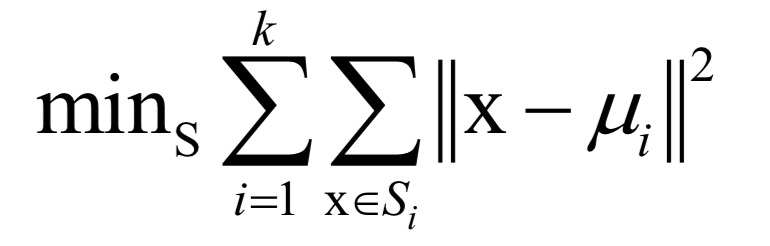
在这里k为类型数,x为样本向量,μi为类中心向量,Si为第i个类的样本集合。
对于强化学习,我们要找到一个最优的策略,即状态s到动作a的映射函数(确定性策略,对于非确定性策略,是执行每个动作的概率):
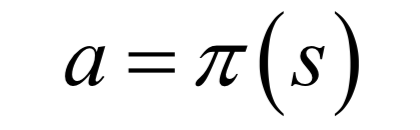
使得任意给定一个状态,执行这个策略函数所确定的动作a之后,得到的累计回报最大化:
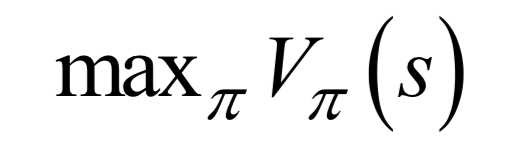
这里使用的是状态价值函数。
总体来看,机器学习的核心目标是给出一个模型(一般是映射函数),然后定义对这个模型好坏的评价函数(目标函数),求解目标函数的极大值或者极小值,以确定模型的参数,从而得到我们想要的模型。在这三个关键步骤中,前两个是机器学习要研究的问题,建立数学模型。第三个问题是纯数学问题,即最优化方法,为本文所讲述的核心。










