今天给大家介绍纽约大学Lu等人在2022年发表的一篇名为“Unified Deep Learning Model for Multitask Reaction Predictions with
Explanation”的文章。有机化学是现代多个学科领域的基石,深刻改变着我们生活的方方面面,因此近代以来科研工作者一直致力于探索开发鲁棒性更好的机器学习模型来辅助有机化学合成。
在这项工作中,作者在自然语言处理(NLP)中的基于文本到文本的迁移Transformer模型 (Text-To-Text Transfer Transformer,
T5)框架的基础上,为多种化学反应预测任务开发了一个统一的深度学习模型:T5Chem。T5Chem模型是基于文本到文本的迁移Transformer模型(T5)开发的,T5模型的基本思想是将大部分NLP问题都抽象成了文本到文本的问题,即将文本作为输入并生成新的文本作为输出,这允许将相同的模型、目标、训练步骤和解码过程,直接应用于每个任务。具体模型结构如图1所示,T5采用Transformer的编码器-解码器结构,并保留原始Transformer模型中的自注意力机制,但使用相对位置嵌入取代Transformer模型本身基于正余弦函数的位置嵌入。此外,如果要模型执行特定任务,在原始输入序列前添加特定任务的提示符后再输入模型。因此在T5Chem模型词汇表中,还需要包括用于不同反应预测任务的提示符。主要包括: Product:反应产物预测,Reactants:单步反合成,reagent:反应试剂预测,Classification:反应类型预测,Yield:反应产率预测。根据不同下游预测任务,作者将原始T5模型输出层修改为三种类型:1.在如反应正向预测、单步逆合成预测和反应试剂预测的翻译问题中,输入和输出序列共享词汇表,输出层(即分子生成头)和输入嵌入层共享权值并在整个词汇空间中产生概率分布;2.在如反应类型预测的分类问题中,分类头会输出所有分类类别之间的概率分布;3.在如反应产率预测的回归问题中,采用最小-最大归一化训练标签的软标签策略,使用Kullback-Leibler散度作为损失函数最小化回归任务中输出与真标签之间的概率分布。
T5Chem模型使用PubChem数据库中9700万个分子作为预训练数据集,与T5模型类似,在预训练过程中,对源序列的词汇进行随机掩码,即随机丢弃输入序列中15%的标记,掩码标记80%几率被替换为屏蔽标记(),10%几率被替换为词汇表中的另一个随机词汇,10%几率保持不变。然后,该模型将在有监督的下游任务中进行微调。在微调期间,各种特定于任务的提示符和输出层将用于不同的输出类别,如图2所示。
T5Chem基于python 3.7实现,使用Pytorch 1.7.0和hugging-face Transformer进行模型搭建,使用RDkit(2021.03.1)处理反应和SMILES字符串,源码可在https://github.com/HelloJocelynLu/t5chem在线获得。
为了更好地与其他类似工作进行比较,作者使用其他工作中使用的四个开源数据集进行模型训练。此外,作者引入了一个新的反应数据集USPTO_500_MT,用于多任务处理。数据集具体信息如表1所示,主要包括用于正向反应预测的USPTO_MIT,用于单步逆合成预测的USPTO_50K,用于反应类型预测的USTPO_TPL,用于反应产率预测的C-N耦合数据集,用于多任务反应预测的USPTO_500_MT。
T5Chem模型使用掩码语言建模(MLM)目标对9700万个PubChem分子进行预训练。经过预训练的模型表现出稳定的学习曲线和更快的收敛速度,该模型作为初始模型用于后续的微调任务。
任务1:预测反应类型
作者使用USPTO TPL数据集训练T5Chem模型,在训练100 epoch后,测试结果如表2所示,模型准确性达到99.5%,远超Schwaller等人的Bert分类器模型。此外,马修斯相关系数 (MCC,Matthews
Correlation Coefficient)评价指标和混淆熵 (CEN,Confusion
Entropy)也是多类问题上的分类器常用评价指标。CEN值越小或MCC值越大,模型效果就越好。
任务2:正向反应预测
T5Chem模型在USPTO_MIT数据集上进行了30个epoch的训练,并与以前的正向预测模型进行比较,具体结果如表3所示。Seq2seq是第一个基于注意力的序列对序列模型,它将化合物分子视为字符串。WLDN是基于图卷积神经网络的反应正向预测模型。这两种模型都只在反应物-试剂分离的情况下进行评估。相比于其他模型,T5Chem模型具有最高的准确度。
任务3:单步逆合成预测
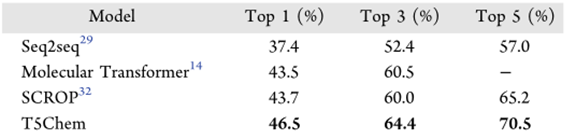
在单步逆合成预测任务中,作者使用和正向反应预测相同的模型架构。在没有给定反应类型的情况下,在USPTO-50k上训练了100个epoch,并将测试结果与之前基于相同训练数据的单步逆合成预测模型进行比较,结果如表4所示。其中,Seq2seq模型基于长短期注意力机制,Molecular Transformer模型是完全基于自我注意力机制,SCROP是将基于Transformer模型的逆合成反应模型与基于神经网络的语法校正器相结合。从结果对比可知,T5Chem在单步逆合成预测任务中表现出最好的准确性。
任务4:反应产率预测
