分类是机器学习最常见的应用之一。分类技术可预测离散的响应 — 例如,电子邮件是不是垃圾邮件,肿瘤是恶性还是良性的。分类模型可将输入数据划分成不同类别。典型的应用包括医学成像、语音识别和信用评估。选择最合适的分类模型,诊断和纠正过拟合是机器学习的基本技能。那什么是过拟合?我们又可以如何防止和避免过拟合呢?过拟合指当模型与训练数据过于接近贴合,以至于不知道如何对新数据做出响应时发生的一种机器学习行为。过拟合的原因可能是:机器学习模型太过复杂;它记忆了训练数据中非常微妙的的模式,而这些模式无法很好地泛化。训练数据的规模对于模型复杂度来说太小,和/或者包含大量不相关的信息。您可以通过管理模型复杂度和改进训练数据集来防止过拟合。欠拟合与过拟合正相反。欠拟合指模型不能很好地与训练数据贴合,也无法很好地泛化到新数据。在分类模型和回归模型中都可能出现过拟合和欠拟合。下图说明了过拟合的模型的分类决策边界和回归线如何过于紧密地跟随训练数据,而欠拟合的模型的分类决策边界和回归线又如何不够紧密地跟随训练数据。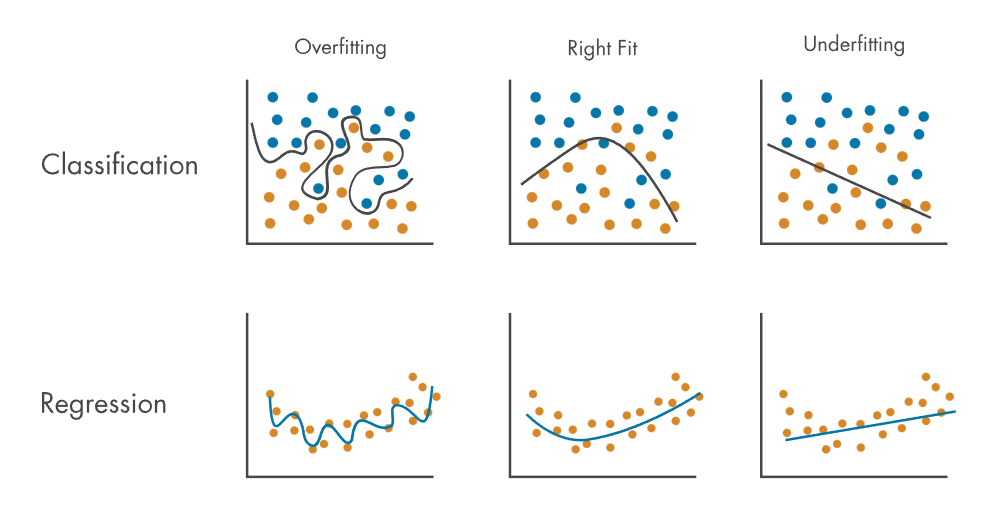
与正确拟合的模型相比,过拟合的分类模型和回归模型对训练数据的记忆太好。当只针对训练数据查看机器学习模型的计算误差时,过拟合比欠拟合更难检测。因此,为了避免过拟合,在对测试数据使用机器学习模型之前对其进行验证就很重要。
针对训练数据,过拟合模型的计算误差低,而测试数据的误差高。
将 MATLAB® 与 Statistics and Machine Learning Toolbox™ 和 Deep Learning Toolbox™ 结合使用,可以防止机器学习模型和深度学习模型的过拟合。MATLAB 提供了专为避免模型过拟合而设计的函数和方法。您可以在训练或调整模型时使用这些工具来防止过拟合。使用 MATLAB,您可以从头开始训练机器学习模型和深度学习模型(如 CNN),或利用预训练的深度学习模型。为了防止过拟合,请执行模型验证,以确保为数据选择具有合适复杂程度的模型,或使用正则化来降低模型的复杂度。当对训练数据进行计算时,过拟合模型的误差较低。因此,在引入新数据之前,最好在单独的数据集(即验证数据集)上验证您的模型。对于 MATLAB 机器学习模型,您可以使用 cvpartition 函数将数据集随机划分为训练集和验证集。对于深度学习模型,您可以在训练过程中监控验证准确度。通过模型选择和超参数调整来提高经过正确验证的模型准确度度量应该能够提高模型处理新数据的准确度。交叉验证是一种模型评估方法,用于评估机器学习算法对新数据集执行预测的性能。交叉验证可以帮助您避免选择过于复杂而导致过拟合的算法。使用 crossval 函数,通过使用常见的交叉验证方法来计算机器学习模型的交叉验证误差估计值。这些常见方法包括如 k 折法(将数据划分为 k 个随机选择的大小大致相等的子集)和留出法(将数据按照指定比率随机划分为两个子集)等。正则化是一种用于防止机器学习模型中的统计过拟合的方法。正则化算法通常通过对复杂度或粗糙度应用罚分来实现。通过向模型中引入更多信息,正则化算法可以使模型更加简约和准确,从而处理多重共线性和冗余预测变量。
对于机器学习,您可以在三种流行的正则化方法之间进行选择:lasso(L1 范数)、脊(L2 范数)和弹性网,以用于几种类型的线性机器学习模型。对于深度学习,您可以在指定的训练选项中增大 L2 正则化因子,或在您的网络中使用丢弃层来避免过拟合。1) 正则化 - https://ww2.mathworks.cn/help/stats/regularization-1.html2) 深度学习提示和窍门 - https://ww2.mathworks.cn/help/deeplearning/ug/deep-learning-tips-and-tricks.html交叉验证和正则化通过管理模型复杂度来防止过拟合。另一种方法是改进数据集。深度学习模型比其他机器学习模型更需要大量的数据来避免过拟合。当数据可用性受限时,可使用数据增强方法来向数据集添加现有数据的随机版本从而人为扩展训练数据集的数据点。使用 MATLAB,您可以增强图像、音频和其他类型的数据。例如,通过随机化现有图像的缩放比例和旋转来增强图像数据。合成数据生成是扩展数据集的另一种方法。使用 MATLAB,您可以使用生成对抗网络 (GAN) 或数字孪生(通过仿真生成数据)来生成合成数据。数据噪声会导致过拟合。减少不想要的数据点的一种常见方法是使用 rmoutliers 函数从数据中删除离群值。1) 使用增强的图像训练网络 - https://ww2.mathworks.cn/help/deeplearning/ref/trainnetwork.html#mw_d13a4922-1dd5-4409-a0fd-fc489c353a9f2) 增强深度学习的点云数据 - https://ww2.mathworks.cn/help/vision/ug/augment-point-cloud-data-for-deep-learning.html3) 使用条件 GAN 生成合成信号 - https://ww2.mathworks.cn/help/deeplearning/ug/generate-synthetic-pump-signals-using-conditional-generative-adversarial-network.html4) 设置参数并训练卷积神经网络 - https://ww2.mathworks.cn/help/deeplearning/ug/setting-up-parameters-and-training-of-a-convnet.html










