
前言:封面图片是基于机器生成的,我的prompt是“写代码,程序员”。大概三年前体验过类似的工作,效果远不达预期。最近一段时间里的工作,笔者个人觉得非常赞。怎么商业化?比如文章封面图生成。
从二零一三年六月六日正式加入Github至今大概十年,其中从二零一六年至今,Github几乎成了笔者每天都要浏览的网站之一。至今有followers,共644个,有3个项目进入了2020 Github Archive Program,也就是这些代码会在斯瓦尔巴北极山脉深处的一个废弃煤矿中,存放1000年,颇有些赛博朋克。接下来,讲述一些关于Github中项目背后的故事。下图是一个Pinned的项目列表: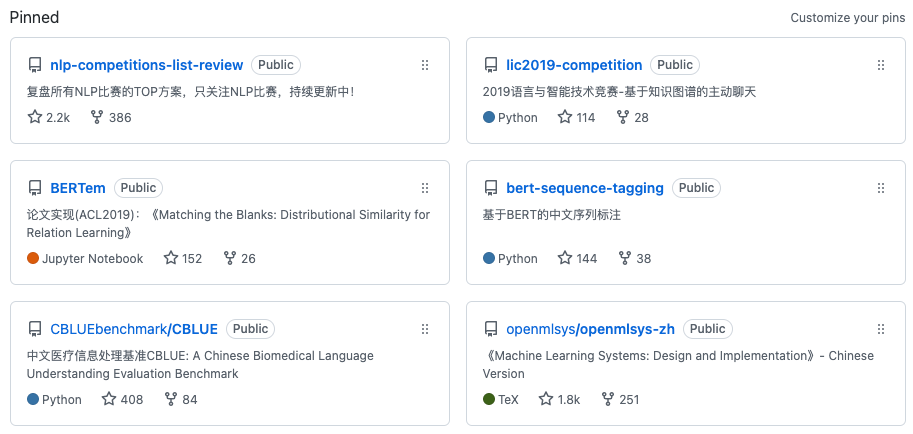 nlp-competitions-list-review,star=2200,fork=386。该项目至今已经维护近6年。主要目标是复盘所有中文NLP比赛的TOP方案。在大概6年前,在github建立了一个organization:江南大学数据竞赛团队。那时还是一个表格竞赛满天飞的年代,恰巧团队中有做NLP和视觉的同学,于是首先建立了NLP的repo,之后团队中的一个师弟建立了CV的repo。可能是由于有这个想法比较早,之后在github上出现了很多类似的repo,这个repo也被很多大V和相关repo引用,因此star和fork数一路涨到现在。这个repo算是在早期,对NLP社区还算有帮助,甚至我们一度认为,引领了今天许多类似repo的建立和分享。
nlp-competitions-list-review,star=2200,fork=386。该项目至今已经维护近6年。主要目标是复盘所有中文NLP比赛的TOP方案。在大概6年前,在github建立了一个organization:江南大学数据竞赛团队。那时还是一个表格竞赛满天飞的年代,恰巧团队中有做NLP和视觉的同学,于是首先建立了NLP的repo,之后团队中的一个师弟建立了CV的repo。可能是由于有这个想法比较早,之后在github上出现了很多类似的repo,这个repo也被很多大V和相关repo引用,因此star和fork数一路涨到现在。这个repo算是在早期,对NLP社区还算有帮助,甚至我们一度认为,引领了今天许多类似repo的建立和分享。
bert-sequence-tagging,star=144,fork=38。这个项目虽然整体star和fork不算多,但是于笔者而言还是很有意义的。bert的工作大概在2018年的下半年的某个时间放出了paper,那个时候刚刚结束实习回校不久,闲来无事,大概在paper放出来之后的第三天,share了这个repo。其实想法很简单,就是实习做的中文纠错,主要采用序列标注的方案做的,但是bert这么强的工作,虽然开源了代码,但是代码中唯独没有序列标注的实现,于是就顺手实现了基于bert的序列标注。之后,很多开源工作放出来,也会挂上这个repo的地址。在之后的很多时间,笔者做了很多围绕bert的工作,这个工作其实是起点。
BERTem,star=152,fork=26。这个工作是第一次做信息抽取时实现的一篇paper的一个比较有意义的Trick。虽然这个工作其实是某个Few-Shot Learning榜单上当时的SOTA,但是其实非常适合做信息抽取中的关系分类。整体的思想非常简单,就是通过在实体两侧添加Marker,强化模型对于实体表征的学习。至今天,该技巧在关系抽取中已经用的非常普遍,基本成为一个事实上的标准。
在某次面试中,还对着Github深挖了实现的核心代码,并没有几行。也许放出这个repo的时候,这篇paper的源码还没有release吧,所以还算是对社区有帮助。