将训练数据集按照Sandfort和Schwaller等人的方法进行分割,在训练T5Chem模型100个epoch后,结果如表5所示。总的来说,T5Chem模型在列出的预测反应产率的方法中表现最好。对于随机划分的测试集,T5Chem的回归系数R2达到0.970,对于更具挑战性的样本外测试集,除测试集1外,T5Chem模型均获得最佳结果。
表5 反应产率预测结果
任务5:多任务预测
在验证T5Chem模型能够在单个任务中实现与其他基于序列的模型相当或更好的性能后,作者使用新准备的USPTO_500_MT数据集进行了多任务实验,以证明T5Chem模型的多任务处理能力和可迁移性。USPTO_500_MT包含五个目标:正向反应预测、单步逆合成预测、反应试剂预测、反应类型预测和反应产率预测。这五项任务被分成两组。第一组包括正向反应预测、单步逆合成预测和反应试剂预测,因为这三个任务都是基于序列对序列框架,可以共享相同的模型结构。第二组包括反应分类和反应产率预测,这两个任务都以整个反应序列作为输入,作者将它们的损失函数结合在一起,同时对这两个任务进行训练。
对于第一组的序列到序列任务,作者将三个任务的训练集打乱混合,为了区分不同的任务,使用“Product”、“Reactants”、“Reagents”作为任务的特定提示符。如图3所示。
在这个实验中,作者只使用混合数据集训练了一个模型,然后在来自不同任务的三个测试集上分别测试它,并将结果与前面提及的在不同数据集上训练和测试的单个模型进行比较,具体结果如图4所示,T5Chem模型在正向预测、逆向合成和试剂预测方面分别达到了97.5%、72.9%和24.9%的最高准确率。就top-k准确性而言,它与单独任务模型在准确性结果上相当。这表明这三项任务密切相关,可以同时学习。并且使用混合数据集训练得到的T5Chem模型预测得到的无效SMILES较少。
对于第二组任务,即反应类型预测和产率预测,作者首先训练了一个单独的反应类型分类模型,后将T5Chem的输出分类层用反应产率预测的回归层替代,结果表明,该迁移学习模型在产量预测方面比直接训练获得了更好的性能。此外,作者将这两个任务结合在一起,训练了一个组合模型。在训练期间,通过计算单个任务的损失总和,并根据验证集损失值选择最佳模型参数和权重。组合模型的反应类型分类准确率为99.4%,R2为0.22,平均相对误差为17.8。其结果与单独训练的结果相当。
表6 T5Chem模型在USPTO_500_MT数据集上各任务的训练结果SHAP(Shapley Additive exPlanations)是通过博弈论方法解释机器学习模型,利用最优的Shapley
value来解释个体预测的方法。作者根据SHAP值对每个任务的输入词汇进行着色。以图5中USPTO_500_MT测试集中的一个反应为例,蓝色代表该特征对预测有负向影响,红色代表该特征对预测有正向影响。在反应正向预测、单步逆合成预测及反应试剂预测任务中,除了硝基、氨基贡献较大外,芳环在以上三个任务中也表现出很强的贡献,作者分析认为,即使芳环不参加反应,但是仍会使得烷基和芳基硝基化合物处于不同的化学环境中,表明T5Chem模型可以关注化合物的子结构。在正向预测任务中,催化剂Pt也对产物有积极的贡献,在逆合成预测中,氯和烷基侧链也表现出正向贡献,表明该化合物也可以通过氯化或者醚化反应来合成,但可能性较低。
在反应产率的预测任务中,SHAP值表明芳基卤化物、添加剂和催化剂的选择对所有产率预测贡献最大。其中4-氯甲氧基苯对反应产率预测起着最重要的作用。并且苯环和氯取代有很强的负向影响。事实上,当4-氯甲氧基苯作为一种反应物时平均反应产率会比总平均产率低30%。此外,也可通过SHAP值剖析优化反应,作者选择了两个反应产率不同的反应,如图6B所示。这两个反应只是反应物A不同。作者通过将反应物A中4-氯甲氧基苯中的苯和氯这类负影响子结构,改为积极贡献的2-碘吡啶中的碘和吡啶环,会获得更高的反应产率。
图6 使用SHAP可视化优化反应产率预测任务
在这项工作中,作者提出一个可解释和统一的Transformer模型(T5Chem)。该模型可用于与有机化学合成相关的多种机器学习任务,并在四个不同的开源数据集上验证了其在不同预测任务上的性能。此外,作者引入新的数据集USPTO_500_MT 用于化学反应的多任务机器学习,包括正向反应预测、单步逆合成反应预测、反应试剂预测、反应类型预测分类(500种)和反应产率预测。结果表明,使用多任务训练的T5Chem模型具有更强的鲁棒性,可以从相关任务的互相学习中受益。最后,作者使用SHAP工具在官能团水平上对T5Chem模型的预测结果进行解释,这为将T5Chem模型发展成一个广泛适用和多功能的机器学习框架奠定了基础。
参考文献
[1] Lu, J. and Y. Zhang, Unified Deep Learning Model for Multitask Reaction Predictions with Explanation. Journal of Chemical Information and Modeling, 2022. 62(6): p. 1376-1387.
供稿:张红文
校稿:张梦婷/胡建国
编辑:毛丽韫
华东理工大学/上海市新药设计重点实验室/李洪林教授课题组
感兴趣的读者,可以添加小邦微信(zhiyaobang2020)加入读者实名讨论微信群。添加时请主动注明姓名-企业-职位/岗位 或
姓名-学校-职务/研究方向。