cged_tf是和上述工作类似的工作。实习期做的中文纠错工作是从cged开始的,首先需要复现SOTA的结果。虽然SOTA放出了源代码,但是简直一坨shi。面对代码没有架构,基于一个极其小众的框架开发,勉强能运行起来等问题,索性重新实现SOTA的工作。那是第一次使用tensorflow,至今笔者个人都没有再使用过tensorflow。虽然最终复现了结果,但是整个实现过程非常的不开心,一个新的框架,一坨shi一样的代码,一个还不错的结果。但是后续基于这个repo继续工作的同学,应该在使用体验上还可以。
VisDrone2018,star=88,fork=36。这个工作是整个repo中唯一保留的与CV相关的工作了。大概在2018年参加的一个目标检测的工作。给定无人机拍摄的照片,识别照片中的人物,车辆,船只等物体。那个时候还是Faster-RCNN的年代,比赛的结果还算不错。后续又有做CV的同学基于这个repo做了一些其他的工作,还算比较有成就感,不过笔者之后基本就不再做CV的问题了。现在想一想,做CV还是比较有意思的,对不对?
tianchi-ruijin(瑞金医院-知识图谱构建)和kaggle-quora-insincere-question-classification(问题分类),以及lic2019-competition(基于知识图谱的主动聊天),都是比赛baseline,纯属拼手速的工作。在当时如果你能够赶在其他竞赛者放出baseline之前放出自己的baseline,就可以收获不错的star和fork数。然而在今天,似乎这样做就很难了,也许这就是红利期的一个代表场景了。
zhpmatrix.github.io,PaperReading, openmlsys-zh和CBLUE四个都不是代码类的项目,zhpmatrix.github.io是笔者写了6年的,共计约120篇的个人博客,现阶段写文章都会在公众号上。PaperReading是笔者个人的读的论文的三句话笔记,没想到竟然有102个star。openmlsys-zh是一本开源机器学习关于系统方向的书,参与了一个typo fix这种非常小的贡献。CBLUE则是一个医疗NLP的榜单,fix了一个代码中的关键bug。
还有其他一些有意思的项目,这里就不再一一陈述。欢迎关注笔者个人的github:https://github.com/zhpmatrix?tab=repositories
回看github,尚存在一些虽然不再维护,但是也不会删除的内容。比如:
 今天这个organization的小伙伴分别散落在各个厂里,正在继续深耕NLP的方向。
今天这个organization的小伙伴分别散落在各个厂里,正在继续深耕NLP的方向。
 那个时候,从数据挖掘到自然语言处理,再到计算机视觉,还有一些语音类的比赛。三年时间太短,但是记忆会一直保存。
那个时候,从数据挖掘到自然语言处理,再到计算机视觉,还有一些语音类的比赛。三年时间太短,但是记忆会一直保存。
至今,Github已经具备了一个类似朋友圈的功能,每天会打开看一下自己following的人正在做的工作,star了哪个项目?
fork了什么repo?push了哪些代码?时刻能够看到他们一直在的感觉,非常好。
进技术交流群请添加AINLP小助手微信(id: ainlp2)
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP小助手微信(id:ainlp2),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏








